
唐杰:悟道的雄心,何止是万亿参数模型

智能是否仅靠大数据、大模型就能实现?这是近年来人工智能学术界非常关注的问题,这个问题不仅仅源自GPT-3等千亿参数模型带给我们的刺激,也继承自深度学习一贯以来的“简单粗暴”模式。日前,智源研究院发布了“悟道1.0”,这是我国首个超大规模智能模型系统,为业内带来不小的震撼。然而,“悟道”的雄心仅仅止于在当前AI学术界主流中竞争高地吗?
如何使得预训练模型具备初步的认知能力?如何实现对图、文和视频等多模态数据和信息的理解和建模的统一?如何将中文融入预训练模型,推动中文应用背景下的人工智能的发展?如何使得预训练模型深入融入自然科学研究,在目前基础上进一步实现对超长/复杂蛋白质序列的建模和预测?这是悟道1.0要回答的问题。
3月20日,北京智源人工智能研究院举办“智源悟道1.0 AI研究成果发布会暨大规模预训练模型交流论坛”,北京大学、清华大学、中国人民大学、中国科学院等高校院所的专家学者以及美团、快手、搜狗等众多AI企业代表参会。
会上,智源研究院发布了超大规模智能模型“悟道1.0”,这一项目由智源研究院学术副院长、清华大学唐杰教授领衔,带领来自北京大学、清华大学、中国人民大学、中国科学院、阿里等单位的100余位AI科学家团队联合攻关。智源“悟道”是我国首个超大规模智能模型系统,标志着我国人工智能应用基础设施走上快车道。
唐杰教授为我们介绍了“悟道”模型的战略布局及阶段性成果。“悟道1.0”先期启动了4个大模型的研发,即面向中文、多模态、认知、蛋白质预测的大规模预训练模型,并分别取名为“文源”、“文澜”、“文汇”、“文溯”。
除了预训练模型,悟道还研发、开源了万亿参数模型训练的关键技术FastMoE,建设并开放了全球最大中文语料数据库WuDaoCorpora。WuDaoCorpora数据集的数据规模达2TB,超出之前全球最大的中文语料库CLUECorpus2020十倍以上。

唐杰教授介绍悟道大模型团队组建
“文源”、“文澜”、“文汇”、“文溯”,它们毫无疑问都不是小模型,文源拥有26亿参数,文澜则为10亿,文溯是2.8亿,文汇则达到了113亿。虽然相对于GPT-3的1750亿参数而言,这还是小巫见大巫。但唐杰教授告诉AI科技评论,“我们接下来会有更大的模型。”
这四个模型都有哪些强大之处?我们先来一一探究,并逐步揭开悟道雄心的“真面目”。
悟道1.0
文源
“悟道·文源”是“以中文为核心的超大规模预训练语言模型”,目标是构建完成全球规模最大的以中文为核心的预训练语言模型,该项目由清华大学计算机系副教授、智源青年科学家刘知远主导开发。文源此前已经在GitHub开源,获得很高关注度。
项目地址:https://github.com/TsinghuaAI/CPM-Generate
目前,文源模型参数量达26亿,具有识记、理解、检索、数值计算、多语言等多种能力,并覆盖开放域回答、语法改错、情感分析等20种主流中文自然语言处理任务,技术能力已与GPT-3齐平,达到现有中文生成模型的领先效果。
“这里指的‘齐平’是指文源在一系列英文任务上超越了GPT-3,主要集中在偏向实际应用层面的任务。这表明文源的能力不仅仅局限于中文,它也有向英文世界扩展的能力。”唐杰教授告诉AI科技评论,“这同时也表明,语言模型的参数规模不是越大越好。”
而文源的下一步自然也是要向多语言扩展,“这一点和GPT-3很不相同。我们在做一些新的尝试,比如把不同语言的预训练模型融合到一起,融合的方法是用跨语言模型将不同语言的专家模型连接到一起,这样就能实现模型的逐步扩展。”简单而言,就是一个模型能执行多种语言的任务,并能不断学习新的语言。
唐杰教授表示:“这种方法是多语言终身学习的一种初步尝试。”因此,文源自然也不会停留在26亿参数的水平,“我们今年还会提出千亿级的文源模型。”
文澜
“悟道·文澜”是“超大规模多模态预训练模型”,目标是突破基于图、文和视频相结合的多模态数据的预训练理论难题。
目前,文澜模型参数量达10亿,基于从公开来源收集到的5000万个图文对上进行训练,是首个公开的中文通用图文多模态预训练模型。该模型在中文公开多模态测试集AIC-ICC的图像生成描述任务中,得分比冠军队高出5%;在图文互检任务中,得分比目前最流行的UNITER模型高出20%。
从2020年9月开始,通过一系列的实验和探索,文澜的研发团队独立提出了基于多模态对比学习的双塔结构,跟2021年1月OpenAI发布的CLIP很相似。那么,文澜相对于CLIP又有哪些不同呢?
目前文澜的相关论文已经发表,模型名为叫做BriVL (Bridging Vision and Language)。
BriVL论文地址:https://arxiv.org/abs/2103.06561
文澜团队的项目负责人、中国人民大学信息学院教授、智源首席科学家文继荣在发布会上说道,BriVL具有四个特点和优势:
1. 基于视觉-语言弱相关的假设;
2. 与多模态相结合的对比学习算法;
3. 网络结构灵活,方便实际部署;
4. 目前最大的中文多模态通用预训练模型。
我们着重讨论第一个优势。唐杰教授告诉我们,CLIP采用了强标注的图文数据集进行训练,而这样的数据是比较稀有的。
现有的大量多模态预训练模型,特别是单塔结构(比如CLIP),往往会采用如下强假设:对于输入的数据,图像与文本之间存在较强的语义相关性。例如,对于下面这张蛋糕的图片,会假设在多模态数据集中对应“水果蛋糕上有一些蜡烛在燃烧”这样描述性的文本。

正是有了语义相关性上的强假设,单塔结构才能在词汇与局部图像特征之间进行模态交互。但遗憾的是,在实际应用场景中,上述的强假设往往并不成立,比如视觉与语言之间通常只有较抽象的关联。例如,对于蛋糕的照片,配的文字可以是“生日快乐,许个愿吧”,也可以引申到“哎,我的减肥大计又泡汤了”。
文澜的研发者们进行了一系列的实验和探索,实验结果表明,在开放获取(例如互联网上的公开数据)的图文数据集上,简单的双塔结构要优于单塔结构。因此,BriVL采用了双塔结构作为多模态预训练模型的基本架构。
“标注数据很稀缺,如今我们对数据规模的需求越来越大,对亿级数据进行标注几乎不可能实现。所以未来,弱相关的多模态训练是一个大趋势。”唐杰教授说道。
文澜的图文弱相关性使得在图像检索文本场景中,文澜能生成更加生动的文字。比如对于下图,BriVL模型生成的描述是:
梨花开年复年,相思别处生又生;今日有酒今宵醉,何至年头憎恨春
像冬季清晨里的一抹阳光像夏季傍晚的凉风,像秋季午后凉爽的汽水,像春季凌晨犹如浩瀚宇宙一般的天空,你是我的心小鹿乱撞的原因。

然而,即便如此,在从图像特征中提取关键词或标签方面,文澜也毫不示弱。在下图中,用BriVL模型在动漫数据集danboru上进行微调,为动漫图像自动打标签时,可以生成很多关键词:灰色围巾,屋顶,双手插在口袋里,多云的天空,大衣,鸟,围巾,云,天空,长袖,微笑,长发。

基于BriVL模型,可以开发多款跨模态应用。在BriVL的基础上,文澜团队开发了H5小应用《AI心情电台》。
随便上传一张图片后,会为用户配上一首符合意境的歌。《AI心情电台》是使用BriVL提取图像和文本特征,接着进行图文检索,将图片和歌词特征进行匹配,并将歌词准确定位到最符合图片特征的歌词位置。
身为AI科技评论的读者,自然很好奇,AI心情电台会为一张代码截图生成什么心情。
AI心情电台:最爱的就是你,裤子失去皮带,才懂得对他的依赖......
同学:裤子不能没有皮带,就像程序员不能没有代码!懂我……
在未来,文澜团队将使用5亿级别的图文数据作为预训练数据集,BriVL的参数量将达到百亿级别。
文澜擅长的是弱相关的图文转换,这适用于大数据训练。在最后,文澜又一次向我们展示了迈向超大规模参数模型和大数据训练的目标。
文汇
“悟道·文汇”为“面向认知的超大规模新型预训练模型”,致力于从认知的角度研究通用人工智能中一系列更本质问题。
目前,文汇模型的参数规模达113亿,在多项任务中文汇的表现已经接近突破图灵测试,通过简单微调就已经实现AI作诗、AI作图、AI制作视频、图文生成、图文检索、复杂推理。
关于以上功能我们不必做太多介绍,文汇在这方面和文澜有很多相似之处。实际上,悟道1.0的文汇预训练模型还能进行AI作诗。
四个主题下文汇实现的自动作诗:你能猜出哪些是唐宋诗人写的,哪些是模型写的吗?)
此外,类似于DALL-E,文汇模型还可以实现“以文生图”,自动作画。
文汇模型实现的“以文生图”
但文汇最重要的目标还是挖掘预训练模型的认知能力。文汇团队成员、循环智能创始人、智源青年科学家杨植麟在发布会上表示:“之所以要做认知,和我们文汇小组的定位使命有关系。”
第一,我们从一开始就想做有世界影响力的工作。不光是简单地去复刻GPT-3或者BERT,而是在这基础上创新,解决最难的问题,这可能是我们去做这个工作的意义所在。
第二,我们要探索智能的边界。现在有不少超大规模的千万亿模型,但是很多问题是没有办法解决的,在认知问题没有解决前,我觉得其实还是很有多的事情需要学术界和工业界一起探索和解决。
于是,杨植麟提出,要实现认知,短期内要实现三个目标,即“通用、知识、可控”。
第一、通用。如果一个模型只能简单地做一两个任务,或者只能做特定类型的任务,我认为是没有办法实现认知。
第二、知识。如果模型没有知识,在很多现实任务里就很难取得比较好的结果,很多现实任务需要结合知识才能做。
第三、可控。想让模型完成一个任务,得有办法指挥它,给这个模型一个明确地指令,让它产生想要的状态和行为。
杨植麟为我们介绍了文汇的三个重要成果(以及三篇论文),它们分别在上述三个目标上取得重要进展。
首先是通用。NLP任务基本分为三种类型,即分类或理解任务、有条件生成任务、无条件生成任务。其中有条件生成和无条件生成可以按照有无提示统一为生成框架,分类或理解任务可以将输出结果看成是依据提示而生成的。
在将所有任务统一为生成任务后,文汇团队提出了新的预训练范式GLM,“生成的方式是在整个序列里每次mask掉一些东西,通过在Encoder里面嵌入Decoder结构完成这样一个生成。”
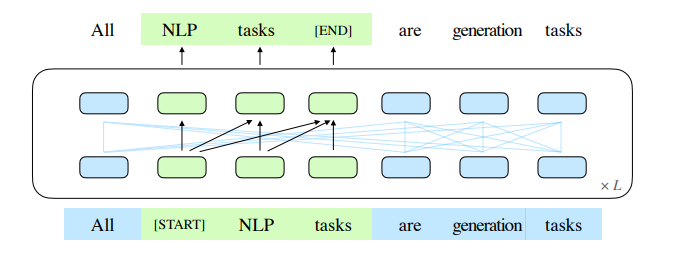
GLM论文地址:arxiv.org/abs/2103.10360
GLM模型可以同时在三个任务上取得最优结果,“在以前,我们要分别训练三个模型,对于超大规模来说也会非常限制模型的使用,”这也是历史上首次实现单一模型同时在三种任务上取得最优的效果。
唐杰教授补充道:“BERT是一个双向模型,在填空这种问题上会更加擅长,并且模型参数量不需要那么大。GPT的优势则在于生成,比如很擅长生成故事等内容。而GLM两种任务都可以完成得很好,相当于把BERT和GPT融合到了一起。”
然后是知识。这里所说的知识是从预训练语言模型中提取的知识,主要解决预训练模型怎么做分类理解任务,这是怎么做的呢?其实就是利用了预训练语言模型的生成能力。我们首先给模型一个句式作为提示,比如“X is located in Y”,当X输入London,我们希望模型预测Y是Britain或者其它答案,这被称为Prompt。
Prompt的内容在起初是手工编写的,随后有人提出了离散的自动生成方法。但离散Prompt对扰动非常敏感,在少样本学习场景下容易过拟合。
因此,文汇团队提出了用连续的向量来表示Prompt的方法,即P-tuning。“通过连续向量输入,直接在连续空间里寻找Prompt的最优解。”
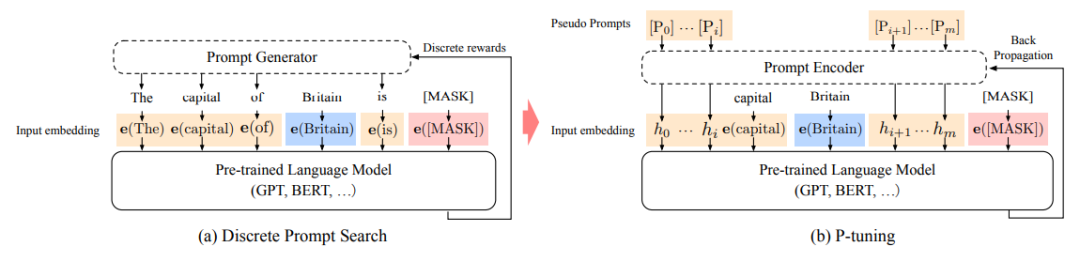
分别用离散Prompt搜索和P-tuning生成“英国的首都是[MASK]”的示例。
P-tuning论文地址:arxiv.org/abs/2103.10385
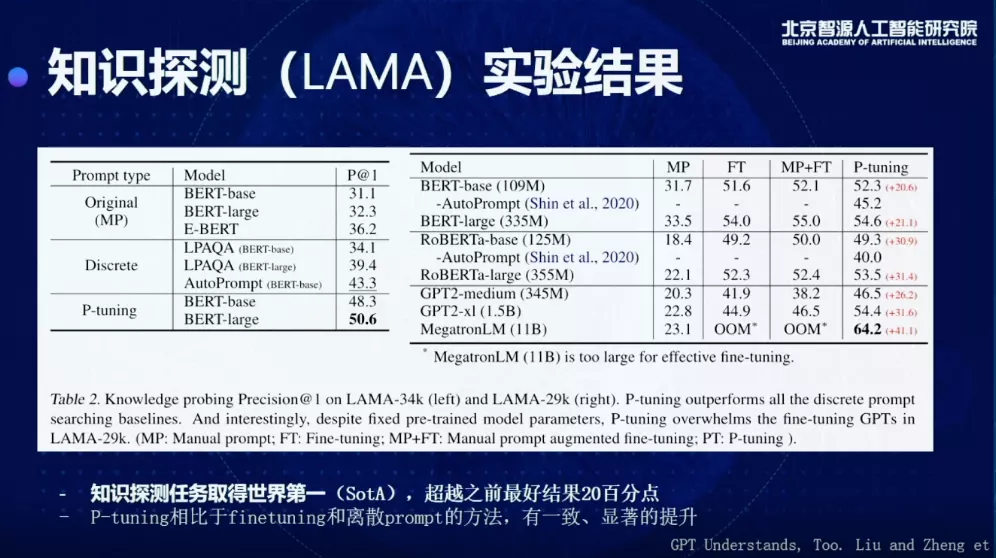
在知识探测任务(LAMA)上,不需要任何额外文本,P-tuning提取的知识可以达到超过60%的准确率,超越之前最好结果20个百分点,取得世界第一。此外,P-tuning在少样本学习中可以打败之前包括PET和GPT-3在内的所有few-shot learning的SOTA方法。
最后是可控。预训练语言模型有一个普遍存在的问题是,问题和答案的关联性太弱,比如下图中所示的例子,“生成的句子非常通顺,但是实际上并没有在回答这个问题。”

为了解决这个问题,文汇团队提出了一个新方法,通过这个方法优化以后会生成:
“一瞬间想到高二的时候,那天下午在操场晒了一中午太阳,和同学一起在楼下打球,下午的夕阳徐徐洒下来,我们三个人一起站在走廊上,倚着栏杆可以面对着夕阳。一直想留下那一瞬间,可惜我以后再也没有遇到过那样的时光。”
“这个回答还有点淡淡的忧伤,通过这种优化可以让回答和问题关联性更强,可以更好地通过Prompt控制所生成的内容。”杨植麟说道。
该新方法——Inverse Prompting的核心思路是用生成的内容反过来以同样的模型预测原来的Prompt,从而保证两者之间的关联性更高。
我们来看看Inverse Prompting生成的藏头诗,在五道口技校(清华大学)的单身狗们是不是觉得非常扎心。

Inverse Prompting论文地址:arxiv.org/pdf/2103.10685
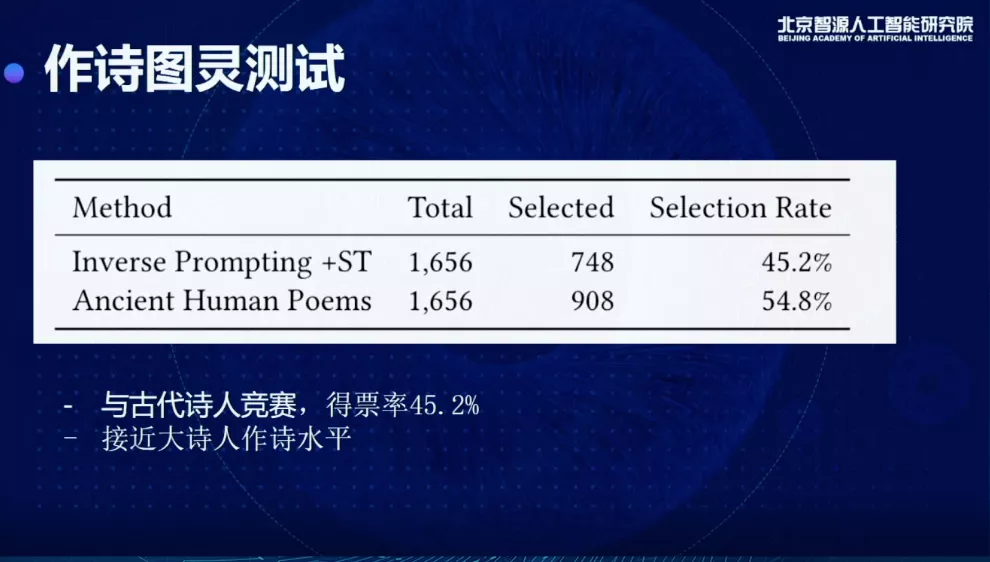
唐杰教授介绍,文汇团队还对模型做了图灵测试。研究人员找了很多古代诗人真正写的诗,用它的标题去生成一些诗,并和古诗进行对比,可以看到在评估结果中文汇有45.2%得票率,比较接近古代大师人的作诗水平。
“P-tuning和Inverse Prompt都是为了更好地提取预训练语言模型中的知识,你有了一个预训练模型,没把它用好的话,它的价值也体现不出来。”唐杰教授表示。
因此,文汇从技术的角度在通用、知识和可控三个方面做了技术突破,从算法的层面做了提升。
我们可以看出,在功能上文源、文澜都和文汇有一定程度上的相似性,但是它们各自的侧重点是不同的。唐杰教授说道:“其实目前这些模型都有一些交集,但是文源的重点是在中文和跨语言,未来也会加入知识,文澜的重点主要是图文,文汇则更多的是瞄向认知。瞄向认知可能听起来比较虚,但是目前文汇已经通过了作诗的图灵测试。从算法的角度上,文汇能通过图灵测试的关键在于生成,而不仅仅限于匹配。而且这种生成能力是多样的,不仅仅限于诗歌,还能生成文本、图像乃至视频等等。”
图灵测试是图灵于1950年提出的一个关于判断机器是否能够思考的著名思想实验,通过人和机器的对话测试机器是否能表现出与人等价或无法区分的智能。
然而,通过图灵测试是否能代表人类智能的实现?唐杰教授回答道:“这肯定还达不到,甚至还得差远。如果突破了图灵测试,大家可能会重新思考智能到底是什么?图灵测试是当时图灵得出的一个对人工智能的阶段性思考。在10-20年内,在世界上很多任务都会突破图灵测试。但是,再往后人的智能怎么来衡量?这其实又是一个新的问题。”
唐杰教授曾经提出认知图谱概念,认为我们如今正从感知时代迈向认知时代,最终的目的是要实现认知图谱,他据此提出了认知AI的九个准则。那么智能的下一个衡量标准是不是这九个准则呢?对此,唐杰教授表示:“我认为下一个人工智能瞄向的一定是认知。图灵测试是一个可度量、可计算的标准,但认知要怎么度量?这九个准则都是我在了解了认知科学领域的前沿后提出的,基本上是可度量以及可用计算模型实现的,并且代表了人类认知水平。”
回到文汇,杨植麟在报告最后表示,这三个算法只是第一步。文汇的长期目标,是从预测去构造决策,包括完全解决少样本问题。“现在少样本学习的很多任务上,实际上最好的方法,仍然跟使用大样本的情况有很大差距。现在的模型无法建立一个完整的知识体系或者持续做这样的学习,所以接下来做的事情是对预训练和微调模式的创新,进一步接近认知目标。”
我们看到,文汇尽管也是数据驱动,却初步触及了认知层面。
文溯
“悟道·文溯”是“超大规模蛋白质序列预测预训练模型”,最终目标是以基因领域认知图谱为指导,研发出10亿参数规模、可以处理超长蛋白质序列的超大规模预训练模型。
目前,文溯已在蛋白质方面完成基于100GB UniParc数据库训练的BERT模型,在基因方面完成基于5-10万规模的人外周血免疫细胞(细胞类型25-30种)和1万耐药菌的数据训练,同时搭建训练软件框架并验证其可扩展性。
文溯还发布并开源了万亿参数模型训练的基石FastMoE,是首个支持PyTorch框架的高性能MoE(混合专家模型)系统,不再受限于谷歌软硬件,支持多种硬件,只需一行代码即可完成MoE化改造,相比传统PyTorch实现,模型训练速度提升47倍。
再提一下文汇。文汇其实还有一个1000亿参数的版本,在从113亿扩展到1000亿版本的过程中,FastMoE技术是其中的关键。
FastMoE的开发由文汇团队和文溯团队联合完成,基于MoE技术。MoE(Mixture of Experts)是一个在神经网络中引入若干专家网络(Expert Network)的技术,也是Google最近发布的1.5万亿参数预训练模型Switch Transformer的核心技术。它对于预训练模型经从亿级参数到万亿级参数的跨越,起了重要推动作用。
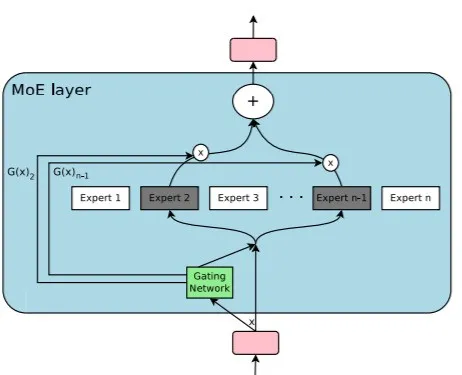
MoE层的设计
唐杰教授表示,FastMoE的适用性很强,包括DNN、CNN、GNN等架构,“假设你的模型一开始是100万的参数规模,如果要扩展到1000万参数规模,FastMoE可以迅速为你实现。”
FastMoE其实早在去年就在研究过程中萌芽,“我们在去年七八月份也做了一个类似的算法,基本思路是一样的,但Switch Transformer在我们发布之前就公开了。之后我们就开始着手在内部做算法的改进。因为MoE当时是面向TPU的架构,它不是面向GPU,也不是面向CPU。所以我们就想把它做成一个通用的架构,让大家都能用得上,然后就有了FastMoE。FastMoE除了能快速扩展模型规模,还能让模型快速收敛。”
FastMoE在整个悟道项目中是属于较上层的结构,然而底层的并行策略和算子加速也是当前阶段性成果的相当重要的组成。
目前只有文汇的1000亿模型和文溯采用了FastMoE技术,后续文源或文澜要进行扩展的时候会用到这项技术吗?唐杰教授告诉我们:“MoE已经基本上变成大模型的一个标配。”
似乎对于悟道而言,训练大模型也不是什么难于登天的事情了。
悟道·雄心
“悟道”于2020年9月开始布局,10月正式启动,在将近半年的时间内就取得了如此令人瞩目的成果。那么“悟道”的目的仅止于大规模预训练模型吗?其实在介绍文汇的时候,我们已经看到了答案的一角,且让我们继续讨论认知图谱。
唐杰教授曾经讨论过人工智能的三个时代:符号智能 —— 感知智能 —— 认知智能。
他认为,要迈向认知智能,首先还是得有足够强大的感知模型,此即悟道当前布局的大规模预训练模型。
认知智能拥有什么新的能力?唐杰教授从人的认知和意识中抽象出来了 9 个认知 AI 的准则:
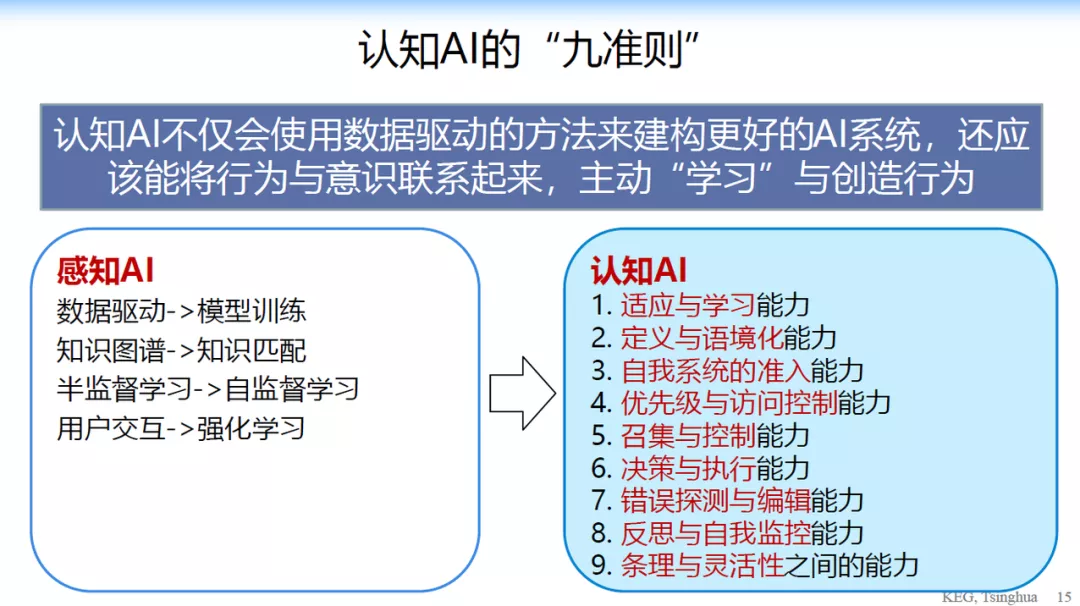
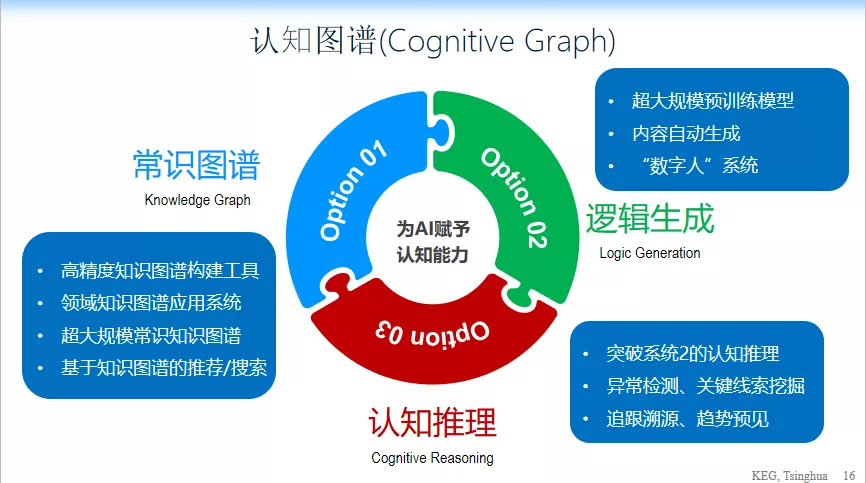
在这 9 个准则的基础上,唐杰教授提出了一个全新的认知图谱的概念,包括三个核心:
1、逻辑生成。与计算模型相关,需要超大规模的预训练模型,并且能够自动进行内容生成。
2、常识图谱。比如说高精度知识图谱的构建,领域制度的应用系统,超大规模城市知识图谱的构建,还有基于知识图谱的搜索和推荐等。
3、认知推理。即让计算机有逻辑推理和思维能力,像人一样思考。
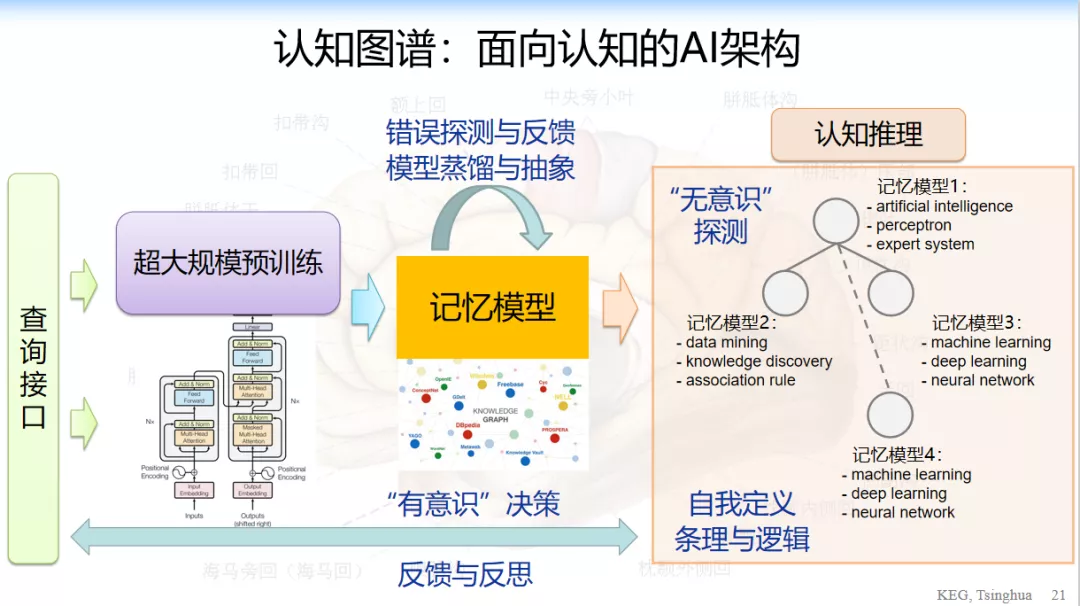
从脑科学的角度来看,人类的认知相对于如今的人工智能有两个最大的不同,第一是记忆,第二是推理。大数据模型实现的是短期记忆,知识图谱实现的是长期记忆,而推理则要在这两者的基础上实现。
从上述四个模型的介绍中我们也能看出,对比认知图谱的框架,悟道1.0还处在感知AI的阶段。
文汇在一定程度上实现了认知能力,不过是基于数据驱动的方式,而不是外部引入知识(知识图谱)的方式。唐杰教授提到,悟道其实目前两条路线都有在布局,一是知识图谱,二是知识提取(此即文汇的方式)。“前者属于强知识派系,后者属于弱知识派系。弱知识是一种完全无监督地从预训练模型中提取知识的方式。我们从模型里面抽出新的知识,然后进行验证。并且反过来,这些知识又可以用来帮助预训练模型,就变成一个自学习加自推理的过程,有点类似于AlphaZero。”
那么,这个认知图谱框架就足以实现悟道的雄心吗?唐杰教授表示,“可以说是,但也不尽然。”
“悟道的整个框架和认知图谱框架有所结合。但是我们也还是在一步一步摸索中,目前只是发布了阶段性的成果。后续可能随着研究的进展,悟道的整个框架也会逐步变化,最后是不是和认知图谱一致,我们也还不清楚。”
到此为止,我们终于明白了悟道的图景。悟道受到认知图谱概念的启发和影响,在探索实现认知的道路,而唐杰教授以及整个悟道团队也将在这过程中不断更新对于通用人工智能的认识。大规模预训练模型,只不过是实现这一宏大图景道路上迈出的一小步。文源、文澜、文汇、文溯有交集也有各自的侧重,然而它们都将在悟道前进的过程中带来丰富的成果和启示。
悟道·初心
从文源到文溯,这些模型拥有非常多样的功能,无论是文本生成、图文转换还是蛋白质预测,都有很大的应用价值。然而悟道的初心,仍然是在学术层面,“目前的确有很多企业在和我们探讨这些模型的应用,但是悟道的核心目标仍然是模型创新和研发。我们希望先有技术上的突破,把高地占到,然后再说剩下的事。”
“不设具体考核任务、不设明确指令目标,去探索一条科技创新的新路子。”——价值观导向下的小同行自治,这是智源研究院成立最初的核心理念。如今,这种“智源模式”的有效性是否得到了验证?
唐杰教授认为:“智源模式支持科学家做‘无人区’的探索,这是核心,就是大力支持科学家做基础理论的探索。而悟道除了智源模式的支持,也有机遇的推动。包括北京政府、智源研究院、众多高校以及很多研究者都认为这件事非常适合智源来做,情怀和共识推动着大家在智源的框架下再做一次创新,远离市场需求去做更长远的研究,又等待着适当的条件下为技术落地赋能。”
唐杰教授继续说道,当初提出这四个预训练模型项目是基于两个方面的考虑。当时GPT-3刚发布不久,悟道团队认为首先要对标其卓越的少样本学习能力,同时还要做出差异化,做短、中、长三个阶段的布局。于是,中文版GPT-3即清源CPM(文源的前身)便应运而生,此为短期布局。之后,文源要向中英文模型乃至多语言模型发展,此为中期布局。最后是学会认知,此为长期布局。
第二个方面,是人才和团队建设,“我们正好拥有三种类型的人才,即企业人才、学术人才和自然科学人才,人才组成是很合理的。对于最后一类人才或者说AI的自然科学研究,我们其实很早就在考虑文溯这个想法,但一直没有立项。然后AlphaFold2就突然间冒了出来,对我们刺激比较大,于是文溯项目立马启动。”
在模型研发的同时,智源研究院也在同步探索“悟道”模型的应用生态建设模式。据唐杰教授介绍,后续“悟道”模型将以开放API(应用程序接口)的形式对外提供服务,用户通过申请并经授权后可以基于模型API开发各类智能化应用。另外,也会开源模型的社区版本。
社区开源模型是原始模型经过蒸馏的版本。“模型不是越大越好用。比如说你训练了一个万亿级模型,在推理的时候,光用它做个for循环都很慢,而且成本也高。又比如文源模型,26亿参数并不是很大,但是在GPU上做推理也是很慢的,而且效果也不可控。还有就是文汇中提出了Inverse Prompt算法,这个算法要求做多次推理,这将使速度变得更加慢。所以蒸馏后的模型可以非常快速地进行推理,在线使用是没有问题的。”
后记
在发布会当天的圆桌讨论中,关于预训练模型是不是越大越好这个话题,众学者都发表了自己的观点。学者们一致认为,对于当下而言,模型确实是越大越好,因为目前还处于感知AI阶段,大多数任务设置都比较初级。刘知远副教授提出,随着模型的增大,我们也可能迎来质变,实现类似于牛顿力学给物理学带来的变革,并在未来以新的起点学习大模型,从而实现螺旋式发展。
唐杰教授补充道:“目前随着预训练模型的增大,边际效用还在不断增加。未来会发展成什么样还不好说,有可能边际效用会变得很小甚至消失,到时我们可能得寻求新的方向,也有可能会出现奇点,认知能力自然而然地出现。无论如何,悟道当前的路线都是有意义的,给我们带来了很多模型创新。”
这意味着,在从感知阶段迈向认知阶段的过程中,我们还会面对很多不确定性的考验,可能是惊喜,可能是失望,但这条路目前还得一路黑地走下去。
唐杰教授告诉AI科技评论,悟道在六月份还会有重大发布。到时又会给我们带来什么惊喜呢?我们拭目以待。

尊敬的读者你好,我们建立了微信群,方便大家学习交流讨论!欢迎大家!
另外微商和广告商请绕道!谢谢合作!
不能进群的朋友请加我的微信!
