
ECCV 2020 | COCO 视觉挑战赛揭榜,人体关键点检测赛道冠军技术干货分享
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

COCO (Common Objects in Context) 数据集是由微软研究院提出的大规模计算机视觉数据集,致力于对常见视觉任务(包括目标检测、实例分割、人体关键点检测、全景分割等)进行分析与评测。与之前的 PASCAL VOC、ImageNet 数据集不同的是,COCO 数据集场景更加复杂、任务更加丰富、更接近实际应用。
基于 COCO 数据集,Facebook 人工智能研究院、谷歌研究院、加州理工学院等联合在每年的 ICCV 或 ECCV 会议上组织举办 COCO 系列视觉挑战赛。历年的 COCO 挑战赛是人工智能领域最具影响力的图像(物体)识别挑战赛,也代表了继 ImageNet 后图像(物体)识别的较高水平,在学术界和工业界具有很高的认可度和知名度。国内外知名的人工智能企业和科研机构如谷歌、Facebook、微软、清华大学、北京大学、商汤科技、旷视科技等均组队参加过历届 COCO 系列比赛。

今年的 COCO 比赛由 ECCV 2020 会议的 COCO-LVIS Joint Workshop 举办,共包括目标检测 / 实例分割、人体关键点检测、全景分割等赛道。芯翌科技(XForwardAI)算法团队此次参加了前两个赛道。在人体关键点检测赛道,芯翌科技获得了冠军,此次成绩在 test-dev 测评集上 AP 指标为 80.8%,相比较去年冠军方案(AP 指标为 79.2%)有了重大提升;在最终的 test-challenge 测评集上 AP 指标为 77.4%,刷新了该赛道的历史最好成绩。在目标检测 / 实例分割赛道,芯翌科技也取得了排名前列的成绩。
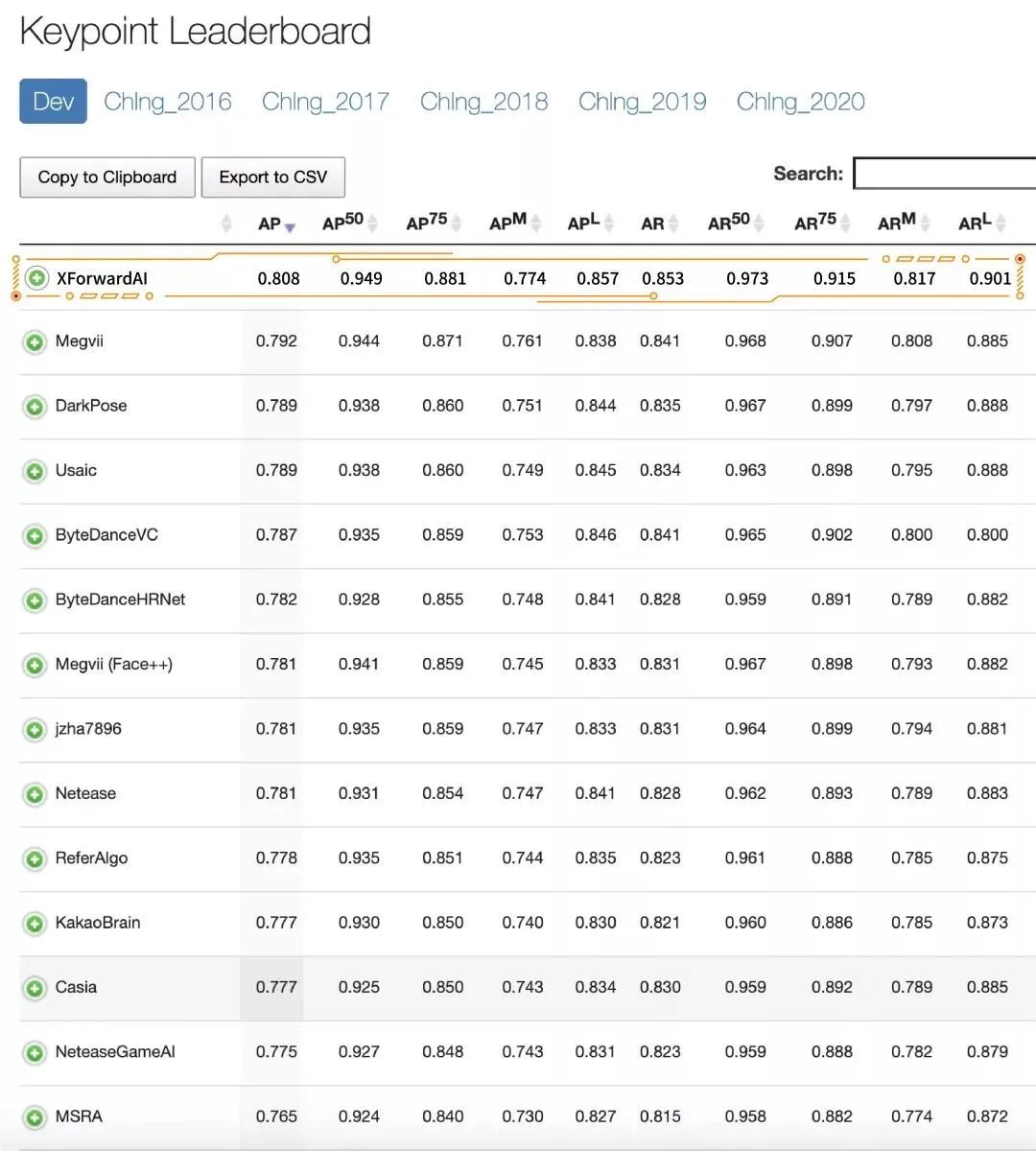
在人体关键点检测赛道,芯翌科技名列前茅
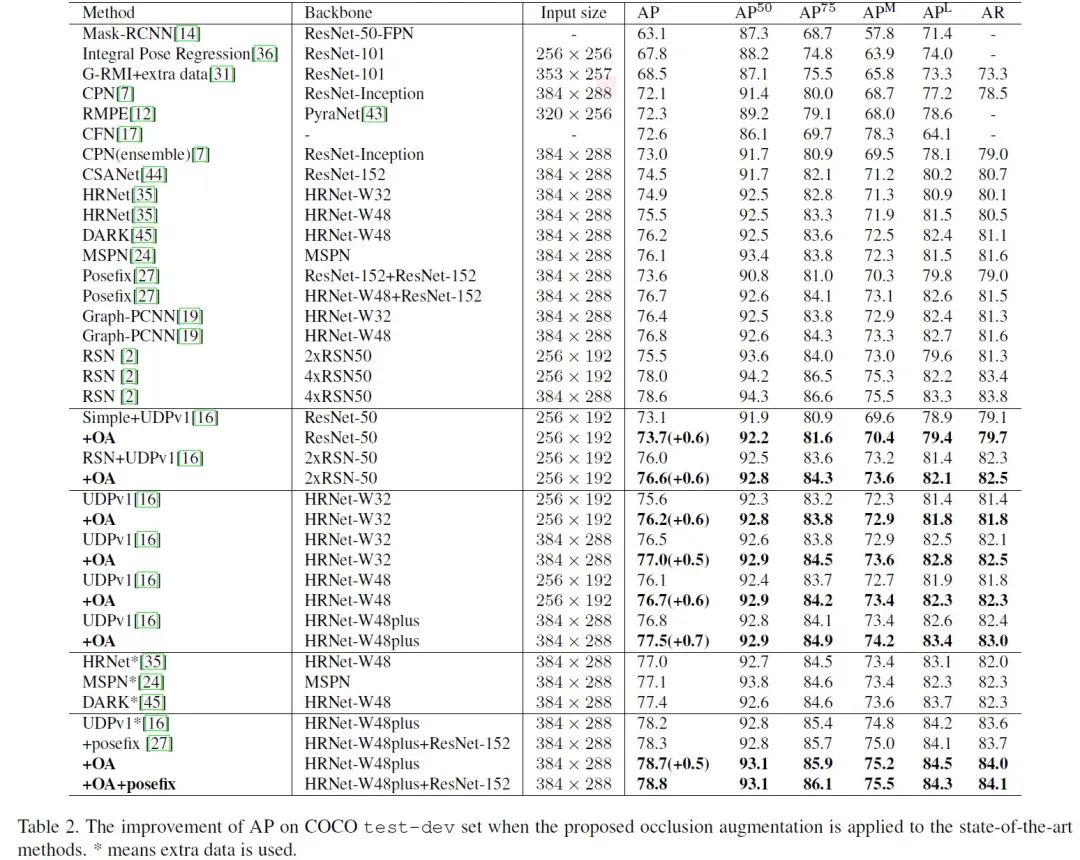
芯翌科技算法团队在此次夺冠中使用了多项原创性技术创新,包括面向通用目标定位的无偏数据处理算法(UDP,论文已被CVPR2020录用),以及让网络更加关注约束信息的监督算法等。

论文地址:https://arxiv.org/abs/1911.07524
代码地址:https://github.com/HuangJunJie2017/UDP-Pose

如上图所示,人体姿态估计任务中的数据处理主要包含两个环节:数据在不同坐标轴之间的变换和关键点坐标的编码解码。基于此,人体姿态估计任务中数据处理流可以用以下公式进行建模:
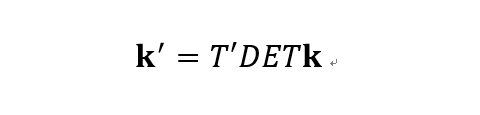
而无偏的数据处理则需要满足数据流的输入与输出严格相同,即:
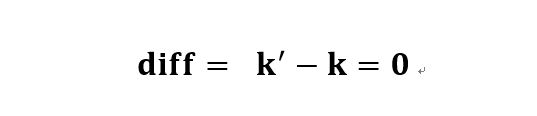
由于评测会对偏差直接作出惩罚,无偏的数据处理对于高精度的人体姿态估计极为重要。此外,潜藏在数据流中的偏差会对研究造成严重的干扰,无偏的数据流是可靠 codebase 必不可少的特征。
芯翌科技的研究人员通过对现有的 codebase 进行推理分析,发现现有 SOTA 工作的数据处理中普遍存在偏差,这些偏差存在于上述两个环节中并相互耦合。一方面直接影响了算法的性能表现,另外一方面为后续的研究埋下了难以察觉的隐患。基于严格的数学推理,研究人员提出用于人体姿态估计无偏的数据处理流作为解决方案,在大幅度提升现有工作的性能表现的同时,为后续研究提供可靠的基础。

论文地址:https://arxiv.org/abs/2008.07139
在提出UDP解决数据处理有偏的问题之后,芯翌科技的研究人员又对人体姿态估计的性能瓶颈进行分析。近几年来网络结构的改进是研究的重点,涌现了 SimpleBaseline, MSPN, HRNet, RSN 等一系列具有代表性的工作。而监督方面则一直沿用着位于关键点处的高斯响应图作为监督,此监督设计直观,其有效性已被广泛证明。然而这种看似完美的监督是否存在缺点呢?答案是肯定的。
