来源:DeepBlueAI
编辑:白峰
【新智元导读】近日,全球计算机视觉顶会ECCV2020落下帷幕,各个workshop也公布了各项挑战赛的结果,来自中国的DeepBlueAI 团队斩获了第一届GigaVision挑战赛两个赛道的冠军。
来自中国的 DeepBlueAI 团队斩获了「行人和车辆检测」和「多目标追踪」两个赛道的冠军。
以人为中心的各项计算机视觉分析任务,例如行人检测,跟踪,动作识别,异常检测,属性识别等,在过去的十年中引起了人们的极大兴趣。为了对大规模时空范围内具有高清细节的人群活动进行跨越长时间、长距离分析,清华大学智能成像实验室推出一个新的十亿像素视频数据集:PANDA。该数据集是在多种自然场景中收集,旨在为社区贡献一个标准化的评测基准,以研究新的算法来理解大规模现实世界场景中复杂的人群活动及社交行为。围绕PANDA数据集,主办方组织了GigaVision 2020挑战赛。
本次的挑战赛同时是ECCV2020的Workshop:「GigaVision: When Gigapixel Videography Meets Computer Vision」。挑战赛的任务是在由十亿像素相机收集的大范围自然场景视觉数据集PANDA上进行图像目标检测和视频多目标跟踪。
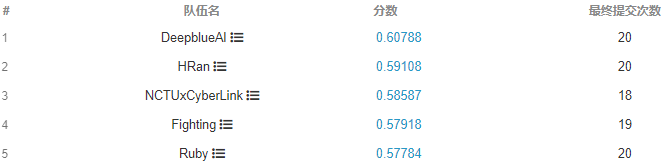
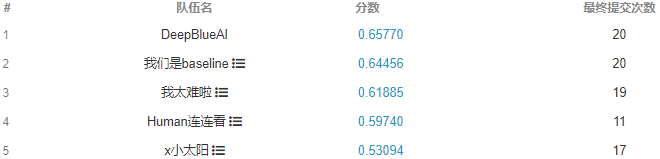
Sub-Track 1 : Pedestrian & Vehicle Detection这项任务是为了推动在十亿像素图像上的目标检测技术的发展。挑战的参与者需要检测两类目标:行人和车辆。对于每个行人,需要提交三类检测框:可见身体范围框、全身范围框、行人头部范围框。对于每个车辆,需要提交可见范围框。一些特殊的区域(如假人、极度拥挤的人群、车群、被严重遮挡的人等)将在评估中被忽略。Sub-Track 2 : Multi-Pedestrian Tracking这项任务是为了推动在十亿像素视频上的多目标追踪技术的发展。PANDA宽视场、多目标、高分辨的优越性能使特别适合于多目标长时间追踪任务。然而,巨大的同类目标尺度变化和拥有丰富行人拥挤、遮挡的复杂场景也带来了各种挑战。在给定输入视频序列的情况下,该任务需要参与者提交行人在视频中的轨迹。对于赛道一,类似于MS COCO数据集的评估方案,主办方采用AP、APIOU=0.50、APIOU=0.75、ARmax=10、ARmax=100、ARmax=500五个指标来评估检测算法的结果。最终的排名依据于 AP 和 ARmax=500 两项指标的调和平均数,高者为优。