
【深度学习】使用深度学习进行手语识别
手语识别是一个多年来一直在研究的问题,然而,我们还远未在我们的社会中找到完整的解决方案。
在为解决这一问题而开展的工作中,大多数工作基本上基于两种方法:基于接触的系统,诸如传感器手套; 或仅使用相机的基于视觉的系统,后者更便宜,而深度学习的蓬勃发展使其更具吸引力。
这篇文章展示了一个使用卷积神经网络的手语双摄像头第一人称视觉翻译系统的原型,文章分为三个主要部分:系统设计、数据集和深度学习模型训练和评估。
视觉是手语的一个关键因素,每一种手语都是为了让一个人在另一个人面前理解,从这个角度来看,一个手势是完全可以观察到的。从另一个角度查看手势会使理解变得困难或几乎不可能,因为无法观察到每个手指的位置和动作。
试图从第一视觉的角度理解手语也有同样的局限性,有些手势最终看起来是一样的。但是,这种模糊性可以通过在不同位置放置更多摄像机来解决。这样,一台相机看不到的东西,可以被另一台相机完美地观察到。
视觉系统由两个摄像头组成:一个头戴式摄像头和一个胸戴式摄像头。使用这两个摄像头,我们可以获得标志的两个不同视图,一个顶视图和一个底视图,它们一起工作以识别标志。

从顶视图和底视图的角度对应于巴拿马手语中的字母 Q 的符号
这种设计的另一个好处是用户将获得自主权。在传统方法中无法实现的功能,即用户不是残疾人,而是需要在手语者做出手语动作时取出带有相机的系统并聚焦手语表达者的第三人。
为了开发该系统的第一个原型,使用了来自巴拿马手册字母表的 24 个静态标志的数据集。
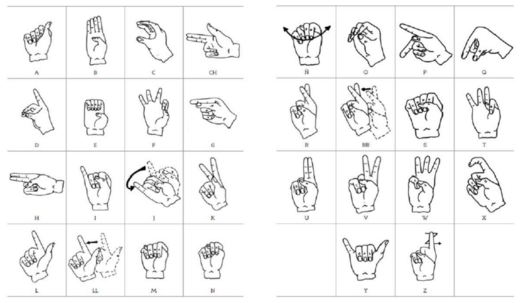
巴拿马语手册字母表
为了将此问题建模为图像识别问题,我们舍弃了字母 J、Z、RR 和 Ñ 等动态手势,因为它们给解决方案增加了额外的复杂性。
为了收集数据集,要求四名用户佩戴视觉系统,并在两台摄像机以640x480像素分辨率记录的同时,执行每一个手势10秒钟。。
要求用户在三种不同的场景中执行此过程:室内、室外和绿色背景场景。对于室内和室外场景,要求用户在执行手势的同时四处走动,以获得具有不同背景、光源和位置的图像。绿色背景场景用于数据增强过程,我们将在后面描述。
获取视频后,提取帧并将其降低到 125x125 像素分辨率。

从左到右:绿色背景场景,室内和室外
数据增强
由于进入卷积神经网络之前的预处理被简化为只是重新缩放,因此背景总是会传递给模型。在这种情况下,模型需要能够识别一个标志,尽管它可能具有不同的背景。
为了提高模型的泛化能力,人为地添加了更多不同背景的图像来代替绿色背景,这样就可以在不投入太多时间的情况下获得更多数据。