研究人员指出人类在定位图像中的人体关键点时使用了两种信息,外观信息和约束信息。外观信息是定位关键点的基础,而约束信息则在定位困难关键点时具有重要的指导意义。约束信息主要包含人体关键点之间固有的相互约束关系以及人体和环境交互形成的约束关系。直观上看,约束信息相比外观信息而言更复杂多样,对于网络而言学习难度更大,这会使得在外观信息充分的情况下,存在约束条件被忽视的可能。研究人员基于此假设,引入信息丢弃的正则化手段,通过在训练过程中以一定的概率丢弃关键点的外观信息,以此避免训练过程过拟合外观信息而忽视约束信息。

各种信息丢弃方法
虽然随机丢弃外观信息可以避免训练过程过拟合外观信息,但是由于外观信息是视觉定位人体关键点的基础,外观信息的缺乏会使得训练前期收敛较慢,网络需要一个更长训练周期才能达到完全收敛。
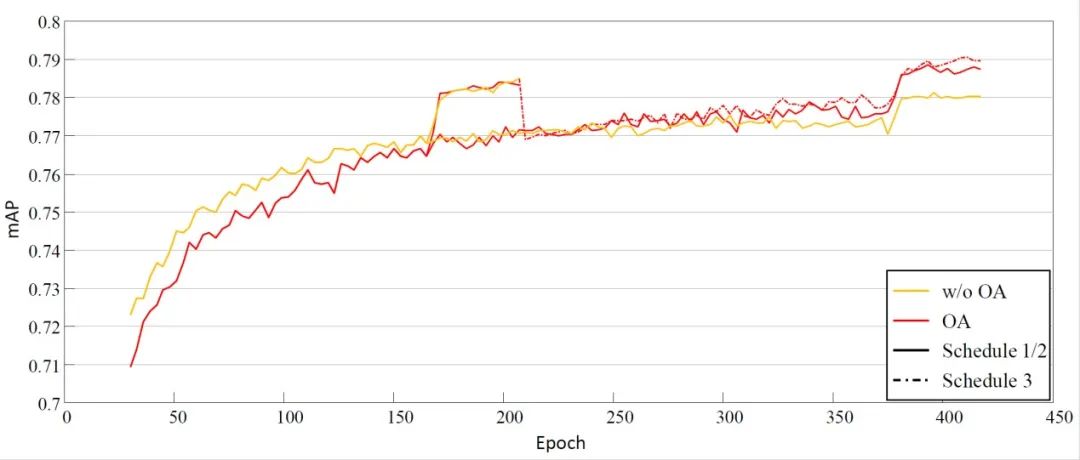
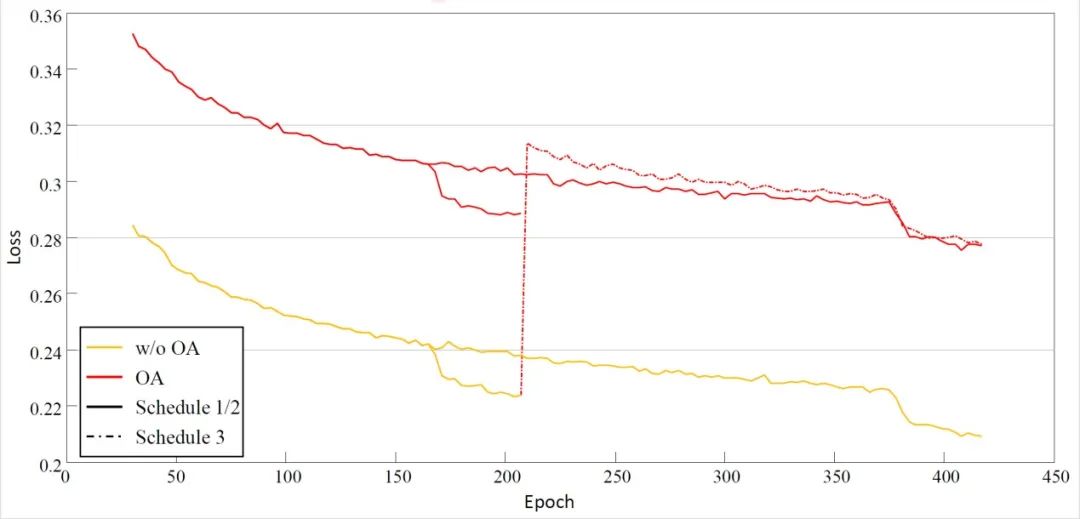
在实验中,研究人员通过使用多种基线验证了上述假设的合理性以及所提出方法的有效性。有趣的是,在不同的 baseline 上所提出的方法表现惊人的一致,这个一方面反映了这种过拟合外观信息的问题是广泛存在的,修改网络,增加数据并不能解决这个问题。另外一个方面也验证信息丢弃可以有效遏制这个问题。
