
基于GAN来做低光照图像增强,EnlightenGAN论文解读
【GiantPandaCV导语】本文主要对2021年IEEE TRANSACTIONS ON IMAGE PROCESSING中由德克萨斯A&M大学和华中科技大学联合发表的EnlightenGAN论文进行解读,从研究背景、网络结构、损失函数、实验结果方面对其进行简要介绍。论文地址:(https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9334429)
引言
传统的低光图像增强方法大多都是基于直方图均衡化和基于Retinex理论的方法,基于直方图均衡化的方法通过改变图像的直方图来改变图像中各像素的灰度来增强图像的对比度,例如亮度保持直方图均衡化(BBHE)、对比度限制自适应直方图均衡化(CLAHE)等;Retinex理论假定人类观察到的彩色图像可以分解为照度图(illumination)和反射图(Reflectance),其中反射图是图像的内在属性,不可更改;Retinex理论通过更改照度图中像素的动态范围以达到增强对比度的目的,如单尺度Retinex(SSR);多尺度Retinex(MSRCR)等。深度学习在计算机视觉领域得到了广泛应用,并取得了非常优异的效果;众多优异的方法,如深度卷积神经网络、GAN等,也已经广泛应用于低光图像增强领域,本文介绍的便是2021年在TIP上发表的基于GAN的低光图像增强方法:EnlightenGAN。
网络简介:
网络结构
EnlightenGAN整体网络结构如下:
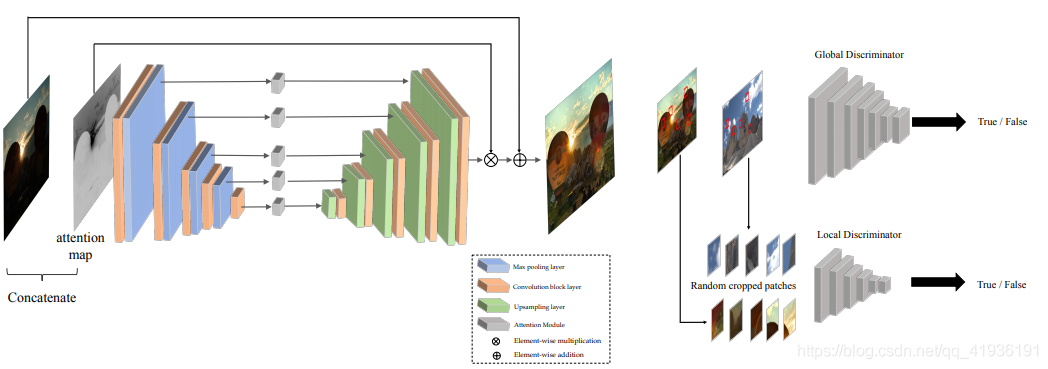
EnlightenGAN采用了注意力导向U-Net网络作为生成器,并采用了双重鉴别器结构来指导全局和局部信息,U-Net网络在各种领域中都取得了显著成就,在文中对U-Net网络结构进行改进,提出了一种注意力导向U-Net网络结构;首先将输入的RGB图像中的照度通道I进行归一化,然后对1-I进行逐元素差分作为自正则化注意力图,随后将所有的注意力图大小重置到与每个特征图相匹配,并与所有中间的特征图相乘得到最后的输出图像;整个注意力导向U-Net生成器包含8个卷积模块,每个卷积模块包含2个3x3的卷积层、LeakyReLu激活函数以及批归一化层(BN),在上采样阶段使用了双线性上采样与卷积层相结合来替代传统的反卷积操作。为了在增强局部区域的同时提升全局亮度,鉴别器则采用了双重鉴别器结构,包含全局和局部鉴别器;全局鉴别器和局部鉴别器都采用了PatchGAN来用于真/假鉴别,除了图像级别的全局鉴别,还通过从输出和真实图像之间随机裁剪局部块来区分真/假以用作局部鉴别。
损失函数
文中的损失函数分为两个部分,第一个为对抗损失,第二个为自特征保留损失;对抗损失部分分为全局损失和局部损失两个部分。在全局鉴别器中采用了新提出的相对鉴别结构,即使用最小二乘GAN来替代原始的Sigmoid以提升鉴别器能力,全局损失函数结构如下:
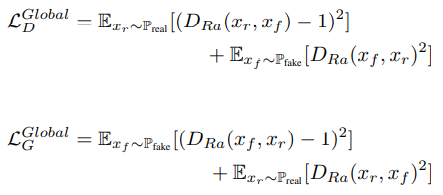
在局部鉴别器中从增强后图像和原始图像中随机剪裁5个图像块来进行真假判断,局部鉴别器选择使用原始的最小二乘GAN来作为对抗损失,局部损失函数结构如下:
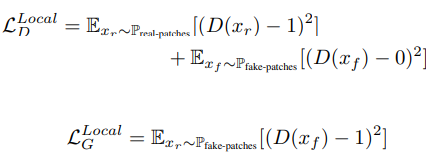
为了限制感知相似性,可以利用感知损失来约束输出图像与真实图像之间的提取出的VGG特征之间的距离来实现,但是由于EnlightenGAN采用的是不成对数据进行训练,因此文中将其改为限制输入图像与对应增强图像之间的特征距离,成为自特征保留损失函数(将原始的Perceptual loss的输入改为低光图像和增强后图像),用于抑制其自正则化能力以保留在增强前和增强后图像自身的内容,文中选择VGG网络第5个Max-Pooling层后的第一个卷积层特征图来计算自特征保留损失;损失函数结构如下:
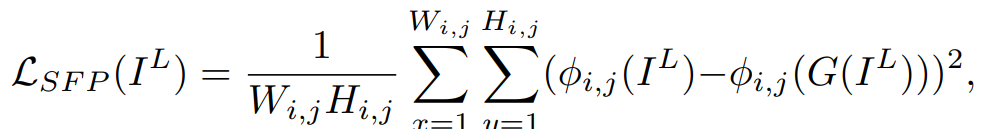
同时在全局和局部鉴别器中也采用了自特征保留损失,因此总体的损失函数结构如下:
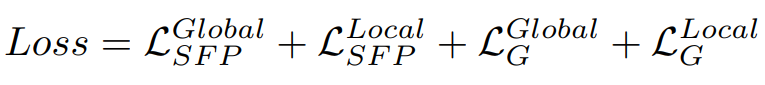
数据集
由于EnlightenGAN采用了不成对图像的训练方式,因此在训练数据集中所包含的低光图像与正常光图像并不需要成对,这使得数据集的采集方式更为简便,文中从各个数据集中收集了914张低光照图像与1016张正常光图像组成数据集;并且将所有图像转换位PNG格式,大小重置为600x400。
实施细节
在训练过程中一共训练了200个epoch,前100个epoch的学习率设置为0.0001,在后100个周期,学习率线性衰减至0;训练过程中采用了Adam优化器并且batch size=32。
实验结果
本文主要进行了四个实验,包括消融实验、人体主观视觉评价测试、各种方法之间的定量评估以及在真实低光图像上的视觉展示。在消融实验部分,主要比较了仅使用全局鉴别器的网络结构、采用没有自正则化注意力机制的U-Net生成器和全版本的EnlightenGAN的结果,实验结果如下:

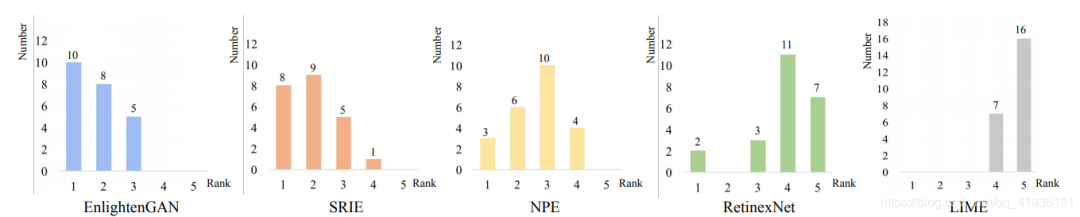
在人体主观视觉评价测试中,选取了9位参与者对经过Retinex-Net、LIME、NPE、SRIE、EnlightenGAN五种方法生成的23幅增强后图像进行打分,实验结果如下:
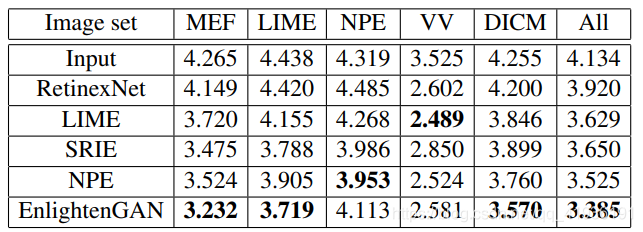
第三个实验是在五个子数据集(MEF、LIME、NPE、VV、DICM)上进行了测试,并采用NIQE进行就定量评估,实验结果如下:
在子数据集上的视觉展示结果如下:

可以看出,EnlightenGAN能够恰当的对图像的全局和局部进行增强,在细节保留上也优于其他的低光增强方法。
最后一个实验是在真实低光图像上对LIME、AHE、EnlightenGAN的输出结果进行了主观视觉展示,实验结果如下:

总结
EnlightenGAN是第一个采用不成对图像进行训练的网络,得到了非常不错的效果,实验结果也证明其性能优于传统的和基于深度学习的SOTA方法;EnlightenGAN的贡献主要包括三点:1、基于生成对抗网络GAN提出了用于低光图像增强的网络结构EnlightenGAN,并且第一次采用了不成对图像进行训练;2、提出了一种双重鉴别器来平衡全局增强和局部增强;3、提出了一种新的自正则化感知损失函数用于模型训练。(如有不同见解可联系:j1269998232@163.com)
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信: