
基于深度学习的低光照图像增强方法总结(2017-2019)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自 | 新机器视觉
之前在做光照对于高层视觉任务的影响的相关工作,看了不少基于深度学习的低光照增强(low-light enhancement)的文章[3,4,5,7,8,9,10],于是决定简单梳理一下。
光照估计(illumination estimation)和低光照增强(low-light enhancement)的区别:光照估计是一个专门的底层视觉任务(例如[1,2,6]),它的输出结果可以被用到其它任务中,例如图像增强、图像恢复(处理色差,白平衡)。而低光照增强是针对照明不足的图像存在的低亮度、低对比度、噪声、伪影等问题进行处理,提升视觉质量。值得一提的是,低光照增强方法有两种常见的模式,一种是直接end-to-end训练,另一种则包含了光照估计。
LLNet: A deep autoencoder approach to natural low-light image enhancement
2017 Pattern Recognition
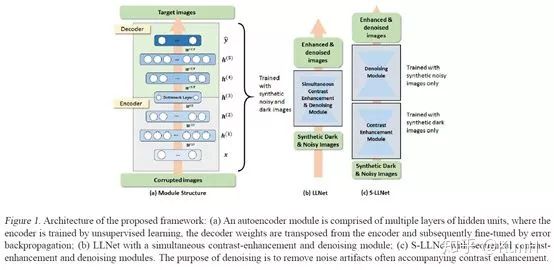
这篇文章应该是比较早的用深度学习方法完成低光照增强任务的文章,它证明了基于合成数据训练的堆叠稀疏去噪自编码器能够对的低光照有噪声图像进行增强和去噪。模型训练基于图像块(patch),采用sparsity regularized reconstruction loss作为损失函数。
主要贡献如下:
(1)我们提出了一种训练数据生成方法(即伽马校正和添加高斯噪声)来模拟低光环境。
(2)探索了两种类型的网络结构:(a) LLNet,同时学习对比度增强和去噪;(b) S-LLNet,使用两个模块分阶段执行对比度增强和去噪。
(3)在真实拍摄到的低光照图像上进行了实验,证明了用合成数据训练的模型的有效性。
(4)可视化了网络权值,提供了关于学习到的特征的insights。
MSR-net:Low-light Image Enhancement Using Deep Convolutional Network
2017 arXiv
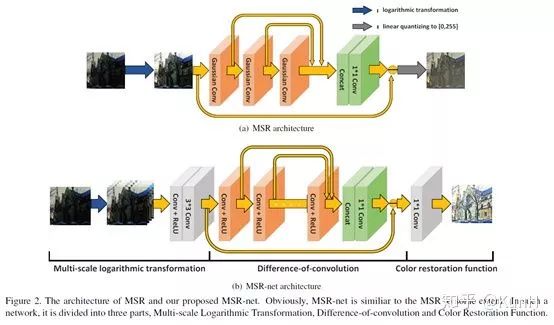
这篇文章引入了CNN,它提了一个有趣的观点,传统的multi-scale Retinex(MSR)方法可以看作是有着不同高斯卷积核的前馈卷积神经网络,并进行了详细论证。
接着,仿照MSR的流程,他们提出了MSR-net,直接学习暗图像到亮图像的端到端映射。MSR-net包括三个模块:多尺度对数变换->卷积差分->颜色恢复,上面的结构图画得非常清楚了。
训练数据采用的是用PS调整过的高质量图像和对应的合成低光照图像(随机减少亮度、对比度,伽马校正)。损失函数为带正则项的误差矩阵的F-范数平方,即误差平方和。
Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images
2018 TIP
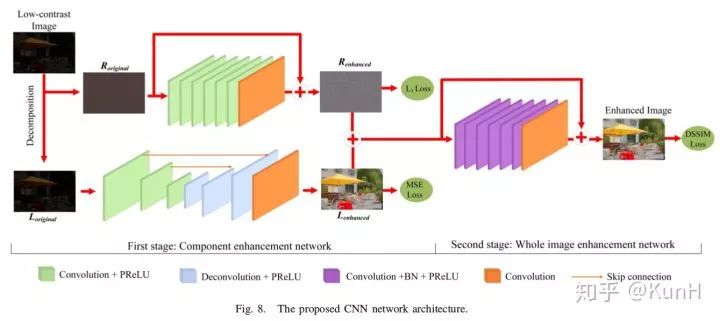
这篇文章其实主要关注单图像对比度增强(SICE),针对的是欠曝光和过曝光情形下的低对比度问题。其主要贡献如下:
(1)构建了一个多曝光图像数据集,包括了不同曝光度的低对比度图像以及对应的高质量参考图像。
(2)提出了一个两阶段的增强模型,如上图所示。第一阶段先用加权最小二乘(WLE)滤波方法将原图像分解为低频成分和高频成分,然后对两种成分分别进行增强;第二阶段对增强后的低频和高频成分融合,然后再次增强,输出结果。
对于为什么要设计两阶段结构,文章中是这样解释的:单阶段CNN的增强结果并不令人满意,且存在色偏现象,这可能是因为单阶段CNN难以平衡图像的平滑成分与纹理成分的增强效果。
值得一提的是,模型第一阶段的Decomposition步骤采用的是传统方法,而后面介绍的Retinex-Net使用CNN实现了。
Deep Retinex Decomposition for Low-Light Enhancement
2018 BMVC
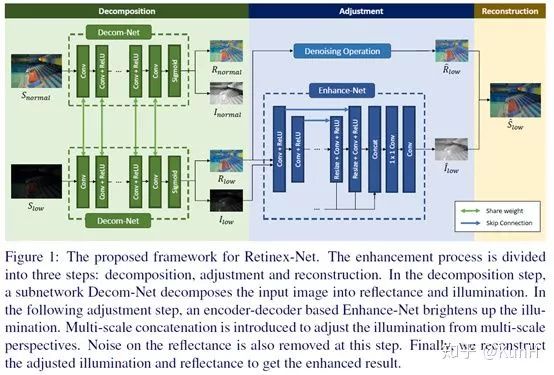
这篇文章是我前后读过许多遍,比较值得介绍。受Retinex理论的启发,它采用了两阶段式的先分解后增强的步骤,完全采用CNN实现。对于Decom-Net的训练,引入了反射图一致性约束(consistency of reflectance)和光照图平滑性约束(smoothness of illumination),非常容易复现,实验效果也不错。
主要贡献如下:
(1)构建了paired的低光照/正常光照数据集LOL dataset,应该也是第一个在真实场景下采集的paired dataset.该数据集分为两部分:真实场景的图像数据是通过改变相机感光度和曝光时间得到的;合成的图像数据是用Adobe Lightroom接口调节得到的,并且调节后图像的Y通道直方图必须尽可能地接近真实低光照场景。
(2)提出了Retinex-Net,它分为两个子网络:Decom-Net能够对图像进行解耦,得到光照图和反射图;Enhance-Net对前面得到的光照图进行增强,增强后的光照图和原来的反射图相乘就得到了增强结果。另外,考虑到噪声问题,采用一种联合去噪和增强的策略,去噪方法采用BM3D。
(3)提出一个structure-aware total variation constraint,就是用反射图梯度作为权值对TV loss进行加权,从而在保证平滑约束的同时不破坏纹理细节和边界信息。
MBLLEN: Low-light Image/Video Enhancement Using CNNs
2018 BMVC
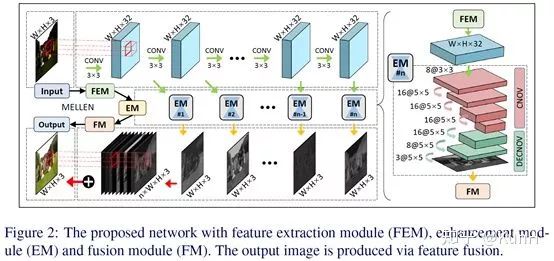
这篇文章的核心思想是,网络中不同层次的特征的提取和融合。此外,该文的另一个亮点是针对视频的低光照增强网络,和一帧一帧处理的直接做法不同,它们使用3D卷积对网络进行了改进,有效提升了性能。
补充说明一下,视频的低光照增强会存在的一种负面情况,闪烁(flickering),即帧与帧之间可能存在不符合预期的亮度跳变。这一问题可以用AB(avr)指标(即平均亮度方差)来度量。
网络结构:包括特征提取模块FEM、增强模块EM和融合模块FM。FEM是有10层卷积的单流向网络,每层的输出都会被输入到各个EM子模块中分别提取层次特征。最终这些层次特征被拼接到一起并通过1x1卷积融合得到最终结果。为了用于视频增强,还需要对网络进行修改,具体可参考原文。
损失函数:本文不采用常规的MSE或者MAE损失,而是提了一个新的损失函数,包括三个部分,即结构损失、内容损失和区域损失。结构损失采用SSIM和MS-SSIM度量相结合的形式;内容损失,就是VGG提取的特征应该尽可能相似;区域损失令网络更关注于图像中低光照的区域。
Learning to See in the Dark
2018 CVPR

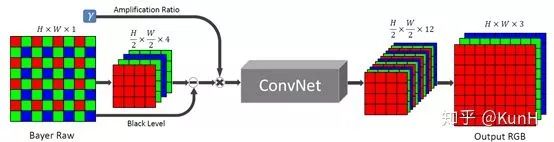
这篇文章主要关注于极端低光条件和短时间曝光条件下的图像成像系统,它用卷积神经网络去完成Raw图像到RGB图像的处理,实验效果非常惊艳。
网络结构基于全卷积网络FCN,直接通过端到端训练,损失函数采用L1 loss。此外,文章提出了See-in-the-Dark数据集,由短曝光图像及对应的长曝光参考图像组成。
Kindling the Darkness: A Practical Low-light Image Enhancer
2019 arXiv
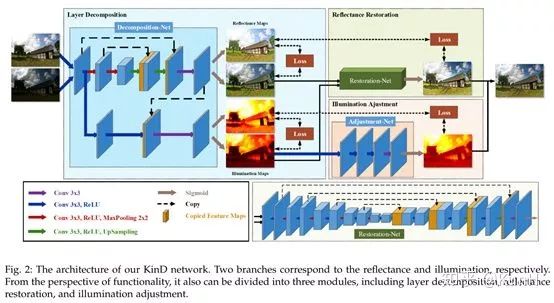
这篇文章在今年5月份挂到了arXiv上,干货挺多,据称是state-of-the-art。它提出了低光照增强任务存在的三个难点:
(1) 如何有效的从单张图像中估计出光照图成分,并且可以灵活调整光照level?
(2) 在提升图像亮度后,如何移除诸如噪声和颜色失真之类的退化?
(3) 在没有ground-truth的情况下,样本数目有限的情况下,如何训练模型?
这篇文章的增强思路还是沿用了Retinex-Net的decomposition->enhance的两阶段方式,网络总共分为三个模块:Decomposition-Net、Restoration-Net和Adjustment-Net,分别执行图像分解、反射图恢复、光照图调整。一些创新点如下:
(a)对于Decomposition-Net,其损失函数除了沿用Retinex-Net的重构损失和反射图一致损失外,针对光照图的区域平滑性和相互一致性,还增加了两个新的损失函数。
(b)对于Restoration-Net,考虑到了低光照情况下反射图往往存在着退化效应,因此使用了良好光照情况下的反射图作为参考。反射图中的退化效应的分布很复杂,高度依赖于光照分布,因此引入光照图信息。
(c)对于Adjustment-Net,实现了一个能够连续调节光照强度的机制(将增强比率作为特征图和光照图合并后作为输入)。通过和伽马校正进行对比,证明它们的调节方法更符合实际情况。
参考文献
[1] Shi, W., Loy, C. C., & Tang, X. (2016). Deep Specialized Network for Illuminant Estimation. ECCV, 9908, 371–387. doi.org/10.1007/978-3-3
[2] Guo, X., Li, Y., & Ling, H. (2017). LIME: Low-light image enhancement via illumination map estimation. IEEE Transactions on Image Processing, 26(2), 982–993. doi.org/10.1109/TIP.201
[3] Lore, K. G., Akintayo, A., & Sarkar, S. (2017). LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognition, 61, 650–662. doi.org/10.1016/j.patco
[4] Shen, L., Yue, Z., Feng, F., Chen, Q., Liu, S., & Ma, J. (2017). MSR-net:Low-light Image Enhancement Using Deep Convolutional Network. ArXiv. Retrieved from arxiv.org/abs/1711.0248
[5] Cai, J., Gu, S., & Zhang, L. (2018). Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Transactions on Image Processing, 1(c), 1–14. Retrieved from www4.comp.polyu.edu.hk/
[6] Gao, Y., Hu, H. M., Li, B., & Guo, Q. (2018). Naturalness preserved nonuniform illumination estimation for image enhancement based on retinex. IEEE Transactions on Multimedia, 20(2), 335–344. doi.org/10.1109/TMM.201
[7] Chen, C., Chen, Q., Xu, J., & Koltun, V. (2018). Learning to See in the Dark. CVPR, 3291–3300. doi.org/10.1109/CVPR.20
[8] Lv, F., Lu, F., Wu, J., & Lim, C. (2018). MBLLEN: Low-light Image/Video Enhancement Using CNNs. BMVC, 1–13.
[9] Wei, C., Wang, W., Yang, W., & Liu, J. (2018). Deep Retinex Decomposition for Low-Light Enhancement. BMVC, (61772043). Retrieved from arxiv.org/abs/1808.0456
[10] Zhang, Y., Zhang, J., & Guo, X. (2019). Kindling the Darkness: A Practical Low-light Image Enhancer. ArXiv, 1–13. Retrieved from arxiv.org/abs/1905.0416
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
 End
End
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~