下图中研究人员可视化了一些网络预测的结果,和标注结果以及没有使用信息丢弃增广时得到的结果进行比较。在外观信息缺乏或者外观信息具有迷惑性的场景中,约束信息显得尤为重要,而使用信息丢弃增广训练得到的模型,在这些情况下对关键点的定位更准确、合理。
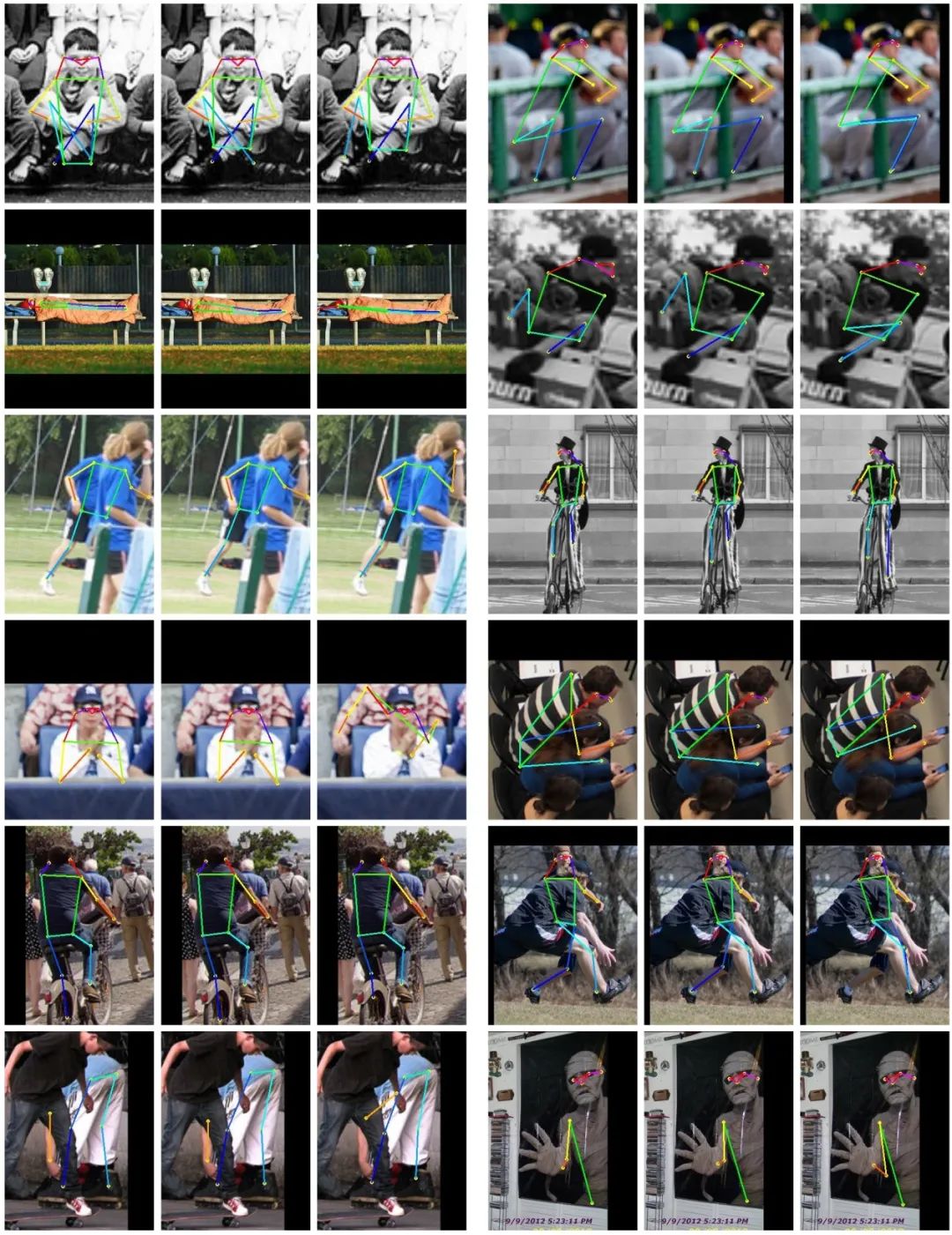
结果可视化,从左到右分别是:标注结果、使用信息丢弃增广后的结果和没有使用信息丢弃增广的结果
成绩的背后
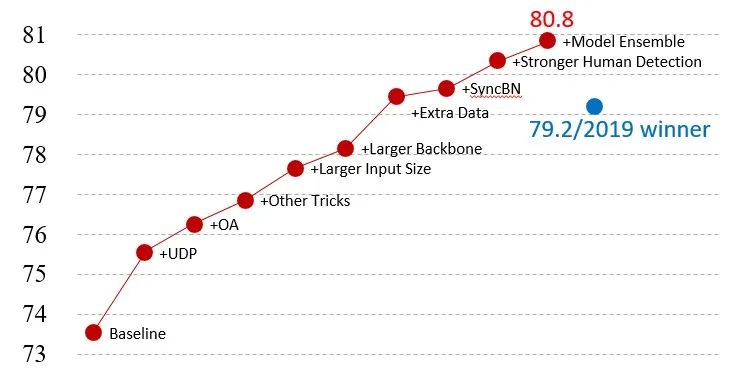
2020COCO Keypoint Challenge XForwardAI Road Map
芯翌科技的研究人员首先通过大量的技术创新把HRNet-W32-256x192配置的得分提升到76.8AP。由于改进不针对网络结构,后续的增大网络容量和输入分辨率,以及增加训练数据等一系列常规操作均可带来稳定的提升。
此外因为沿用top-down的方法(先检测人,然后对每个instance进行关键点定位),人体检测的效果对最后人体姿态估计指标的影响接近线性。在通用目标检测赛道上,芯翌科技最终得分接近60AP(bbox/test-dev),该人体检测结果可为人体关键点检测提供一定程度的优势。
最后研究人员融合了多个关键点检测模型的结果,在test-dev上达到80.8AP,以绝对优势位列第一。在test-challenge上得分为77.4AP,刷新了该赛道上的历史最高成绩的同时夺得该赛道的冠军。
芯翌科技的研究人员针对人体姿态估计问题提出了无偏的数据处理方法以及信息丢弃的正则化方法,在CodeBase的可靠性以及算法的鲁棒性两个方面作出突破。凭借深厚的技术积累和前瞻的技术创新,以及完善高效的人工智能算法基础设施,芯翌科技在COCO挑战赛的人体姿态估计赛道上成功夺冠。
未来,芯翌科技将不断保持算法创新,追求极致,不断加深和拓宽人工智能技术深度和广度,同时不断沉淀算法的工厂化能力,加快技术产品转化,不断发挥人工智能的价值。
作者介绍:
黄骏杰,芯翌科技算法工程师,人体姿态估计专家,2020 CVPR 论文一作,2020年 COCO Challenge 人体关键点检测赛道冠军。专注于人体姿态识别,人脸识别等领域的研究和应用。
黄冠,芯翌科技算法研发总监,算法团队负责人。拥有近十年的深度学习、计算机视觉、自然语言处理相关经验,是国内最早开展深度学习用于目标检测、分割、关键点的一批人。多次带领团队获得NIST-FRVT、COCO等国际知名人工智能比赛优异成绩,在人工智能顶级会议和期刊上发表多篇论文,带领算法团队支撑了多个大规模智慧城市和复杂工业场景的业务落地,拥有丰富的学术研究和工业界产业落地研发经验。