ANDROID 上的图像分割 DEEPLABV3
介绍
语义图像分割是一项计算机视觉任务,它使用语义标签来标记输入图像的特定区域。PyTorch 语义图像分割DeepLabV3 模型可用于标记具有20 个语义类的图像区域,例如,自行车、公共汽车、汽车、狗和人。图像分割模型在自动驾驶和场景理解等应用中非常有用。
在本教程中,我们将提供有关如何在 Android 上准备和运行 PyTorch DeepLabV3 模型的分步指南,带您从开始拥有一个您可能想要在 Android 上使用的模型到最终拥有一个完整的模型。使用该模型的 Android 应用程序。我们还将介绍如何检查您的下一个良好的预训练 PyTorch 模型是否可以在 Android 上运行以及如何避免陷阱的实用和一般技巧。
笔记
在学习本教程之前,您应该查看适用于 Android 的 PyTorch Mobile并快速尝试一下PyTorch Android HelloWorld示例应用程序。本教程将超越图像分类模型,通常是部署在移动设备上的第一种模型。本教程的完整代码存储库可在此处获得。
学习目标
在本教程中,您将学习如何:
为 Android 部署转换 DeepLabV3 模型。
在 Python 中获取示例输入图像的模型输出,并将其与 Android 应用程序的输出进行比较。
构建一个新的 Android 应用程序或重复使用一个 Android 示例应用程序来加载转换后的模型。
将输入准备为模型期望的格式并处理模型输出。
完成 UI、重构、构建和运行应用程序以查看图像分割的实际效果。
先决条件
PyTorch 1.6 或 1.7
火炬视觉 0.7 或 0.8
已安装 NDK 的 Android Studio 3.5.1 或更高版本
脚步
1.转换DeepLabV3模型用于Android部署
在 Android 上部署模型的第一步是将模型转换为TorchScript格式。
笔记
目前并非所有 PyTorch 模型都可以转换为 TorchScript,因为模型定义可能使用 TorchScript 中没有的语言功能,TorchScript 是 Python 的一个子集。有关更多详细信息,请参阅脚本和优化配方。
只需运行下面的脚本即可生成脚本模型deeplabv3_scripted.pt:
import torch
# use deeplabv3_resnet50 instead of resnet101 to reduce the model size
model = torch.hub.load('pytorch/vision:v0.7.0', 'deeplabv3_resnet50', pretrained=True)
model.eval()
scriptedm = torch.jit.script(model)
torch.jit.save(scriptedm, "deeplabv3_scripted.pt")

生成的deeplabv3_scripted.pt模型文件的大小应该在 168MB 左右。理想情况下,在将模型部署到 Android 应用程序之前,还应该对模型进行量化以显着减小尺寸并加快推理速度。要对量化有一个大致的了解,请参阅量化配方和那里的资源链接。我们将在以后的教程或秘籍中详细介绍如何将称为训练后静态量化的量化工作流正确应用于DeepLabV3 模型。
2.在Python中获取模型的示例输入和输出
现在我们有了一个脚本化的 PyTorch 模型,让我们用一些示例输入进行测试,以确保模型在 Android 上正常工作。首先,让我们编写一个 Python 脚本,使用该模型进行推理并检查输入和输出。对于 DeepLabV3 模型的这个示例,我们可以重用步骤 1 和DeepLabV3 模型中心站点中的代码。将以下代码片段添加到上面的代码中:
from PIL import Image
from torchvision import transforms
input_image = Image.open("deeplab.jpg")
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)['out'][0]
print(input_batch.shape)
print(output.shape)
从这里下载deeplab.jpg,然后运行上面的脚本,您将看到模型的输入和输出的形状:
torch.Size([1, 3, 400, 400])
torch.Size([21, 400, 400])
因此,如果您向Android 上的模型提供大小为 400x400的相同图像输入deeplab.jpg,则模型的输出应具有大小 [21, 400, 400]。您还应该至少打印出输入和输出的实际数据的开始部分,以便在下面的第 4 步中用于与模型在 Android 应用程序中运行时的实际输入和输出进行比较。
3. 构建一个新的 Android 应用程序或重用示例应用程序并加载模型
首先,按照Android 模型准备教程的第 3 步在启用 PyTorch Mobile 的 Android Studio 项目中使用我们的模型。由于本教程中使用的 DeepLabV3 和 PyTorch HelloWorld Android 示例中使用的 MobileNet v2 都是计算机视觉模型,因此您还可以获取HelloWorld 示例 repo,以便更轻松地修改加载模型和处理输入和输出的代码。此步骤和步骤 4 的主要目标是确保步骤 1 中生成的模型deeplabv3_scripted.pt确实可以在 Android 上正常工作。
现在让我们在Android Studio项目中添加第2步使用的deeplabv3_scripted.pt和deeplab.jpg,并修改MainActivity中的onCreate方法类似:
Module module = null;
try {
module = Module.load(assetFilePath(this, "deeplabv3_scripted.pt"));
} catch (IOException e) {
Log.e("ImageSegmentation", "Error loading model!", e);
finish();
}
然后在finish()行设置断点并构建并运行应用程序。如果应用程序没有在断点处停止,则表示步骤 1 中的脚本模型已在 Android 上成功加载。
4. 处理模型输入和输出以进行模型推理
在上一步中加载模型后,让我们验证它是否适用于预期的输入并可以生成预期的输出。由于 DeepLabV3 模型的模型输入是与 HelloWorld 示例中 MobileNet v2 相同的图像,我们将重用HelloWorld 中MainActivity.java文件中的一些代码进行输入处理。将MainActivity.java 中第 50 行和第 73行之间的代码片段替换为以下代码:
final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(bitmap,
TensorImageUtils.TORCHVISION_NORM_MEAN_RGB,
TensorImageUtils.TORCHVISION_NORM_STD_RGB);
final float[] inputs = inputTensor.getDataAsFloatArray();
Map<String, IValue> outTensors =
module.forward(IValue.from(inputTensor)).toDictStringKey();
// the key "out" of the output tensor contains the semantic masks
// see https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101
final Tensor outputTensor = outTensors.get("out").toTensor();
final float[] outputs = outputTensor.getDataAsFloatArray();
int width = bitmap.getWidth();
int height = bitmap.getHeight();
笔记
模型输出是 DeepLabV3 模型的字典,因此我们使用toDictStringKey来正确提取结果。对于其他模型,模型输出也可能是单个张量或张量元组等。
通过上面显示的代码更改,您可以在最终 float[] 输入和最终 float[] 输出之后设置断点,将输入张量和输出张量数据填充到浮点数组,以便于调试。运行应用程序,当它在断点处停止时,将输入和输出中的数字与您在步骤 2 中看到的模型输入和输出数据进行比较,看看它们是否匹配。对于在 Android 和 Python 上运行的模型的相同输入,您应该获得相同的输出。
警告
由于某些 Android 模拟器的浮点实现问题,在 Android 模拟器上运行时,您可能会看到具有相同图像输入的不同模型输出。因此,最好在真实的 Android 设备上测试该应用程序。
到目前为止,我们所做的只是确认我们感兴趣的模型可以像在 Python 中一样在我们的 Android 应用程序中编写脚本并正确运行。到目前为止,我们在 iOS 应用程序中使用模型的步骤消耗了大部分(如果不是大部分)应用程序开发时间,类似于数据预处理是典型机器学习项目中最繁重的提升。
5. 完成 UI、重构、构建和运行应用程序
现在我们已准备好完成应用程序和 UI,以将处理后的结果作为新图像实际查看。输出处理的代码应该是这样的,在Step 4的代码片段末尾添加:
int[] intValues = new int[width * height];
// go through each element in the output of size [WIDTH, HEIGHT] and
// set different color for different classnum
for (int j = 0; j < width; j++) {
for (int k = 0; k < height; k++) {
// maxi: the index of the 21 CLASSNUM with the max probability
int maxi = 0, maxj = 0, maxk = 0;
double maxnum = -100000.0;
for (int i=0; i < CLASSNUM; i++) {
if (outputs[i*(width*height) + j*width + k] > maxnum) {
maxnum = outputs[i*(width*height) + j*width + k];
maxi = i; maxj = j; maxk= k;
}
}
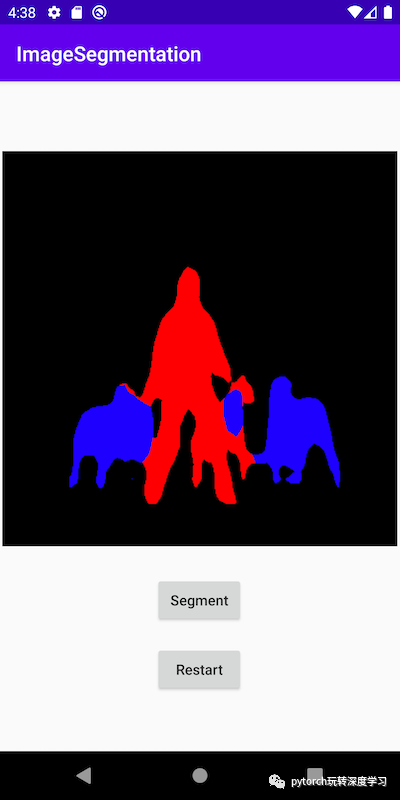
// color coding for person (red), dog (green), sheep (blue)
// black color for background and other classes
if (maxi == PERSON)
intValues[maxj*width + maxk] = 0xFFFF0000; // red
else if (maxi == DOG)
intValues[maxj*width + maxk] = 0xFF00FF00; // green
else if (maxi == SHEEP)
intValues[maxj*width + maxk] = 0xFF0000FF; // blue
else
intValues[maxj*width + maxk] = 0xFF000000; // black
}
}
上面代码中使用的常量定义在类MainActivity的开头:
private static final int CLASSNUM = 21;
private static final int DOG = 12;
private static final int PERSON = 15;
private static final int SHEEP = 17;
这里的实现基于对DeepLabV3模型的理解,该模型为宽*高的输入图像输出大小为[21, width, height]的张量。width*height 输出数组中的每个元素都是一个介于 0 到 20 之间的值(对于介绍中描述的总共 21 个语义标签),该值用于设置特定颜色。这里分割的颜色编码是基于概率最高的类,你可以扩展你自己数据集中所有类的颜色编码。
输出处理后,您还需要调用下面的代码将 RGB intValues数组渲染到位图实例outputBitmap ,然后再将其显示在ImageView 上:
Bitmap bmpSegmentation = Bitmap.createScaledBitmap(bitmap, width, height, true);
Bitmap outputBitmap = bmpSegmentation.copy(bmpSegmentation.getConfig(), true);
outputBitmap.setPixels(intValues, 0, outputBitmap.getWidth(), 0, 0,
outputBitmap.getWidth(), outputBitmap.getHeight());
imageView.setImageBitmap(outputBitmap);
此应用的 UI 也与 HelloWorld 的 UI 类似,只是您不需要TextView来显示图像分类结果。您还可以添加两个按钮Segment和Restart如代码库中所示运行模型推理并在显示分割结果后显示原始图像。
现在,当您在 Android 模拟器或最好是实际设备上运行该应用程序时,您将看到如下屏幕: