1.2万亿参数:谷歌通用稀疏语言模型GLaM,小样本学习打败GPT-3
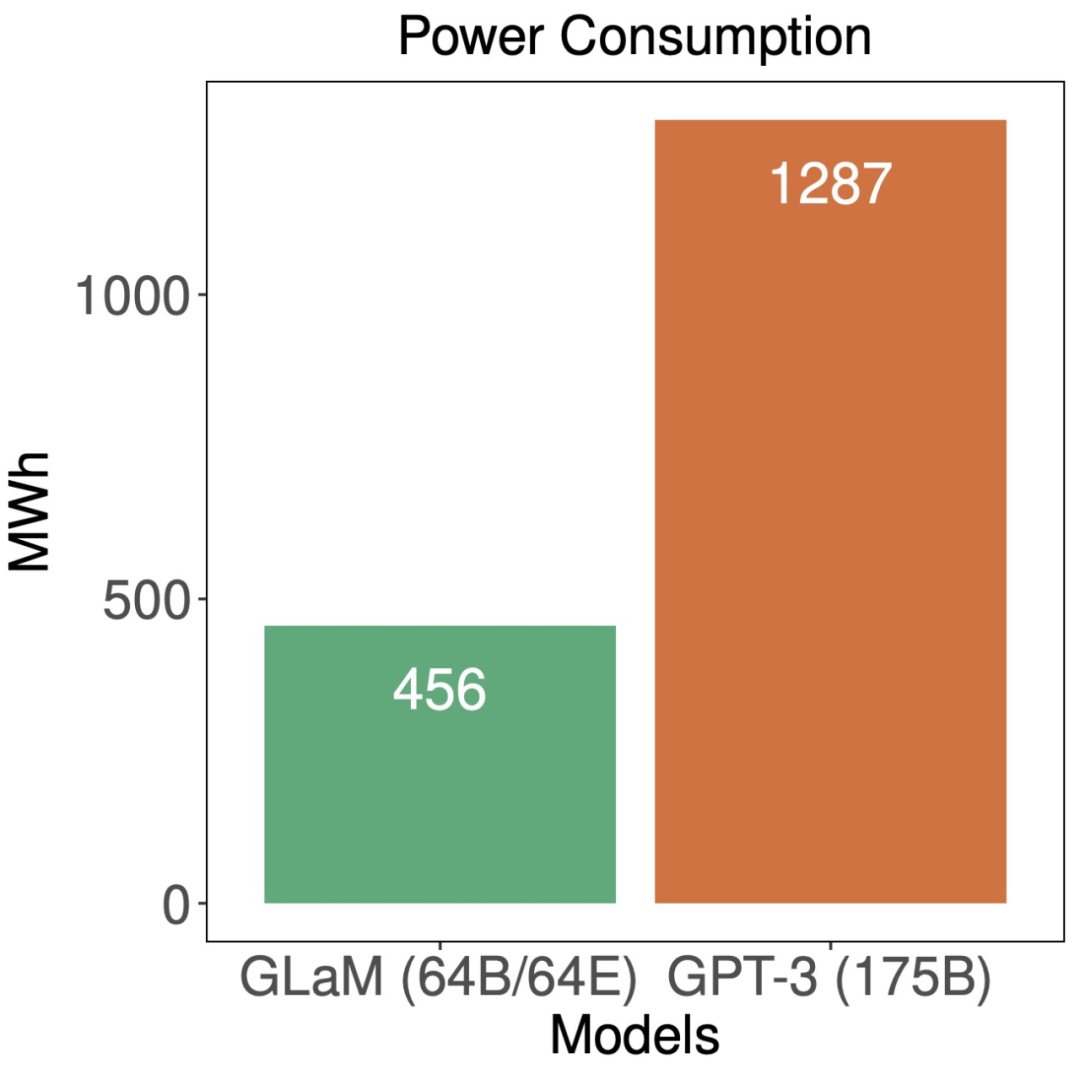
大规模语言模型性能固然好,但计算和资源成本太高了,有没有方法可以更有效地训练和使用 ML 模型呢?

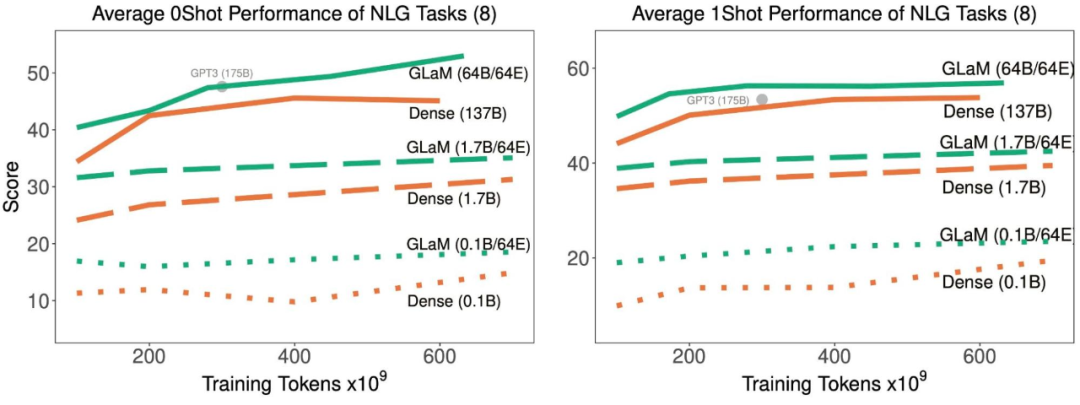
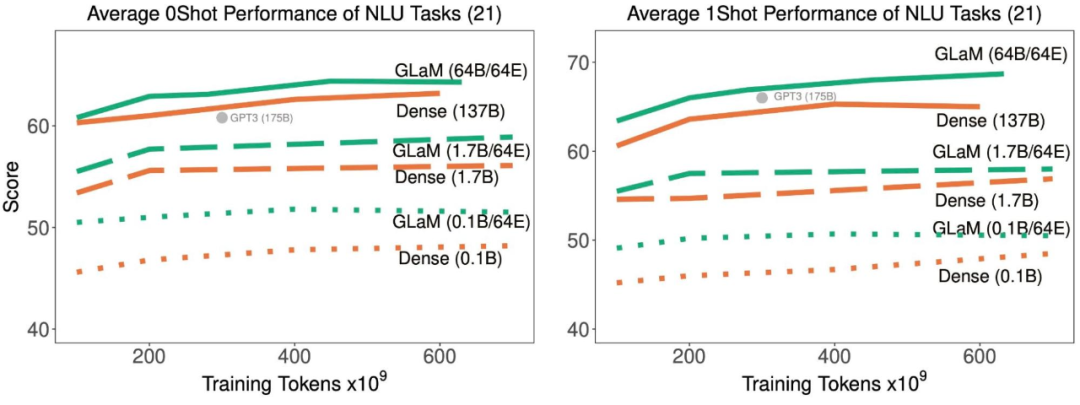
完形填空和完成任务;
开放域问答;
Winograd-style 任务;
常识推理;
上下文阅读理解;
SuperGLUE 任务;
自然语言推理。

© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP大规模语言模型性能固然好,但计算和资源成本太高了,有没有方法可以更有效地训练和使用 ML 模型呢?
完形填空和完成任务;
开放域问答;
Winograd-style 任务;
常识推理;
上下文阅读理解;
SuperGLUE 任务;
自然语言推理。
© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!