
(附代码)使用Python+Pycaret进行异常检测
点击左上方蓝字关注我们

通过探索性异常检测分析了解异常 设置 PyCaret 环境并尝试准备任务的各种数据 比较性能并可视化不同的异常检测算法
介绍
网络安全 — 监控网络流量并确定异常值 欺诈检测—— 可以识别信用卡欺诈 IT 部门 —发现并应对意外风险 银行业务—— 确定异常交易行为
为什么是 PyCaret?
它是一个灵活的低代码库,可以提高生产力,从而节省时间和精力。 PyCaret 是一个简单易用的机器学习库,使我们能够在几分钟内执行 ML 任务。 PyCaret 库允许自动化机器学习步骤,例如数据转换、准备、超参数调整和标准模型比较。
学习目标
执行探索性异常检测分析 PyCaret 环境介绍 创建和选择最佳模型 比较模型中的异常 可视化和解释模型
PyCaret 安装
pip3 install pycaret
数据导入
导入必要的库
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
导入数据集
from pycaret.datasets import get_data
all_datasets = get_data(‘index’)
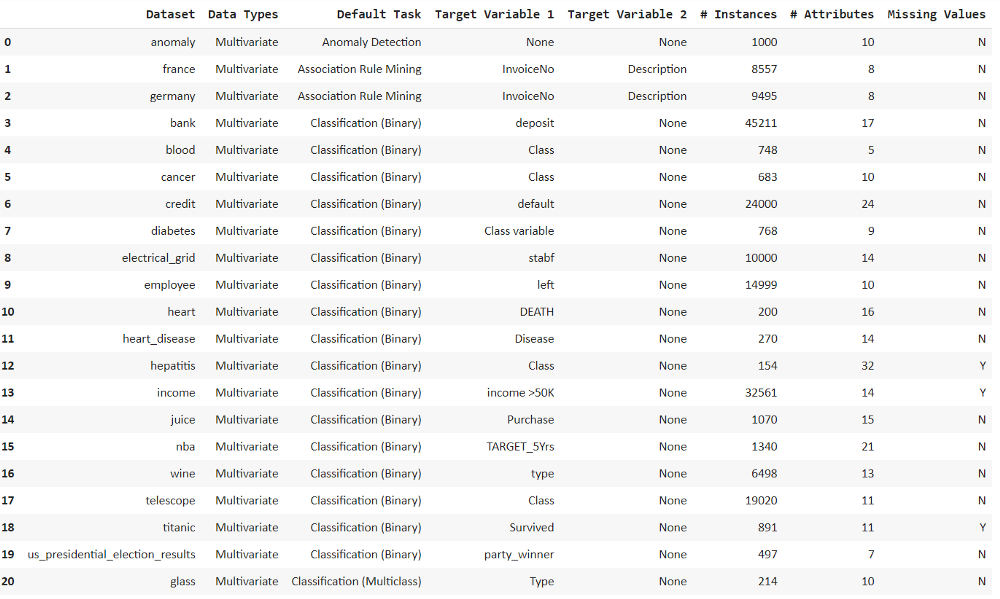
df = get_data(‘anomaly’)
df.head()
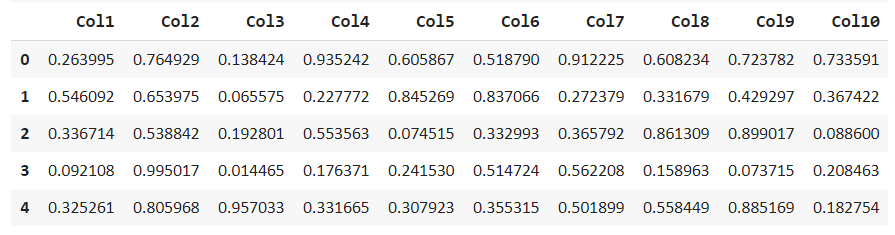
df.describe()
df.info()
探索性异常检测分析
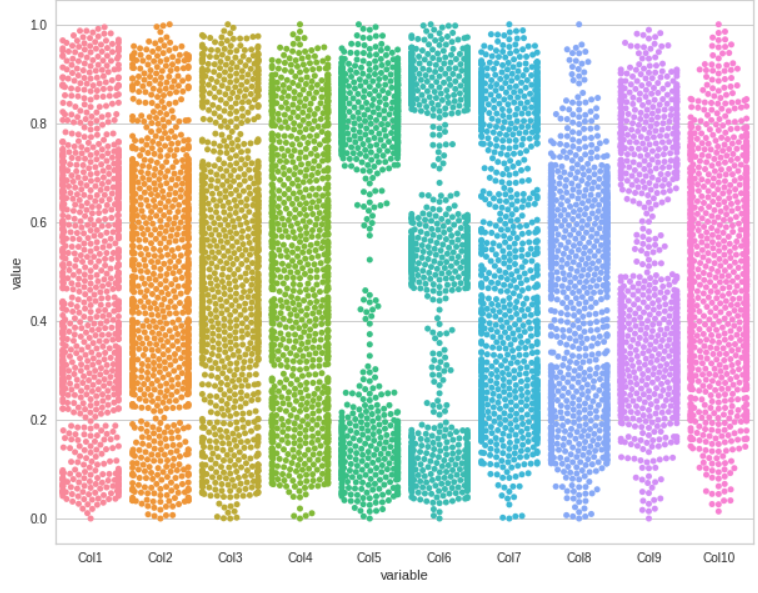
Swarm 图
plt.rcParams["figure.figsize"] = (10,8)
sns.swarmplot(x="variable", y="value", data=pd.melt(df))
plt.show()
箱形图
sns.boxplot(x="variable", y="value", data=pd.melt(df))
plt.show()

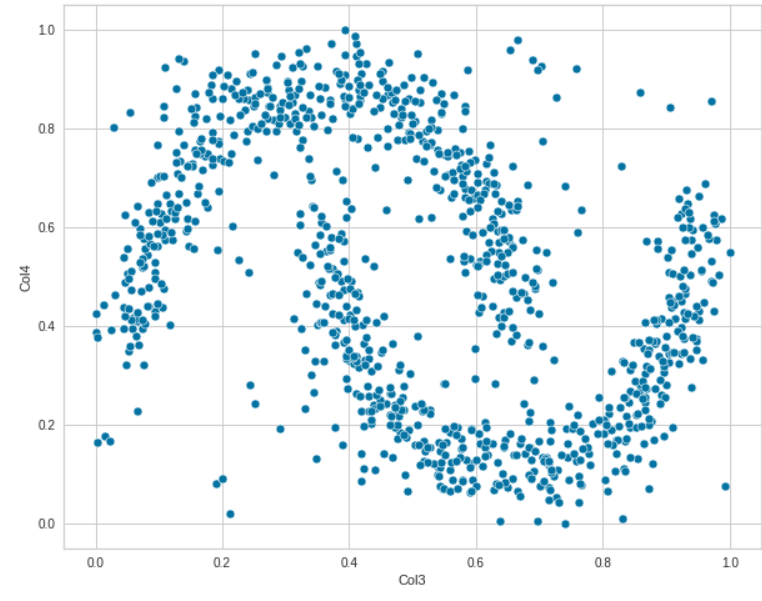
散点图
sns.scatterplot(data=df, x="Col1", y='Col2')

sns.scatterplot(data=df, x="Col3", y='Col4')
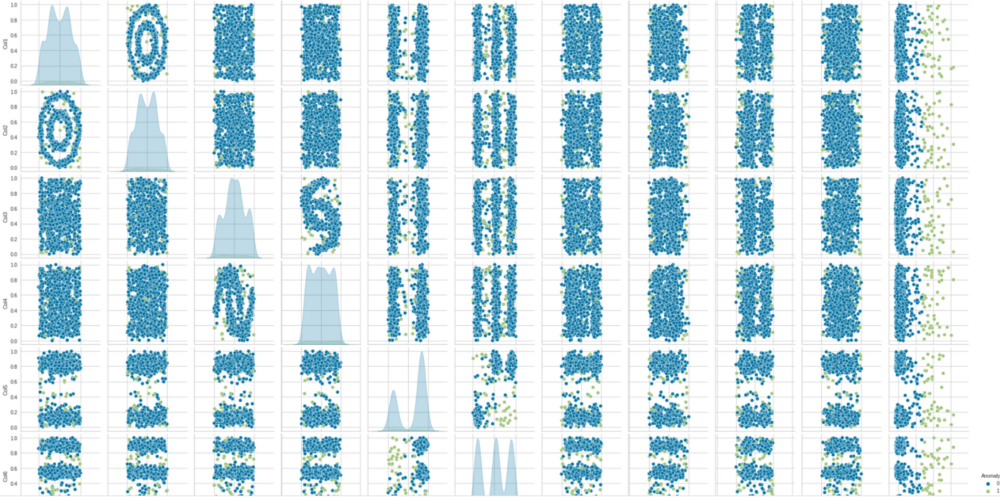
sns.pairplot(df)

df1 = df.melt(‘Col1’, var_name=’cols’, value_name=’vals’)
g = sns.factorplot(x=”Col1", y=”vals”, hue=’cols’, data=df1)
异常检测
from pycaret.anomaly import *
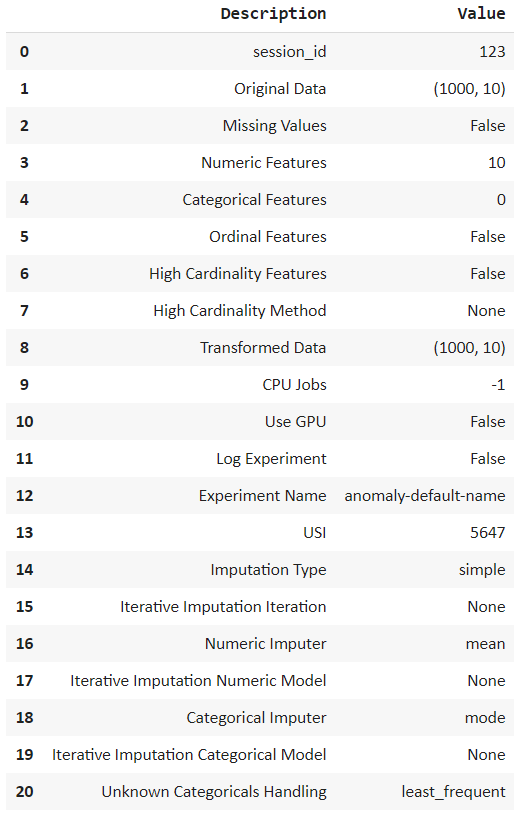
setup = setup(df, session_id = 123)
模型创建
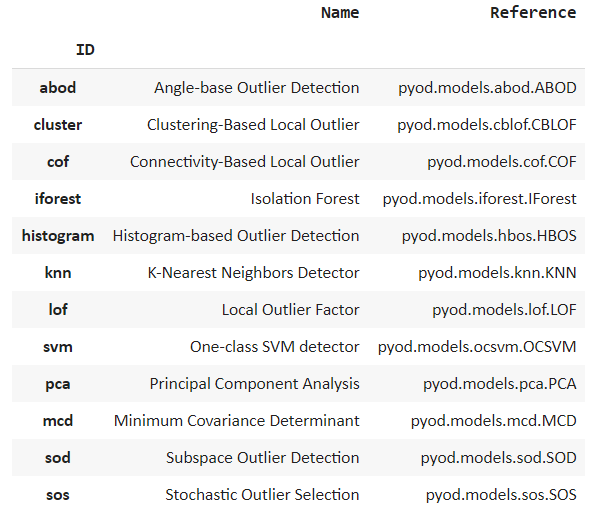
models()
隔离森林
iforest = create_model('iforest')
print(iforest)
局部异常因子
lof = create_model('lof')
print(lof)
K最近邻
knn = create_model('knn')
print(knn)neighbours
比较模型中的异常
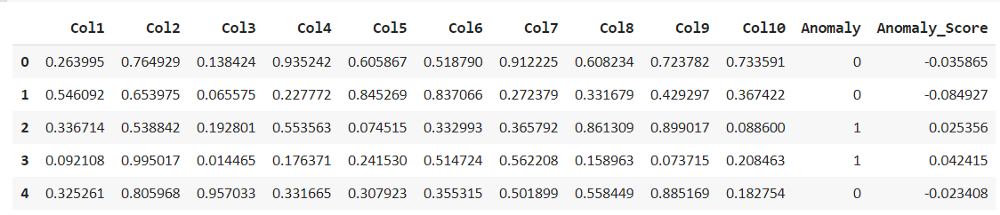
iforest_results = assign_model(iforest)
iforest_results.head()
lof_results = assign_model(lof)
lof_results.head()
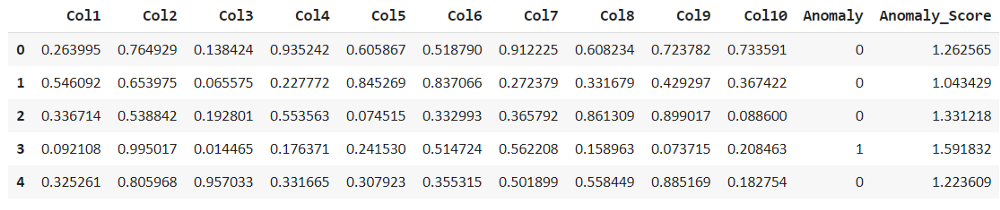
knn_results = assign_model(knn)
knn_results.head()

iforest_anomaly=iforest_results[iforest_results['Anomaly']==1]
iforest_anomaly.shape
lof_anomaly=lof_results[lof_results['Anomaly']==1]
lof_anomaly.shape
knn_anomaly=knn_results[knn_results['Anomaly']==1]
knn_anomaly.shape
解释和可视化
from yellowbrick.features import Manifold
dfr = iforest_results['Anomaly']
viz = Manifold(manifold="tsne")
viz.fit_transform(df, dfr)
viz.show()

plot_model(knn)
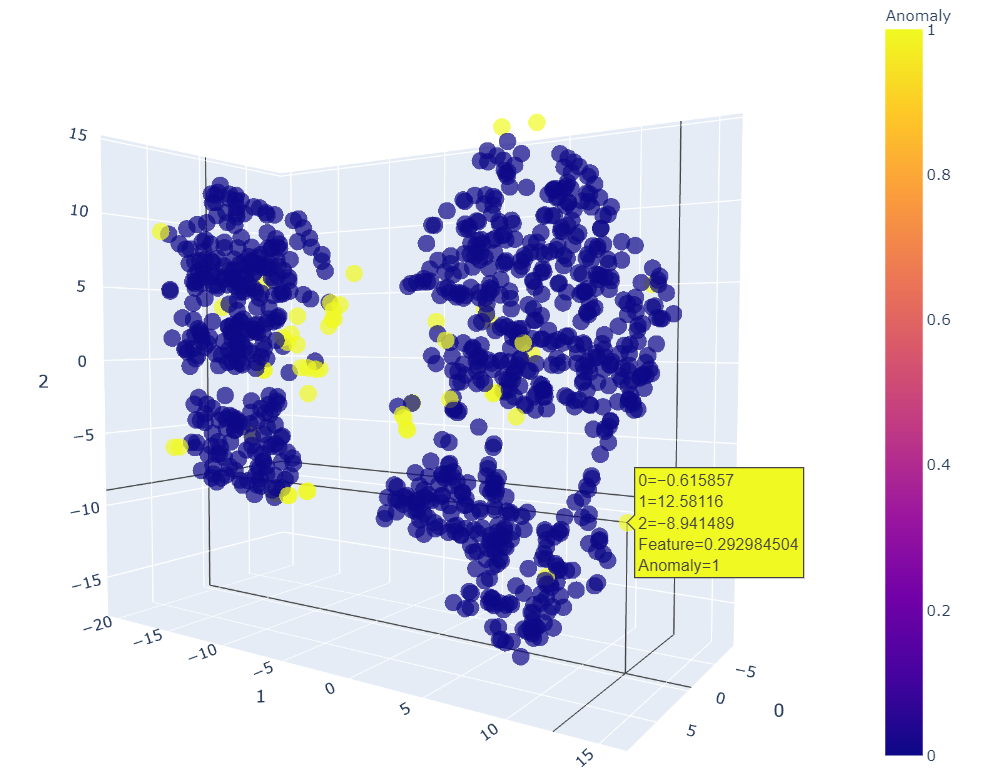
plot_model(iforest)

异常并不总是坏兆头!有时它们在解释结果或数据分析方面非常有用。这些可用于解决不同的数据科学用例。
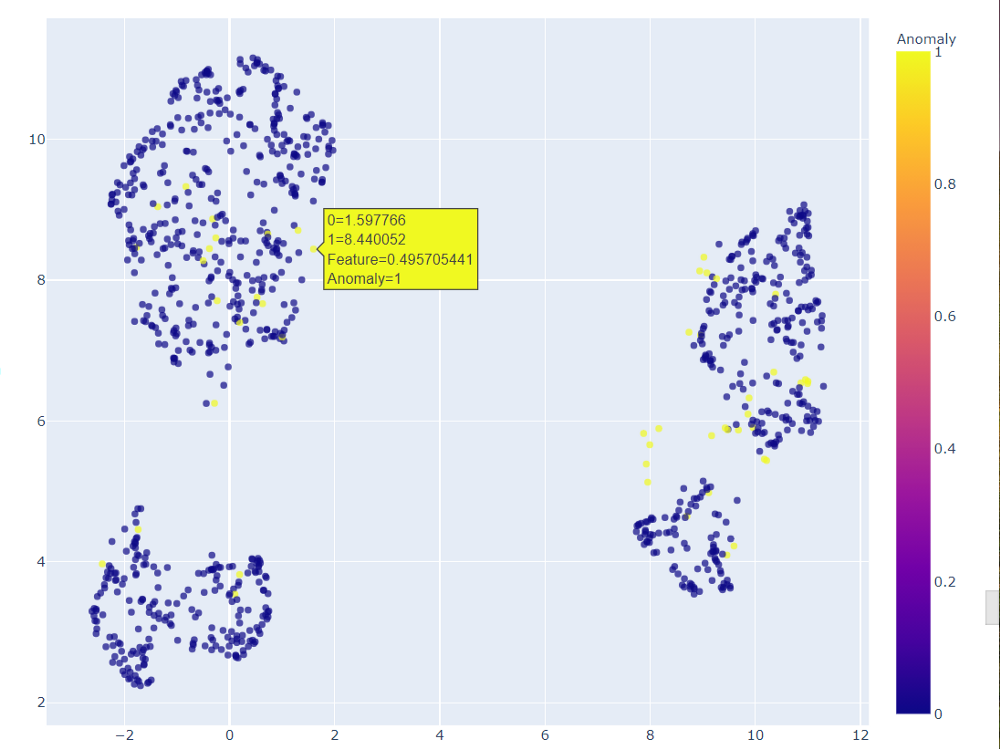
sns.pairplot(lof_results, hue = "Anomaly")
save_model(iforest,'IForest_Model')

尾注
END
整理不易,点赞三连↓
评论