
【NLP】什么是模型的记忆力!
作者 | 太子长琴
整理 | NewBeeNLP
语言模型能够记住一些训练数据,如果经过合适地提示引导,可能会生成记住的数据。这肯定不太合适,因为可能会侵犯隐私、降低效用(重复的容易记住的词往往质量比较低),并且有失公平(有些文本被记住而有些没有)。
在我们今天要分享来自Google的Paper:Quantifying Memorization Across Neural Language Models[1]中,描述了三个对数线性关系,量化了 LM 生成记忆数据的程度。如果增大:(1)模型的容量,(2)样本的重复次数,(3)提示文的 Token 数量,记忆会显著增加。总的来说,LM 的记忆比之前认识到的更普遍,并随着模型不断增大可能变得更糟。
一句话概述:更大的模型更可能学到重复数据的特性,去重是缓解模型记忆危害的不错策略。
其实,关于模型的记忆一直以来都是有被人们认识到的,尤其当我们在做文本生成时,总是特别担心模型会说出什么「惊人」的话语。亚马逊的音响案例仅仅是一方面,还有可能会生成政治敏感、歧视、暴力、色情等多种不当言论,这还是被动的方面。模型也可能被怀有不良意图的人「诱导」而生成一些能被他们利用到的言论和信息。
目前对 LM 这方面的评估还比较浅,对不同大小的模型和数据集能带来多少记忆的变化的理解还不够深入。之前的很多研究主要聚焦在模型或数据集固定的情况,或比较狭窄的变化上。也有衡量现有模型记忆的,但更多关注如何避免问题并确保模型输出的新颖性,而不是研究最大限度地记忆来研究模型风险。
本文从三个能显著影响记忆的属性进行研究:
模型规模:大模型比小模型能多记住 2-5 倍的数据。 数据重复:样本重复次数越多越容易被提取。 上下文:围绕的上下文越长越容易被提取。
方法
记忆的定义
如果存在一个长度为 k 的文本 p,通过模型 f + greedy decoding,可以生成文本 s,而 p+s 包含在训练数据中,则称 s 是可提取的。选择此定义的原因是更加可执行。其他定义包括:差异隐私或反事实记忆的下限(需要大量模型评估隐私,对大模型不合适);计算曝光(每个序列需要数千个生成,为精心设计训练样本设计,大规模实验不可行);k-eidetic 记忆,对非提示的记忆是个有用的定义,但对使用训练数据进行提示的情况不太有用。
评估数据的选择
首先不可能是所有训练数据了,本文选择了 50000 句,当然也不能随机选,否则不可能包含到要评估的方向。本文构造了一个重复归一化的子集,对每个序列长度 L(50,100,150,……,500)和整数 n,选择 1000 个序列,在训练数据中包含了 2^{n/4} - 2^{n+1}/4 次。这个操作直到某个 n 时,训练数据中按此标准没法得到 1000 句时停止。这有助于评估样本重复这个因子。对 50-500 之间的每个序列长度,都分别收集了大约 50000 个重复不同次数的样本,总共大概 50 万个序列。比如,对 L=50,从 n=7 时,重复次数 3-4 次,选择 1000 个,然后增加 n,直到训练数据中找不到 1000 个时停止,一共大概有 50000 个。
对每个长度 L,使用前 L-50 个 Token 进行提示,预测 50 个 Token 看看是不是和原文完全匹配。50 个 Token 对应 127 个字符或 25 个单词,远超过典型英语句子的长度。通过对所有长度 L(而不是重复次数)求平均值来计算序列可提取的平均概率。
实验
主要研究 GPT-Neo,在 Pile 数据集(各种来源的 825G 语料)上训练的。模型有四种尺寸:125M,1.3B,2.7B 和 6B。
实验结果如下图所示: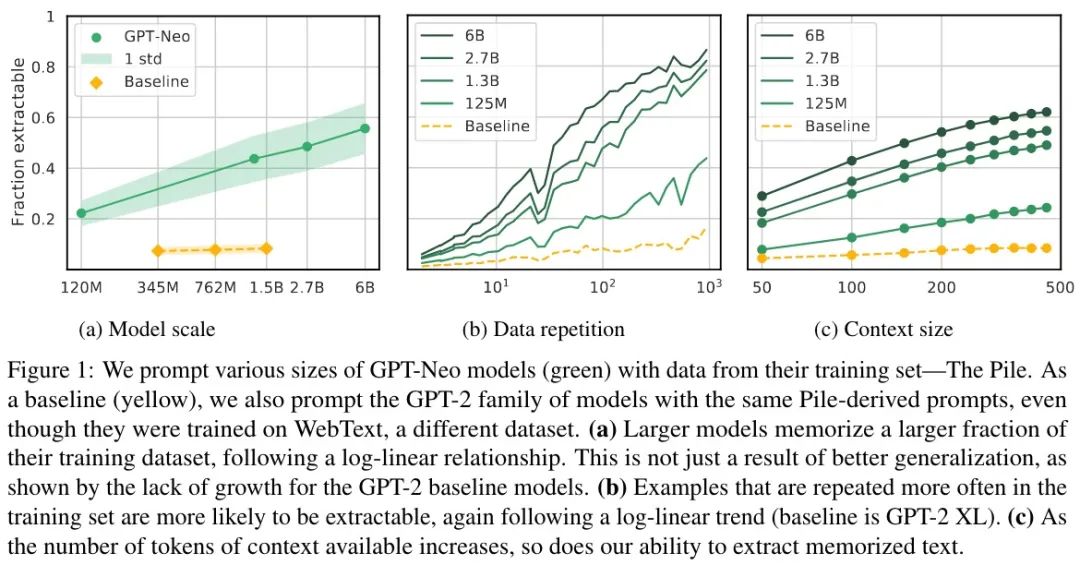
更大模型记住更多
如图 a 所示,相比 Baseline 的 GPT-2 能完成 6% 的评估样本,GPT-Neo 相似大小(1.3B)达到了 40%,GPT-2 记住的大多是无意义的序列(数字、重复的几个 Token 或标点)。因此,得出的结论是: 较大模型具有较高比例的提取率,这是因为它们记住了数据,而不仅仅是因为大模型通常更准确。
重复文本记住更多
如图 b 所示,重复的文本越多被记住的概率越大。而且还可以发现, 即使只有很少的重复记忆也会发生 ,因此去重并不能完美的防止泄露。
更长的提示记住更多
如图 c 所示,随着提示长度的增加,记忆也有显著的增加。作者称其为「可发现现象」:一些记忆只有在特定条件下才会变得明显,例如当模型被提示具有足够长的上下文时。一方面看这是好的,因为一些记忆难以被发现;另一方面看,也会损害我们在机器学习模型审计隐私的能力。
以下是备用实验设置,结果如下图所示:
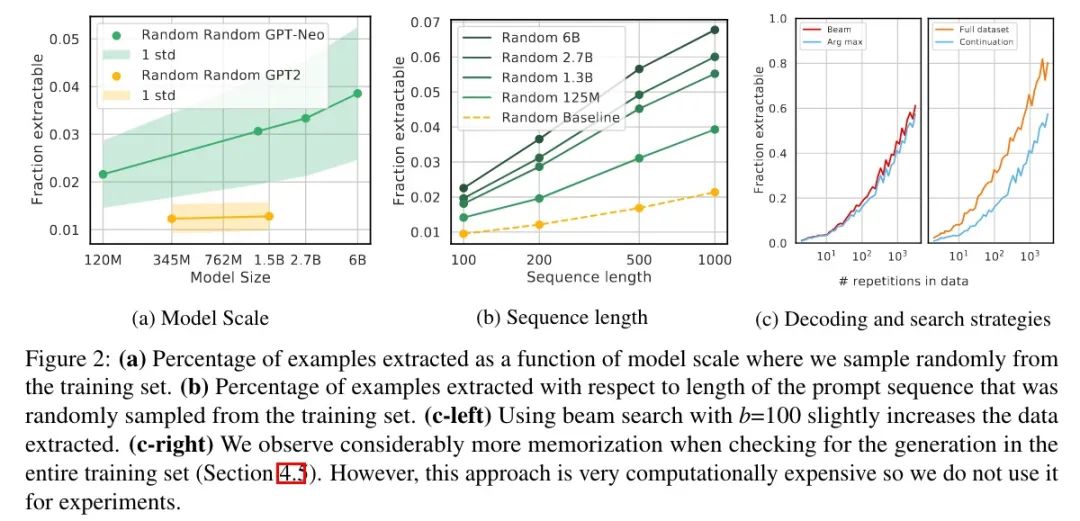
随机采样
为 100 200 500 1000 的长度各随机选择了 10 万,结果如图 a 和 b 所示,记忆的绝对概率远低于之前实验的结果,不过整体的趋势是一样的。另外,长序列相比短序列更容易预测正确(图 b Baseline,GPT2-XL,1.5B)。
解码策略
如图 c(左)所示,beam search(b=100)只是轻微增加了记忆,而且两者在 45% 的时间内产生了相同的输出。
其他定义
就是本来是和原始那条数据对比,现在是在整个语料上看有没有一样的。这其实是放宽了记忆,因为有些句子前缀一样,但后面不一样。按之前那种做法,如果后缀正好生成了另外一句的,那就不算记住了;但现在的定义也算记住了。
结果如图 c(右)所示,稍微用脑子想一下都知道结果肯定是增加了,而且随着重复次数的增加,差异更加明显。
定性分析
普遍的记忆序列都是非常规文本,如代码片段或高度重复的文本(如开源许可)。另外,增加模型大小会导致大量非重叠的记忆序列,尽管每个模型都有一些彼此不同享的记忆量。如下图所示:
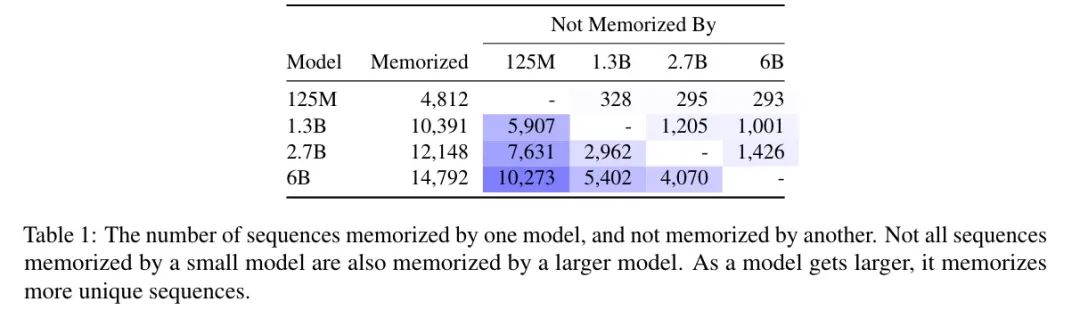
同时,还发现虽然较小模型的生成和训练数据不匹配,但通常主题相关且局部一致,但它们只是语法上合理,语义上不正确。
复制研究
接下来,进一步将上面的分析复制到在不同数据集(重复的 C4)和具有不同训练目标上训练的不同语言模型家族(T5)上。
实验结果如下图所示:
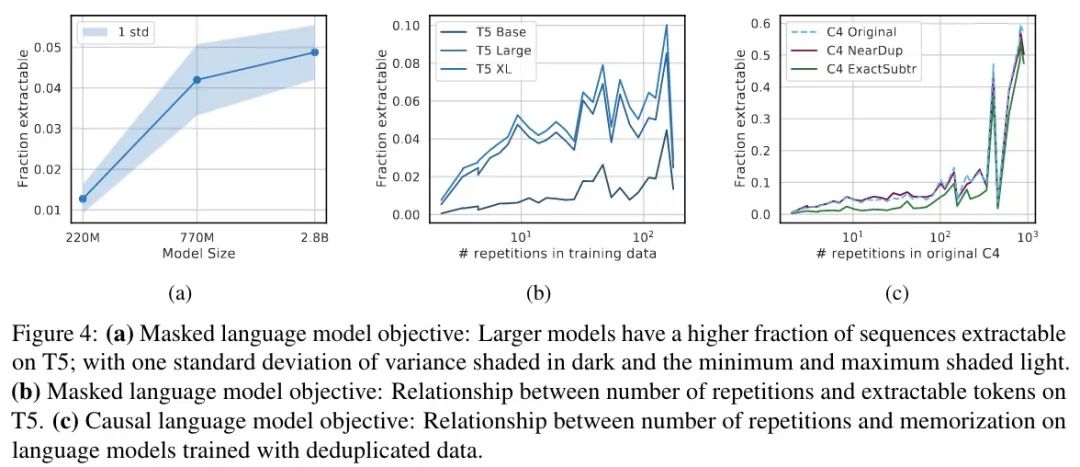
T5 MLM
首先需要重新定义一下什么是记忆,由于是 MLM,这里就定义为可以完美地完成填空(15% 的空),简单起见每句只检查一组。结果如上图 a 所示,结果与图 1 类似,随着参数的增加,记忆增加。虽然趋势一致,但与同等大小的因果模型相比,MLM 的记忆要少一个数量级。
接下来是重复样本的情况,如上图 b 所示,结果开始变得不那么明朗,趋势并不明显,出现大约 140 次的序列更可能被记住。进一步定性分析发现,138-158 重复组中包含的大多数重复样本大多是空格 Token,这就比其他重复次数的序列更容易预测。
在重复数据上训练的 LM
共三组结果,分别是:C4,删除近似重复的文档后的 C4,删除长度为 50 Token 的重复后的 C4。结果如上图 c 所示,去重后记住的要更少,但只有在重复 100 次以下时有效,重复超过 100 次后就没用了,可能意味着重复数据删除并未彻底(重复的不同但有效的定义)。
说实话,这个解释真的很牵强啊……
结论
对于研究文本生成的从业者来说,本文证明,虽然当前 LM 确实准确模拟了训练数据的分布,但并不一定意味着它们将对所需的基础数据分布进行建模。特别当训练数据分布偏斜(比如有很多重复样本)时,更大的模型更可能会学习到意外的数据集特性。因此,仔细分析用于训练更大模型的数据集变得更加重要,因为更大模型可能比小模型记住更多细节。
对于研究隐私的从业者来说,本文的研究表明,当前大型语言模型可能会记住其训练数据的很大一部分,记忆与模型大小呈对数线性关系。同时,这种记忆常常不容易被发现,并且对于实际提取这些数据的攻击,必须开发定性的新攻击策略。幸运的是,仅出现一次的训练数据似乎很少被记住,因此去重可能是缓解模型记忆危害的一项实用技术。
本文参考资料
Quantifying Memorization Across Neural Language Models: https://arxiv.org/abs/2202.07646
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码