
DeepLabv3:语义图像分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

使用深度卷积神经网络(DCNN)分割图像中的对象的挑战之一是,随着输入特征图遍历网络变得越来越小,有关小范围对象的信息可能会丢失。
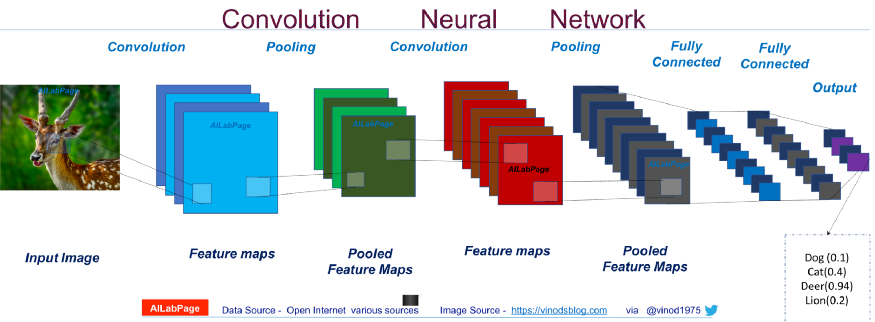
图1.合并和跨步的重复组合会在输入遍历DCNN时降低要素图的空间分辨率
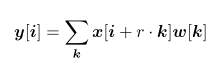
公式1.输出特征图y中位置i的公式,换句话说,图2中绿色矩阵中的正方形之一。x是输入信号,r是原子率,w是滤波器,k是内核
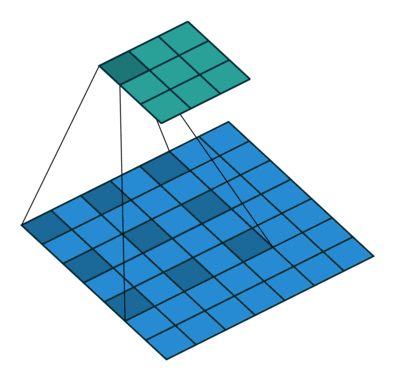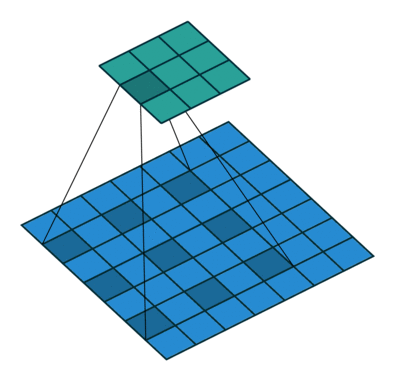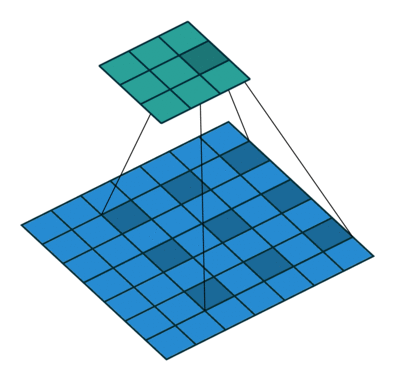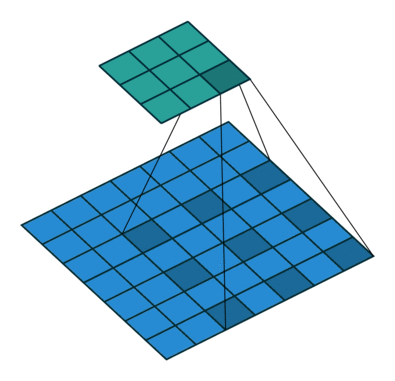
图2.使用3核的粗体二维卷积,粗率为2,没有填充。
作者调整一个名为output_stride的值,该值是输入图像分辨率与输出分辨率之间的比率。比较并结合了三种方法以创建最终方法:Atrous空间金字塔池(ASPP)。第一个是级联卷积,它只是相互进行的卷积。当这些卷积的r = 1时(即开箱即用的卷积),将抽取详细信息,从而使分割变得困难。作者发现,通过允许在DCNN的更深层块中捕获远程信息,使用原子卷积可以改善这种情况。图3展示了“原始” DCNN与级联DCNN的比较,其中r>1无规卷积。
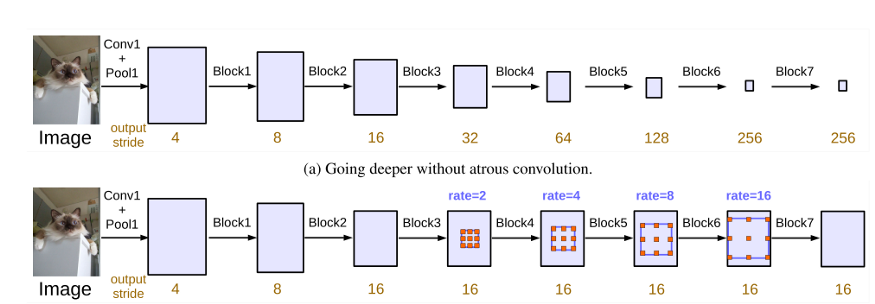
图3.顶部(a)是规则的CNN,第二个(a)是级联的r> 1的atrous卷积,output_stride为16
第二种是多网格方法,即不同大小的网格的层次结构(请参见图4)。他们定义了一个multi_grid参数作为一组空率(r1,r2,r1),它们按顺序应用于三个块。最终原子速率等于单位速率和相应速率的乘积。因此,例如,在output_stride为16且multi_grid为(1,2,4)的情况下,块4(如图3所示)将具有三个卷积,比率为2*((1, 2, 4)=(2, 4,8),
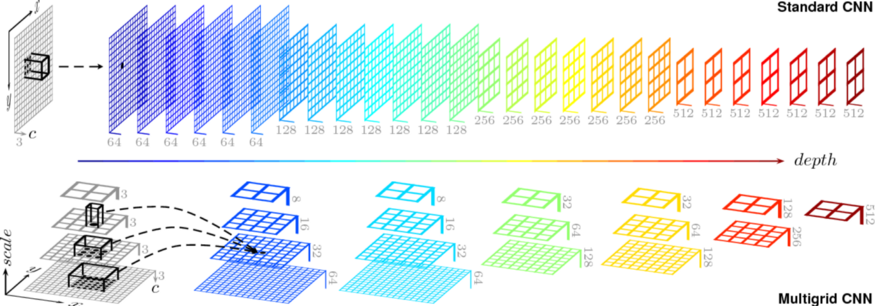