具有新背景的图像
在训练期间,还添加了另一个数据增强过程,包括执行一些变换,例如一些旋转、光强度的变化和重新缩放。
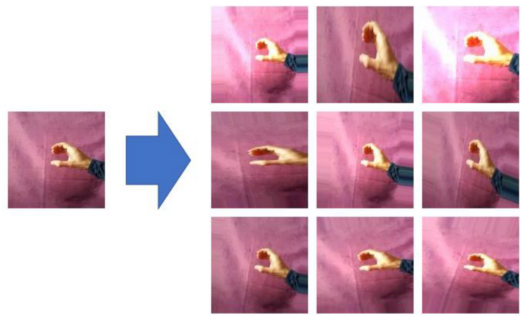
旋转、光强度和重新缩放的变化
选择这两种数据增强过程有助于提高模型的泛化能力。
顶视图和底视图数据集
这个问题被建模为一个包含 24 个类的多类分类问题,问题本身被分成两个较小的多类分类问题。
决定哪些手势将根据顶视图模型进行分类,哪些手势将根据底视图模型进行分类的方法是选择所有从底视图角度看过于相似的手势作为要从顶视图模型进行分类的手势,其余手势将根据底视图模型进行分类。所以基本上,顶视图模型用于解决歧义。
因此,数据集被分为两部分,每个模型一部分,如下表所示。

作为最先进的技术,卷积神经网络是解决这个问题的选择。它训练了两种模型:一种用于顶视图,另一种用于底视图。
建筑学
顶视图和底视图模型都使用了相同的卷积神经网络架构,唯一的区别是输出单元的数量。
卷积神经网络的架构如下图所示。
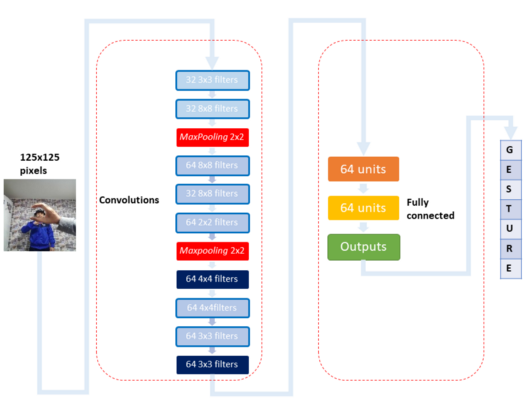
卷积神经网络架构
为了提高模型的泛化能力,在全连接层的层之间使用了 dropout 技术来提高模型性能。
评估
在测试集中使用与系统在室内的正常使用相对应的数据对模型进行评估,换句话说,在背景中,它出现了一个人作为观察者,类似于上图中的输入图像(卷积神经网络架构),结果如下所示。
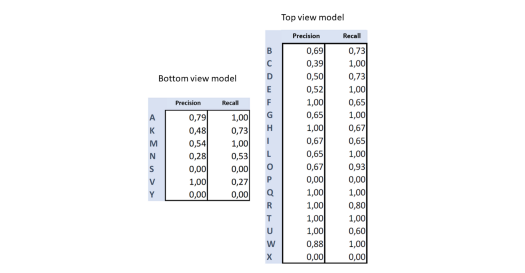
虽然模型学会了对一些符号进行分类,例如 Q、R、H;总的来说,结果不是特别好,看来模型的泛化能力不太好。然而,该模型也通过显示系统潜力的实时数据进行了测试。
底部视图模型使用具有绿色统一背景的实时视频进行测试。当我在笔记本电脑中运行底视图模型时,我戴着胸戴式摄像头以每秒 5 帧的速度拍摄视频,并尝试拼写 fútbol(西班牙语)这个词,通过单击模拟每个字母的条目。
手语识别是一个困难的问题,如果我们考虑所有可能的手势组合,这类系统需要理解和翻译。也就是说,解决这个问题的最好方法可能是将它划分为更简单的问题,而这里介绍的系统将对应于其中一个问题的可能解决方案。
该系统的性能不太好,但已经证明,它可以只用摄像机和卷积神经网络构建第一人称手语翻译系统。
据观察,该模型倾向于将几个符号相互混淆,例如 U 和 W。但是仔细想想,也许它不需要具有完美的性能,因为使用拼写校正器或单词预测器会增加翻译的准确性。
下一步是分析解决方案并研究改进系统的方法,通过收集更多质量数据、尝试更多卷积神经网络架构或重新设计视觉系统来进行一些改进。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: