
使用Python+OpenCV进行数据增广方法综述(附代码演练)
点击下面卡片关注“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

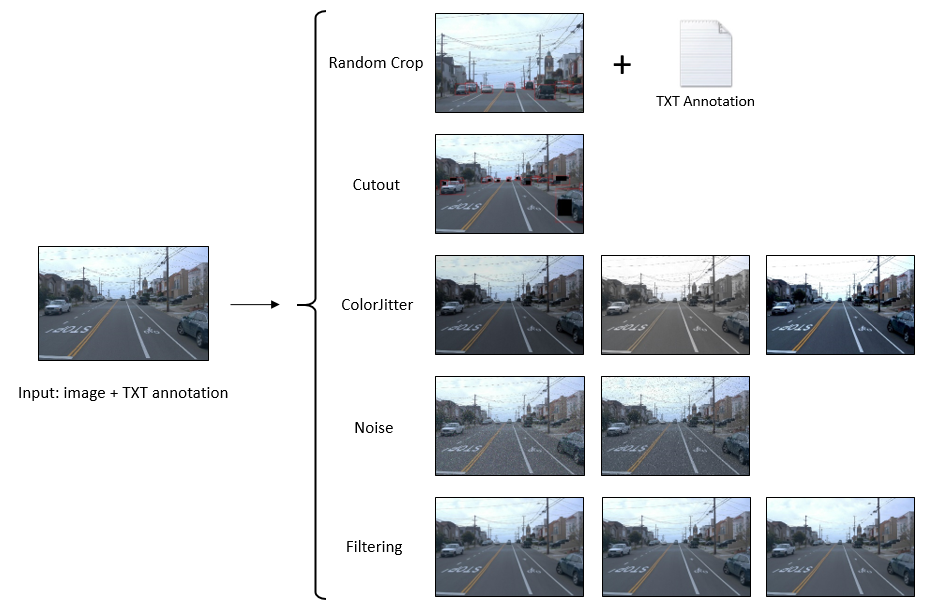
随机剪裁 Cutout ColorJitter 添加噪声 过滤
import os
import cv2
import numpy as np
import random
def file_lines_to_list(path):
'''
### Convert Lines in TXT File to List ###
path: path to file
'''
with open(path) as f:
content = f.readlines()
content = [(x.strip()).split() for x in content]
return content
def get_file_name(path):
'''
### Get Filename of Filepath ###
path: path to file
'''
basename = os.path.basename(path)
onlyname = os.path.splitext(basename)[0]
return onlyname
def write_anno_to_txt(boxes, filepath):
'''
### Write Annotation to TXT File ###
boxes: format [[obj x1 y1 x2 y2],...]
filepath: path/to/file.txt
'''
txt_file = open(filepath, "w")
for box in boxes:
print(box[0], int(box[1]), int(box[2]), int(box[3]), int(box[4]), file=txt_file)
txt_file.close()