图4.多网格CNN架构
作者的主要贡献是修改了[5]中的Atrous空间金字塔池化(ASPP),该方法在空间“金字塔”池化方法中使用了atrous卷积,以包括批量归一化和图像级特征。他们通过在最后一个特征图上应用全局平均池来实现此目的,如图5(b)所示。然后他们将结果馈送给具有256个滤波器的1x1卷积。最后,他们将特征双线性升采样到所需的空间尺寸。图5中的示例提供了两个输出。输出(a)是3x3卷积,多重网格速率=(6,12,18)。然后,网络将这些输出连接起来,并在生成logit类输出的最终1x1卷积之前通过1x1卷积传递。
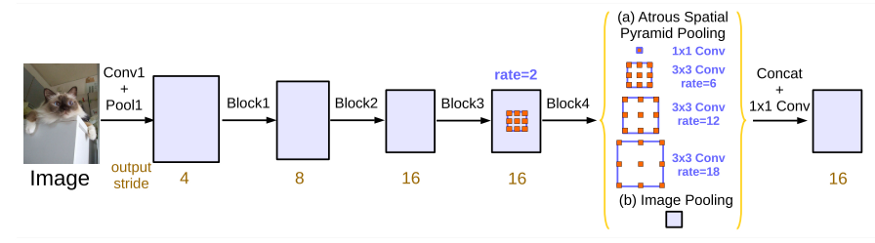
图5.具有无穷卷积的并行模块
为了给这种方法提供支持,他们将级联和多网格ResNet与ASPP进行了比较。结果是:
输出步幅:他们发现,较大的分辨率或较小的output_stride的性能要明显好于无异常卷积或较大的output_stride。他们还发现,在比较output_stride为8(分辨率更高)和output_stride为16的验证集上测试这些网络时,output_stride为8时性能更好。
级联:与常规卷积相比,级联无穷卷积的结果提高了性能。但是,他们发现添加的块越多,改进的余地就越小。
多网格:他们对多网格体系结构的结果相对于“香草”网络确实有所改善,并且在块7处的(r1,r2,r3)=(1、2、1)时表现最佳。
ASPP +多重网格+图像池:随着在多重网格率(R 1,R ₂,- [R ₃)=(1,2,4),使得ASPP(6,12,18)中的模型在77.21米欧表现最佳。在具有多尺度输入的COCO数据集上的output_stride = 8时,该模型在82.70进行了测试,通过将output_stride从16更改为8,可以显示出进一步的改进。
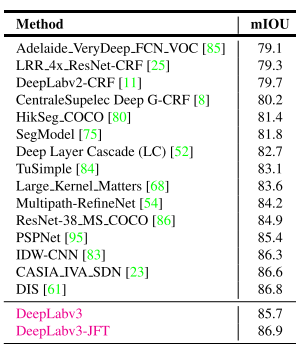
作者提出了一种方法,该方法通过向空间“金字塔”池中的无规卷积层添加批处理规范和图像特征来更新DeepLab的先前版本。结果是网络可以提取密集的特征图以捕获远程上下文,从而提高分割任务的性能。他们提出的模型的结果优于PASCAL VOC 2012语义图像分割基准测试中的最新模型。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~