对于赛道二,与MOTChallenge[2]中使用的评测方法类似,主办方采用了包括MOTA、MOTP、IDF1、FAR、MT和Hz等指标来评估多目标追踪算法的结果。最终的排名依据于 MOTA 和 MOTP 两项指标的调和平均数,高者为优。十亿像素级的超高分辨率是整个数据集的核心问题。一方面,由于计算资源的限制,超高分辨率使得网络无法接受大图作为输入,而单纯将原图缩放到小图会使得目标丢失大量信息。另一方面,图像中近景和远景的目标尺度差异大,给检测器带来了巨大的挑战。数据集均从广场、学校、商圈等真实场景采集,其人流和车辆密度极大。同时,行人和车辆的拥挤、遮挡等情况频发,容易造成目标的漏检和误检。赛道一 Pedestrian & Vehicle Detection
根据以往积累的经验,团队首先将原图缩放到合适尺度,并使用基于Cascade RCNN的检测器直接检测行人的三个类别和车辆,将其作为Baseline: Backbone + DCN + FPN + Cascade RCNN,并在此基础上进行改进。实验结果显示,模型存在大量的误检和漏检。这些漏检和无意义的检测结果大幅降低了模型的性能。团队将上述问题归纳为两方面的原因:- 训练和测试时输入模型的图像尺度不合适。图像经过缩放后,目标的尺度也随之变小,导致远景中人的头部等区域被大量遗漏。
- 网络本身的分类能力较弱。行人的可见区域和全身区域十分相似,容易对分类器造成混淆,从而产生误检。
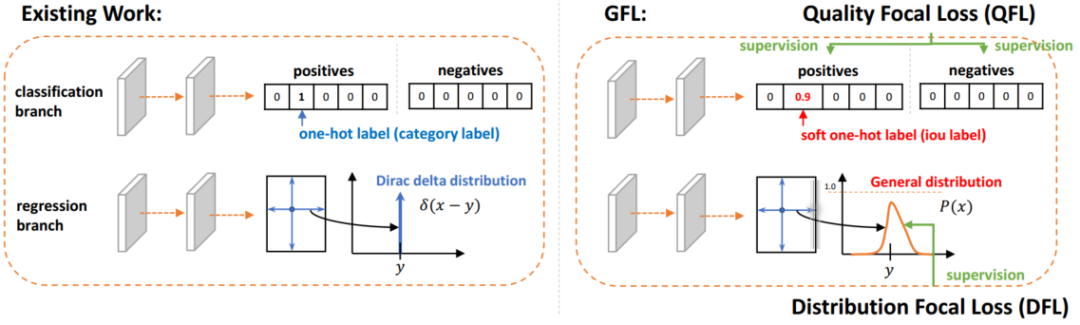
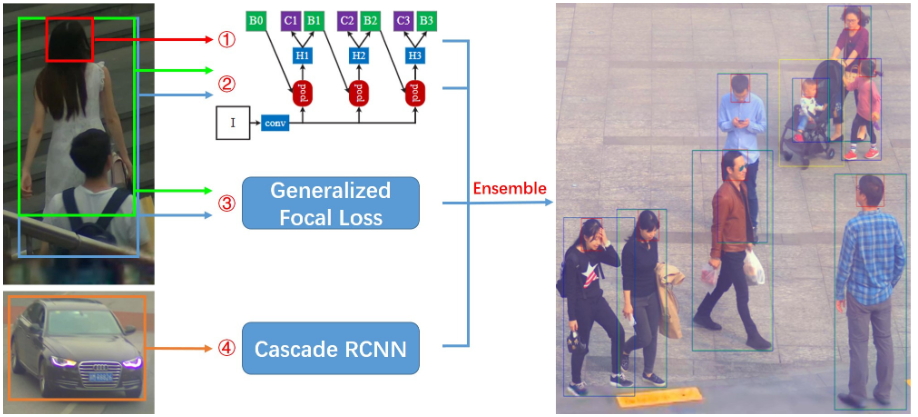
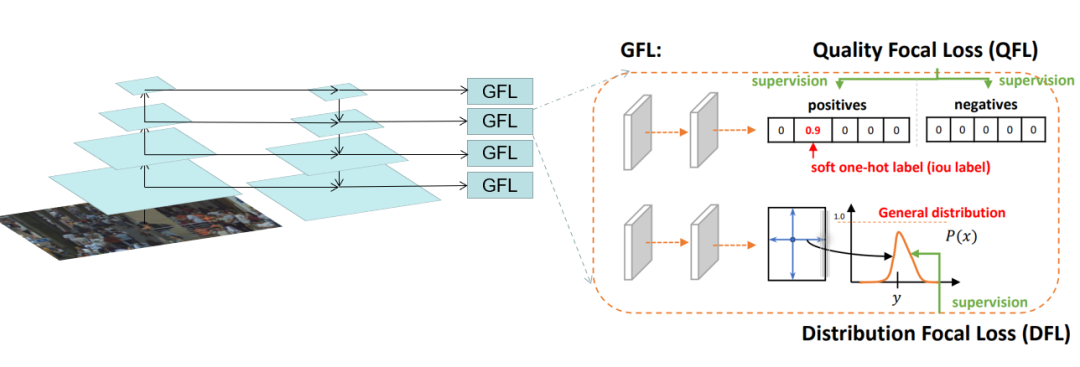
首先,使用滑动窗口的方式切图进行训练。滑动窗口切图是一种常用的大图像处理方式,这样可以有效的保留图像的高分辨率信息,使得网络获得的信息更加丰富。如果某个目标处于切图边界,根据其IOF大于0.5来决定是否保留。其次,对于每个类别采用一个单独的检测器进行检测。经过实验对比,对每个类别采用单独的检测器可以有效的提高网络的效果,尤其是对于可见区域和全身区域两类。同时向检测器添加了Global Context (GC) block来进一步提高特征提取能力。GC-Block结合了Non-local的上下文建模能力,并继承了SE-Net节省计算量的优点,可以有效的对目标的上下文进行建模。除Cascade RCNN外,还采用了Generalize Focal Loss (GFL)检测器进行结果互补。GFL提出了一种泛化的Focal Loss损失,解决了分类得分和质量预测得分在训练和测试时的不一致问题。最后,将各检测器的结果使用Weighted Box Fusion (WBF)进行融合,形成了最终的解决方案。传统的NMS和Soft-NMS方法会移除预测结果中的一部分预测框,而WBF使用全部的预测框,通过进行组合来获得更加准确的预测框,从而实现精度提升。整体pipeline如下图所示:赛道二 Multi-Pedestrian Tracking
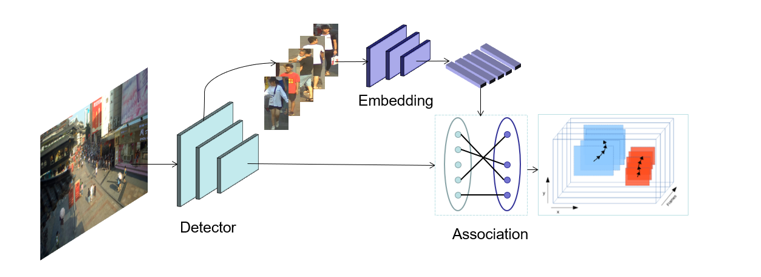
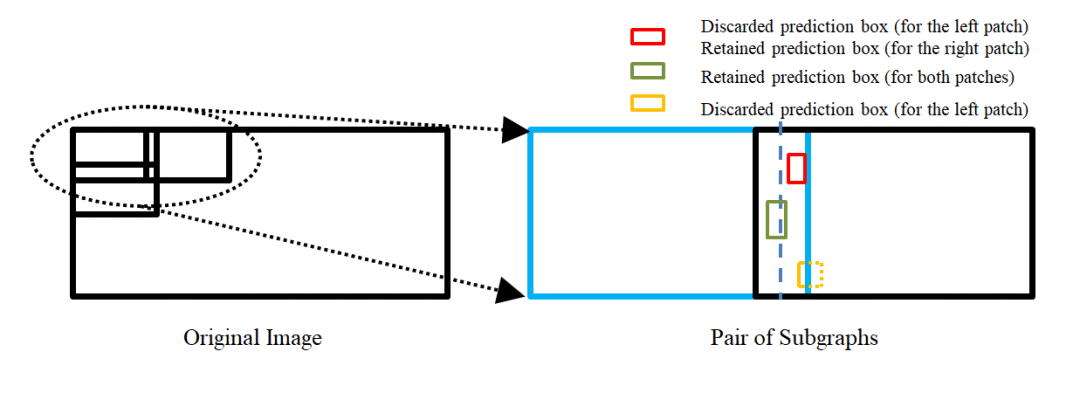
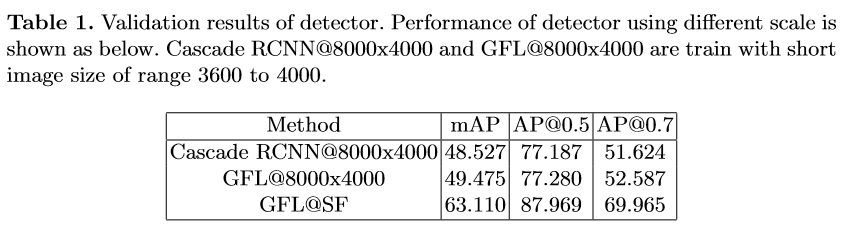
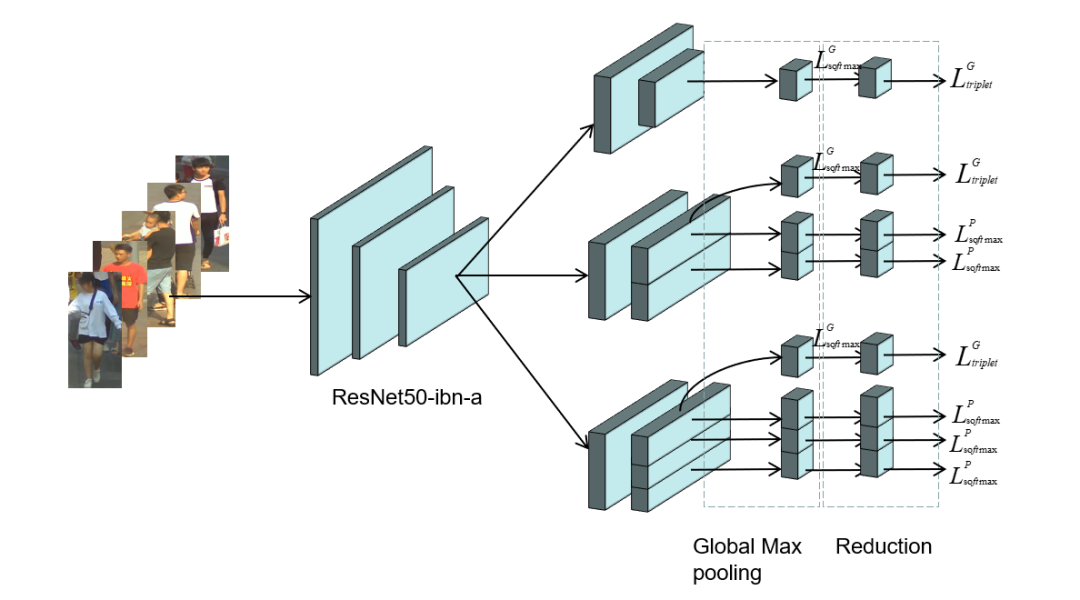
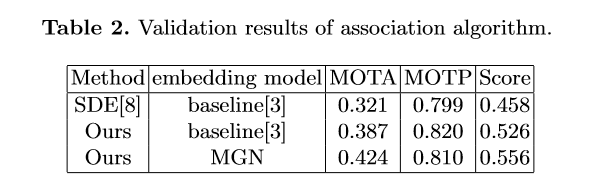
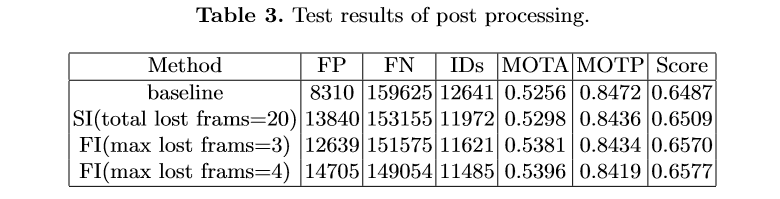
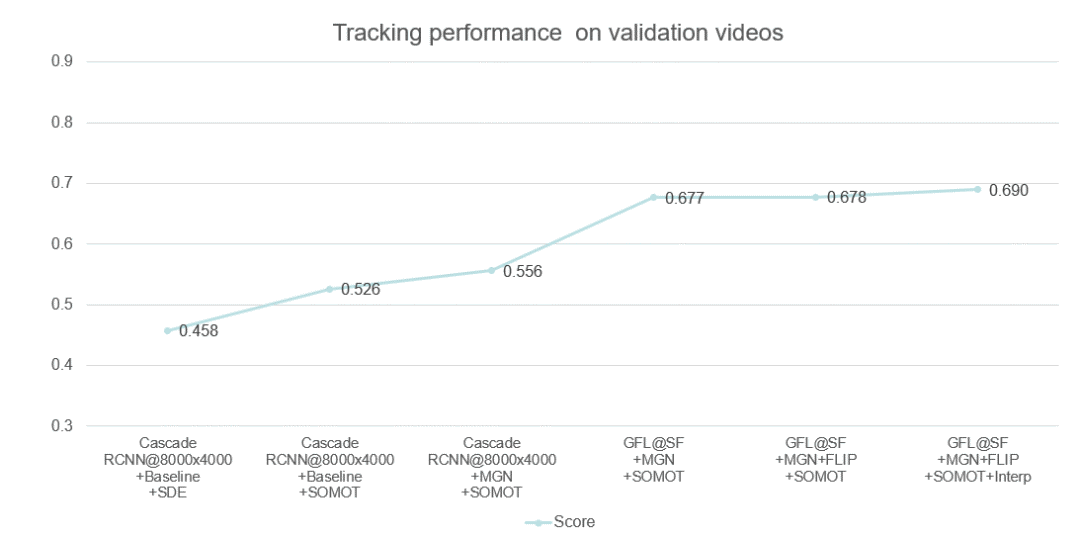
多行人跟踪问题是一个典型的多目标跟踪问题。通过调研总结发现,Tracking-by-detection是处理这一问题的常用且精度比较高的方法[2][7]。基本的流程可以总结如下:3) 通过将特征距离或空间距离将预测的目标与现有轨迹关联。本次挑战赛更注重精度,因此采用了分离Detection和Embedding的方法,该方法的模块化设计的优点使得竞赛精度上优化空间的十分大。通过简单的数据统计分析和可视化分析,团队认为该比赛的主要挑战在于图像的大分辨率和行人的严重拥挤,如下图所示。为了应对这些挑战,针对高分辨、小目标等问题,引入了一种滑动窗口检测算法。针对遮挡严重的问题,使用局部和全局特征来衡量两个相邻帧之间的预测边界框的相似距离,并且借鉴了FairMOT的特征平滑的方法进行缓解。本次采用的多目标跟踪系统是基于Detection和Embedding分离的方法,采用了以Generalized Focal Loss(GFL)[9]为损失的anchor-free检测器,并以Multiple Granularity Network (MGN)[10]作为Embedding模型。在关联过程中,借鉴了DeepSORT[6]和FairMOT[8]的思想,构建了一个简单的在线多目标跟踪器, 如下图所示。为了处理高分辨率的图像,我们提出了一个segmentation-and-fusion(SF)的方法,如下图所示。每一张大图有交叠的切分成多个子图,每一个子图的分辨率为6000*6000,位于图像边缘的子图直接填充均值。为了防止较大的行人目标被切分成进两个子图,相邻的子图横向上重叠宽度为1000像素,纵向重叠宽度设置为2000像素。在融合子图检测结果时,我们采用一种基于子图重叠中线和检测框相交判定的规则。比如,对于一对横向有重叠的子图,如果基于左子图的检测框处于子图重叠中线的右侧,但与该中线相交,该检测框就被保留,反之则丢弃该检测框。通过segmentation-and-fusion方法,与直接合并进行NMS的方法相比, 我们在本地检测验证集取得了0.2AP的提升。为了解决行人拥挤带来的问题,我们采用了Multiple Granularity Network(MGN),如上图所示。我们首先利用Resnet50-ibn-a[4]提取特征,然后使用Triplet loss和Softmax loss计算三个全局特征的损失,仅使用Softmax loss计算局部特征的损失。此外,我们使用了ReID中的常用的训练技巧来优化MGN的性能[3]。我们借鉴了DeepSORT和FairMOT的想法,以检测框的表观距离为主,以检测框的空间距离为辅。首先,我们根据第一帧中的检测框初始化多个轨迹。在随后的帧中,我们根据embedding features之间的距离(最大距离限制为0.7),来将检测框和已有的轨迹做关联。与FairMOT一致,每一帧都会通过指数加权平均更新跟踪器的特征,以应对特征变化的问题。对于未匹配的激活轨迹和检测框通过他们的IOU距离关联起来(阈值为0.8)。最后,对于失活但未完全跟丢的轨迹和检测框也是由它们的IoU距离关联的(阈值为0.8)。由于只对较高的置信度的检测框进行跟踪,因此存在大量假阴性的检测框,导致MOTA[1]性能低下。为了减少置信阈值的影响,团队尝试了两种简单的插值方法。1) 对总丢失帧不超过20的轨迹进行线性插值。我们称之为简单插值(simple interpolation, SI);2)对每一个轨迹只在丢失不超过4帧的帧之间插入。另外,我们称之为片段插值(fragment interpolation, FI)。虽然插值的方法增加了假阳性样本的数量,但是大大减少了假阴性样本,使我们在测试集上实现了0.9左右的提升。不同插值方法的效果如下表所示。以上是团队对参赛方案的优化路线图,通过优化检测器以及特征提取器,数据关联方法、后处理等方法,在GigaVision 2020多行人跟踪挑战赛中获得第一名的成绩。本文针对GigaVision多行人跟踪挑战赛,设计了一个简单、在线的多目标跟踪系统,包括检测器、特征提取、数据关联和轨迹后处理,在GigaVision 2020多行人跟踪挑战赛中获得第一名。很荣幸取得这次竞赛的第一名,在这里也分享一下针对多目标跟踪任务的一些问题以及思考:1)检测器和特征提取器mAP越高,最终跟踪的性能也会相应的提升?团队对以上问题进行了思考,得出一些比较简单的看法:1) 一般来说检测器和特征提取器的性能越理想,最终跟踪的性能也会有相应的提升;mAP作为常用的检测器评估指标来说,mAP的提升不一定能带来跟踪的性能提升,当然这也和评价指标有关系,需要具体问题具体分析,比如检测上多尺度增强带来的AP增益往往会造成MOTA的降低。mAP作为特征提取器的评估指标来说,mAP的提升也不一定能带来跟踪的性能提升,比如Part-Based 的MGN在本次竞赛中虽然mAP比全局特征提取器差几个点,在最后的跟踪上却取得不错的效果。2)现实中的多目标跟踪任务中,摄像头的突然运动以及跟踪对象的突然加速往往都是存在的,这时候的运动模型其实动态性能十分的差劲,反而造成不好的跟踪效果,本次竞赛采用的是直接不采用运动模型的方法。3) 跟踪器的特征平滑操作十分简单有效,不需要类似于DeepSORT进行级联匹配,速度比较快,考虑了同一轨迹的历史特征,使得特征更加鲁棒,减少了单帧跟踪错误带来的影响;4) Part-Based的特征提取器针对这种遮挡比较严重的情况在距离度量时考虑了各个部分的特征,特别的,遮挡部分往往变化比较大,结合特征平滑操作,一定程度上消除了遮挡部分的影响,更关注没有遮挡部分的特征。罗志鹏,DeepBlue Technology北京AI研发中心负责人,毕业于北京大学,曾任职于微软亚太研发集团。现主要负责公司AI平台相关研发工作,带领团队已在CVPR、ICCV、ECCV、KDD、NeurIPS、SIGIR等数十个世界顶级会议挑战赛中获得近二十项冠军,以一作在KDD、WWW等国际顶会上发表论文,具有多年跨领域的人工智能研究和实战经验。1. Bernardin, K. Stiefelhagen, R.: Evaluating multiple object tracking performance(2008)2. Milan, A., Leal-Taixe, L., Reid, I., Roth, S., Schindler, K.: Mot16: A benchmark for multi-object tracking (2016)3. Luo, H., Gu, Y., Liao, X., Lai, S., Jiang, W.: Bag of tricks and a strong baseline for deep person re-identification (2019)4. Pan, X., Luo, P., Shi, J., Tang, X.: Two at once: Enhancing learning and generalization capacities via ibn-net (2018)5. Wang, X., Zhang, X., Zhu, Y., Guo, Y., Yuan, X., Xiang, L., Wang, Z., Ding,G., Brady, D.J., Dai, Q., Fang, L.: Panda: A gigapixel-level human-centric video dataset (2020)6. Wojke, N., Bewley, A., Paulus, D.: Simple online and realtime tracking with a deep association metric (2017)7. Yu, F., Li, W., Li, Q., Liu, Y., Shi, X., Yan, J.: Poi: Multiple object tracking with high performance detection and appearance feature (2016)8. Zhang, Y., Wang, C., Wang, X., Zeng, W., Liu, W.: A simple baseline for multi-object tracking (2020)9. Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv (2020)10. Wang, G., Yuan, Y., Chen, X., Li, J., Zhou, X.: Learning discriminative features with multiple granularities for person re-identification. CoRRabs/1804.01438(2018)11. Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition.pp. 6154–6162 (2018)12. Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. pp. 0–0 (2019)13. Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 764–773 (2017)14. Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)15. Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv preprint arXiv:2006.04388 (2020)16. Solovyev, R., Wang, W.: Weighted boxes fusion: ensembling boxes for object detection models. arXiv preprint arXiv:1910.13302 (2019)