随机剪裁

def randomcrop(img, gt_boxes, scale=0.5):
'''
### Random Crop ###
img: image
gt_boxes: format [[obj x1 y1 x2 y2],...]
scale: percentage of cropped area
'''
# Crop image
height, width = int(img.shape[0]*scale), int(img.shape[1]*scale)
x = random.randint(0, img.shape[1] - int(width))
y = random.randint(0, img.shape[0] - int(height))
cropped = img[y:y+height, x:x+width]
resized = cv2.resize(cropped, (img.shape[1], img.shape[0]))
# Modify annotation
new_boxes=[]
for box in gt_boxes:
obj_name = box[0]
x1 = int(box[1])
y1 = int(box[2])
x2 = int(box[3])
y2 = int(box[4])
x1, x2 = x1-x, x2-x
y1, y2 = y1-y, y2-y
x1, y1, x2, y2 = x1/scale, y1/scale, x2/scale, y2/scale
if (x1<img.shape[1] and y1<img.shape[0]) and (x2>0 and y2>0):
if x1<0: x1=0
if y1<0: y1=0
if x2>img.shape[1]: x2=img.shape[1]
if y2>img.shape[0]: y2=img.shape[0]
new_boxes.append([obj_name, x1, y1, x2, y2])
return resized, new_boxes
Cutout
论文地址:https://arxiv.org/abs/1708.04552
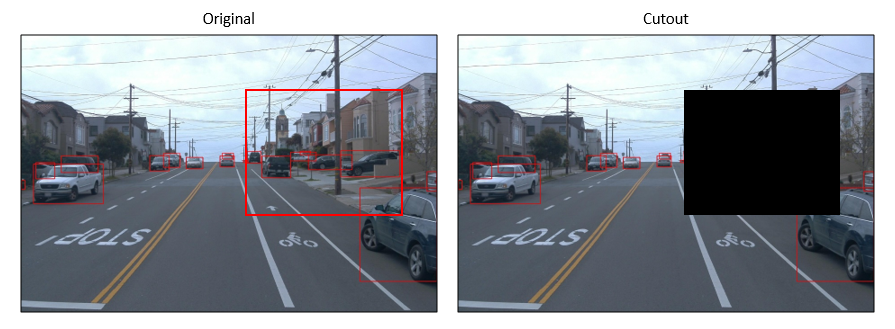
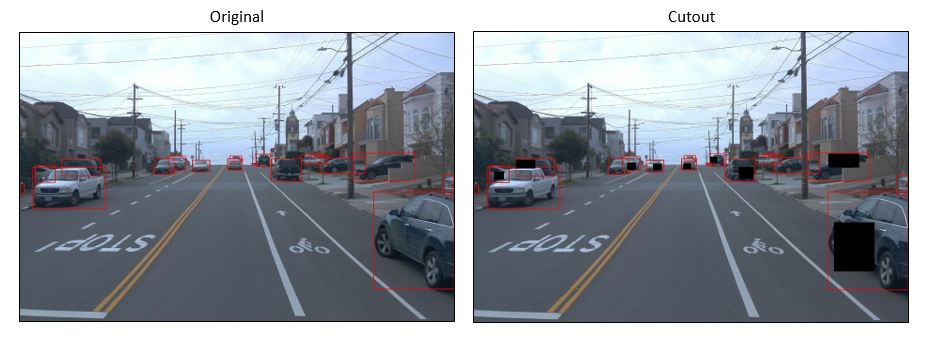
def cutout(img, gt_boxes, amount=0.5):
'''
### Cutout ###
img: image
gt_boxes: format [[obj x1 y1 x2 y2],...]
amount: num of masks / num of objects
'''
out = img.copy()
ran_select = random.sample(gt_boxes, round(amount*len(gt_boxes)))
for box in ran_select:
x1 = int(box[1])
y1 = int(box[2])
x2 = int(box[3])
y2 = int(box[4])
mask_w = int((x2 - x1)*0.5)
mask_h = int((y2 - y1)*0.5)
mask_x1 = random.randint(x1, x2 - mask_w)
mask_y1 = random.randint(y1, y2 - mask_h)
mask_x2 = mask_x1 + mask_w
mask_y2 = mask_y1 + mask_h
cv2.rectangle(out, (mask_x1, mask_y1), (mask_x2, mask_y2), (0, 0, 0), thickness=-1)
return out
ColorJitter

def colorjitter(img, cj_type="b"):
'''
### Different Color Jitter ###
img: image
cj_type: {b: brightness, s: saturation, c: constast}
'''
if cj_type == "b":
# value = random.randint(-50, 50)
value = np.random.choice(np.array([-50, -40, -30, 30, 40, 50]))
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
if value >= 0:
lim = 255 - value
v[v > lim] = 255
v[v <= lim] += value
else:
lim = np.absolute(value)
v[v < lim] = 0
v[v >= lim] -= np.absolute(value)
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
elif cj_type == "s":
# value = random.randint(-50, 50)
value = np.random.choice(np.array([-50, -40, -30, 30, 40, 50]))
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
if value >= 0:
lim = 255 - value
s[s > lim] = 255
s[s <= lim] += value
else:
lim = np.absolute(value)
s[s < lim] = 0
s[s >= lim] -= np.absolute(value)
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
elif cj_type == "c":
brightness = 10
contrast = random.randint(40, 100)
dummy = np.int16(img)
dummy = dummy * (contrast/127+1) - contrast + brightness
dummy = np.clip(dummy, 0, 255)
img = np.uint8(dummy)
return img
添加噪声

def noisy(img, noise_type="gauss"):
'''
### Adding Noise ###
img: image
cj_type: {gauss: gaussian, sp: salt & pepper}
'''
if noise_type == "gauss":
image=img.copy()
mean=0
st=0.7
gauss = np.random.normal(mean,st,image.shape)
gauss = gauss.astype('uint8')
image = cv2.add(image,gauss)
return image
elif noise_type == "sp":
image=img.copy()
prob = 0.05
if len(image.shape) == 2:
black = 0
white = 255
else:
colorspace = image.shape[2]
if colorspace == 3: # RGB
black = np.array([0, 0, 0], dtype='uint8')
white = np.array([255, 255, 255], dtype='uint8')
else: # RGBA
black = np.array([0, 0, 0, 255], dtype='uint8')
white = np.array([255, 255, 255, 255], dtype='uint8')
probs = np.random.random(image.shape[:2])
image[probs < (prob / 2)] = black
image[probs > 1 - (prob / 2)] = white
return image
过滤

def filters(img, f_type = "blur"):
'''
### Filtering ###
img: image
f_type: {blur: blur, gaussian: gaussian, median: median}
'''
if f_type == "blur":
image=img.copy()
fsize = 9
return cv2.blur(image,(fsize,fsize))
elif f_type == "gaussian":
image=img.copy()
fsize = 9
return cv2.GaussianBlur(image, (fsize, fsize), 0)
elif f_type == "median":
image=img.copy()
fsize = 9
return cv2.medianBlur(image, fsize)
总结
https://github.com/tranleanh/data-augmentation
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论