
【深度学习】实战|13个Pytorch 图像增强方法总结(附代码)
作者丨结发授长生@知乎
链接丨https://zhuanlan.zhihu.com/p/559887437
使用数据增强技术可以增加数据集中图像的多样性,从而提高模型的性能和泛化能力。主要的图像增强技术包括:
- 调整大小
- 灰度变换
- 标准化
- 随机旋转
- 中心裁剪
- 随机裁剪
- 高斯模糊
- 亮度、对比度调节
- 水平翻转
- 垂直翻转
- 高斯噪声
- 随机块
- 中心区域
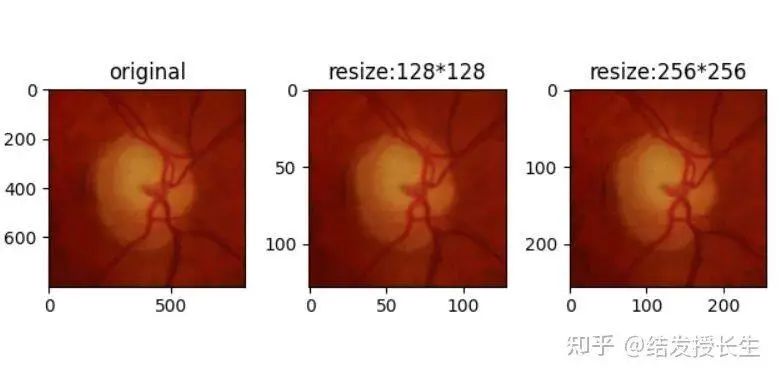
调整大小
在开始图像大小的调整之前我们需要导入数据(图像以眼底图像为例)。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/000001.tif'))
torch.manual_seed(0) # 设置 CPU 生成随机数的 种子 ,方便下次复现实验结果
print(np.asarray(orig_img).shape) #(800, 800, 3)
#图像大小的调整
resized_imgs = [T.Resize(size=size)(orig_img) for size in [128,256]]
# plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('resize:128*128')
ax2.imshow(resized_imgs[0])
ax3 = plt.subplot(133)
ax3.set_title('resize:256*256')
ax3.imshow(resized_imgs[1])
plt.show()
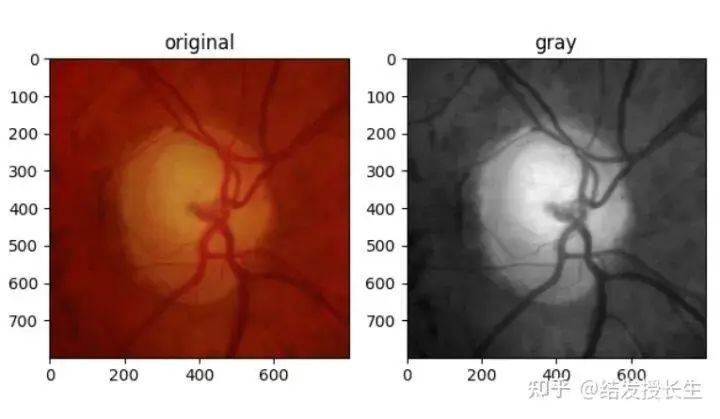
灰度变换
此操作将RGB图像转化为灰度图像。
gray_img = T.Grayscale()(orig_img)
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('gray')
ax2.imshow(gray_img,cmap='gray')
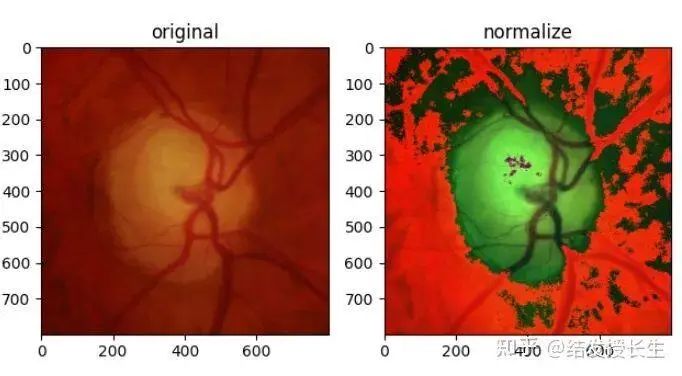
标准化
标准化可以加快基于神经网络结构的模型的计算速度,加快学习速度。
- 从每个输入通道中减去通道平均值
- 将其除以通道标准差。
normalized_img = T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))(T.ToTensor()(orig_img))
normalized_img = [T.ToPILImage()(normalized_img)]
# plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('normalize')
ax2.imshow(normalized_img[0])
plt.show()
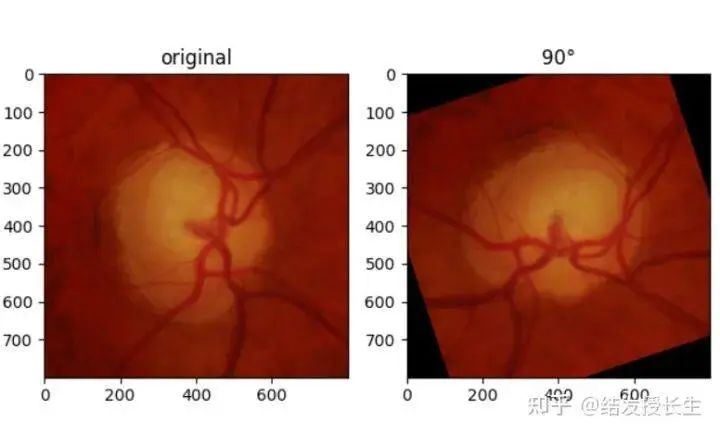
随机旋转
设计角度旋转图像
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
rotated_imgs = [T.RandomRotation(degrees=90)(orig_img)]
print(rotated_imgs)
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('90°')
ax2.imshow(np.array(rotated_imgs[0]))
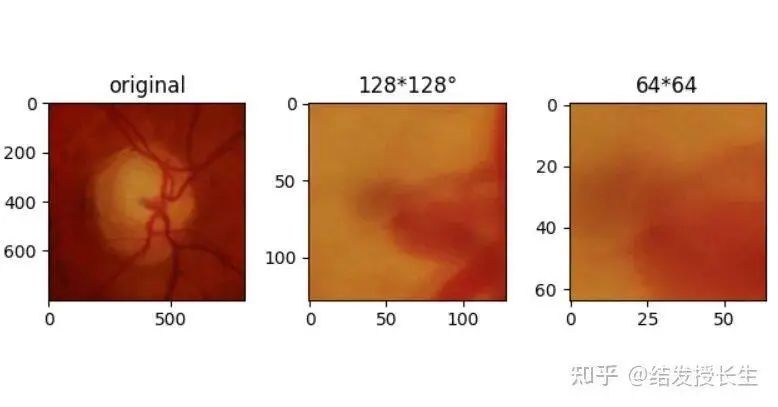
中心剪切
剪切图像的中心区域
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
center_crops = [T.CenterCrop(size=size)(orig_img) for size in (128,64)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('128*128°')
ax2.imshow(np.array(center_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('64*64')
ax3.imshow(np.array(center_crops[1]))
plt.show()
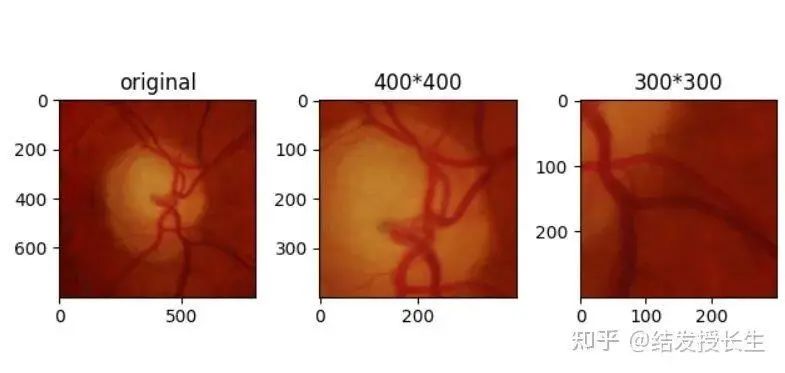
随机裁剪
随机剪切图像的某一部分
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
random_crops = [T.RandomCrop(size=size)(orig_img) for size in (400,300)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('400*400')
ax2.imshow(np.array(random_crops[0]))
ax3 = plt.subplot(133)
ax3.set_title('300*300')
ax3.imshow(np.array(random_crops[1]))
plt.show()
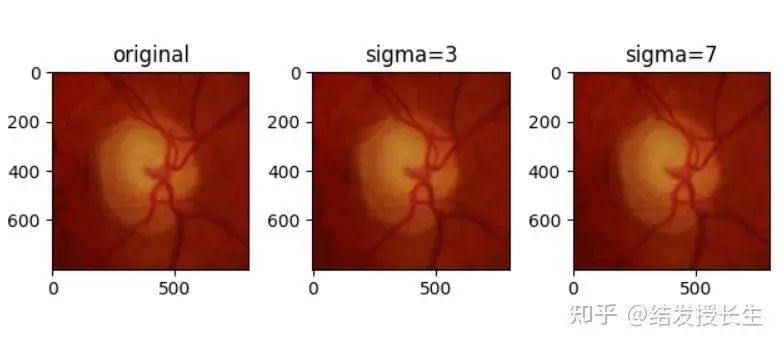
高斯模糊
使用高斯核对图像进行模糊变换
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
blurred_imgs = [T.GaussianBlur(kernel_size=(3, 3), sigma=sigma)(orig_img) for sigma in (3,7)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('sigma=3')
ax2.imshow(np.array(blurred_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('sigma=7')
ax3.imshow(np.array(blurred_imgs[1]))
plt.show()
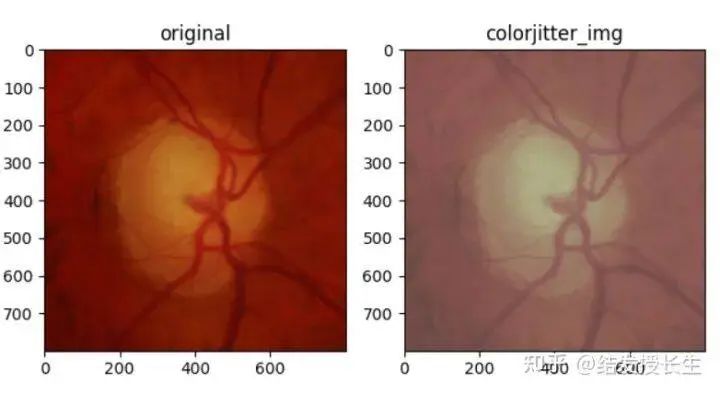
亮度、对比度和饱和度调节
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
# random_crops = [T.RandomCrop(size=size)(orig_img) for size in (832,704, 256)]
colorjitter_img = [T.ColorJitter(brightness=(2,2), contrast=(0.5,0.5), saturation=(0.5,0.5))(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('colorjitter_img')
ax2.imshow(np.array(colorjitter_img[0]))
plt.show()
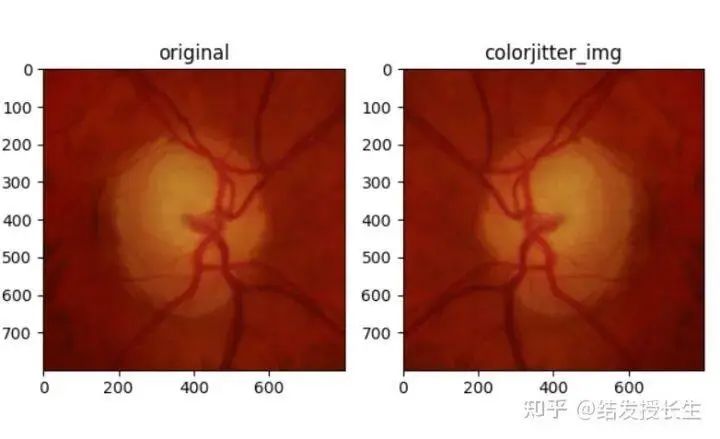
水平翻转
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
HorizontalFlip_img = [T.RandomHorizontalFlip(p=1)(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('colorjitter_img')
ax2.imshow(np.array(HorizontalFlip_img[0]))
plt.show()
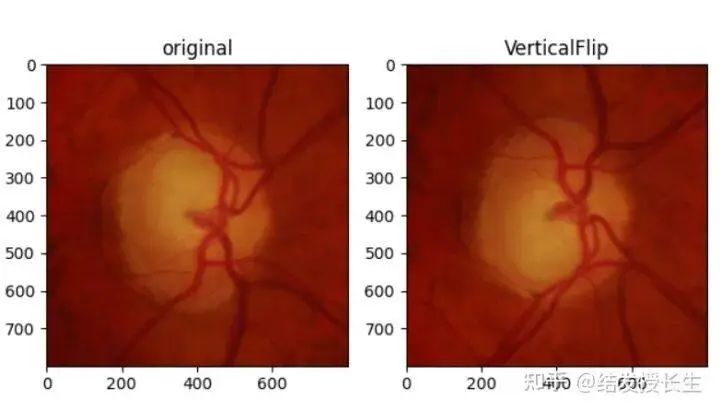
垂直翻转
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
VerticalFlip_img = [T.RandomVerticalFlip(p=1)(orig_img)]
plt.figure('resize:128*128')
ax1 = plt.subplot(121)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(122)
ax2.set_title('VerticalFlip')
ax2.imshow(np.array(VerticalFlip_img[0]))
# ax3 = plt.subplot(133)
# ax3.set_title('sigma=7')
# ax3.imshow(np.array(blurred_imgs[1]))
plt.show()
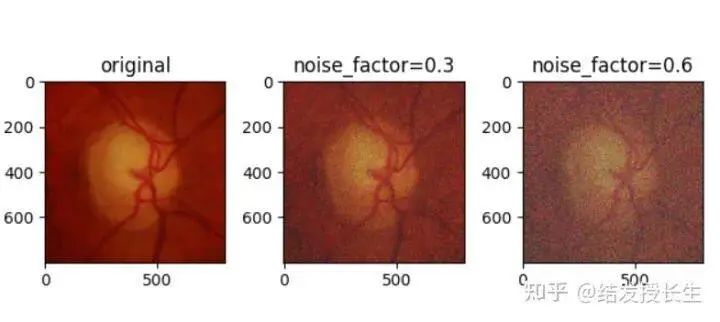
高斯噪声
向图像中加入高斯噪声。通过设置噪声因子,噪声因子越高,图像的噪声越大。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_noise(inputs, noise_factor=0.3):
noisy = inputs + torch.randn_like(inputs) * noise_factor
noisy = torch.clip(noisy, 0., 1.)
return noisy
noise_imgs = [add_noise(T.ToTensor()(orig_img), noise_factor) for noise_factor in (0.3, 0.6)]
noise_imgs = [T.ToPILImage()(noise_img) for noise_img in noise_imgs]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('noise_factor=0.3')
ax2.imshow(np.array(noise_imgs[0]))
ax3 = plt.subplot(133)
ax3.set_title('noise_factor=0.6')
ax3.imshow(np.array(noise_imgs[1]))
plt.show()
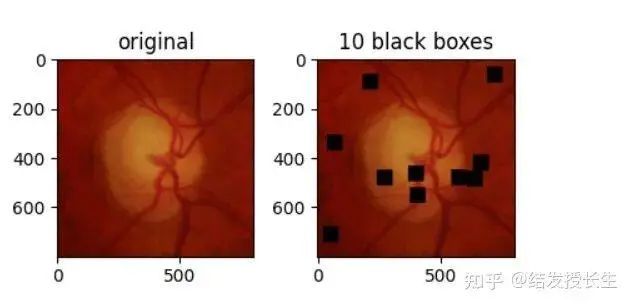
随机块
正方形补丁随机应用在图像中。这些补丁的数量越多,神经网络解决问题的难度就越大。
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_random_boxes(img,n_k,size=64):
h,w = size,size
img = np.asarray(img).copy()
img_size = img.shape[1]
boxes = []
for k in range(n_k):
y,x = np.random.randint(0,img_size-w,(2,))
img[y:y+h,x:x+w] = 0
boxes.append((x,y,h,w))
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
blocks_imgs = [add_random_boxes(orig_img,n_k=10)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('10 black boxes')
ax2.imshow(np.array(blocks_imgs[0]))
plt.show()
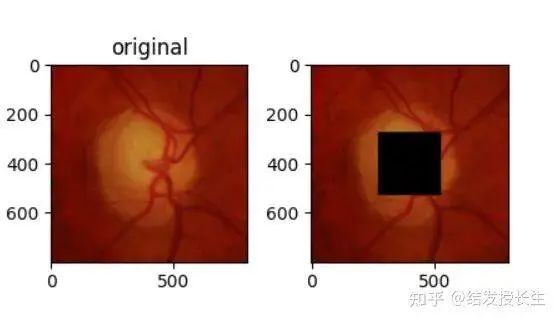
中心区域
和随机块类似,只不过在图像的中心加入补丁
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import sys
import torch
import numpy as np
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
orig_img = Image.open(Path('image/2.png'))
def add_central_region(img, size=32):
h, w = size, size
img = np.asarray(img).copy()
img_size = img.shape[1]
img[int(img_size / 2 - h):int(img_size / 2 + h), int(img_size / 2 - w):int(img_size / 2 + w)] = 0
img = Image.fromarray(img.astype('uint8'), 'RGB')
return img
central_imgs = [add_central_region(orig_img, size=128)]
plt.figure('resize:128*128')
ax1 = plt.subplot(131)
ax1.set_title('original')
ax1.imshow(orig_img)
ax2 = plt.subplot(132)
ax2.set_title('')
ax2.imshow(np.array(central_imgs[0]))
#
# ax3 = plt.subplot(133)
# ax3.set_title('20 black boxes')
# ax3.imshow(np.array(blocks_imgs[1]))
plt.show()
 本 文仅 做学 术分享,如有侵权,请联系 删文。
本 文仅 做学 术分享,如有侵权,请联系 删文。
往期
精彩
回顾
- 适合初学者入门人工智能的路线及资料下载
- (图文+视频)机器学习入门系列下载
- 机器学习及深度学习笔记等资料打印
- 《统计学习方法》的代码复现专辑
-
机器学习交流qq群772479961,加入微信群请 扫码 -
评论