
使用深度学习进行自动车牌检测和识别
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在现代世界的不同方面,信息技术的大规模集成导致了将车辆视为信息系统中的概念资源。由于没有任何数据,自主信息系统就没有任何意义,因此需要在现实和信息系统之间改革车辆信息。这可以通过人工代理或特殊智能设备实现,这些设备将允许在真实环境中通过车辆牌照识别车辆。在智能设备中,,提到了车辆牌照检测和识别系统。车辆牌照检测和识别系统用于检测车牌,然后识别车牌,即从图像中提取文本,所有这一切都归功于使用定位算法的计算模块,车牌分割和字符识别。车牌检测和读取是一种智能系统,由于其在以下几个领域的潜在应用,因此具有相当大的潜力:
1.指挥部队:该系统用于检测被盗和搜查的车辆,将检测到的车牌与报告车辆的车牌进行比较。
2.道路安全:该系统用于检测超过一定速度的车牌,将车牌读取系统与道路雷达耦合。
3.停车管理:车辆进出口的管理。
为了检测许可证,我们将使用基于卷积神经网络的Yolo(You Only Look One)深度学习对象检测体系结构。该体系结构是由Joseph Redmon、Ali Farhadi、Ross Girshick和Santosh Divvala于2015年推出的第一个版本,以及更高版本2和3。
论文链接:
Yolo v1:https://arxiv.org/pdf/1506.02640.pdf
Yolo v2:https://arxiv.org/pdf/1612.08242.pdf
Yolo v3:https://arxiv.org/pdf/1804.02767.pdf
Yolo是一个经过端到端训练的单一网络,用于执行预测对象边界框和对象类的回归任务。这个网络速度非常快,它以每秒45帧的速度实时处理图像。一个较小的网络版本Fast YOLO每秒处理155帧,速度惊人。
实现YOLO V3:
首先,我们准备了一个由700张包含突尼斯车牌的汽车图像组成的数据集,对于每张图像,我们使用一个名为LabelImg的桌面应用程序创建一个xml文件(之后更改为文本文件,其中包含与Darknet配置文件输入兼容的坐标。Darknet:project用于重新培训YOLO预训练模型)。
First download Darknet projectgit clone https://github.com/pjreddie/darknet.gitin "darknet/Makefile" put affect 1 to OpenCV, CUDNN and GPU if you # want to train with you GPU then time thos two commandscd darknetmakeLoad convert.py to change labels (xml files) into the appropriate # format that darknet understand and past it under darknet/https://github.com/GuiltyNeuron/ANPRUnzip the datasetunzip dataset.zipCreate two folders, one for the images and the other for labelsmkdir darknet/imagesmkdir darknet/labelsConvert labels format and create files with location of imagesfor the test and the trainingpython convert.pyCreate a folder under darknet/ that will contain your datamkdir darknet/customMove files train.txt and test.txt that contains data path tocustom foldermv train.txt custom/mv test.txt custom/Create file to put licence plate class name "LP"touch darknet/custom/classes.namesecho LP > classes.namesCreate Backup folder to save weightsmkdir custom/weightsCreate a file contains information about data and cfgfiles locationstouch darknet/custom/darknet.datain darknet/custom/darknet.data file paste those informationsclasses = 1train = custom/train.txtvalid = custom/test.txtnames = custom/classes.namesbackup = custom/weights/Copy and paste yolo config file in "darknet/custom"cp darknet/cfg/yolov3.cfg darknet/customOpen yolov3.cfg and change :" filters=(classes + 5)*3" just the ones before "Yolo"in our case classes=1, so filters=18change classes=... to classes=1Download pretrained modelwget https://pjreddie.com/media/files/darknet53.conv.74 -O ~/darknet/darknet53.conv.74Let's train our model !!!!!!!!!!!!!!!!!!!!!./darknet detector train custom/darknet.data custom/yolov3.cfg darknet53.conv.74
完成训练后,要从图像中检测发光板,请从darknet/custom/weights中选择最新的模型,并将其路径或名称放入object_detection_yolo.py文件中,我们还将使用yolov3.cfg文件,仅在该文件中,在训练前放入,以便我们可以先删除训练,然后运行:
python object-detection_yolo.py --image= image.jpg运行结果:

现在我们必须分段我们的车牌号,输入是板的图像,我们必须能够提取单字符图像。这一步骤的结果作为识别阶段的输入非常重要。在自动读取车牌的系统中。分割是车牌自动识别最重要的过程之一,因为任何其他步骤都是基于分割的。如果分割失败,识别阶段将不正确。为确保正确分割,必须执行初步处理。
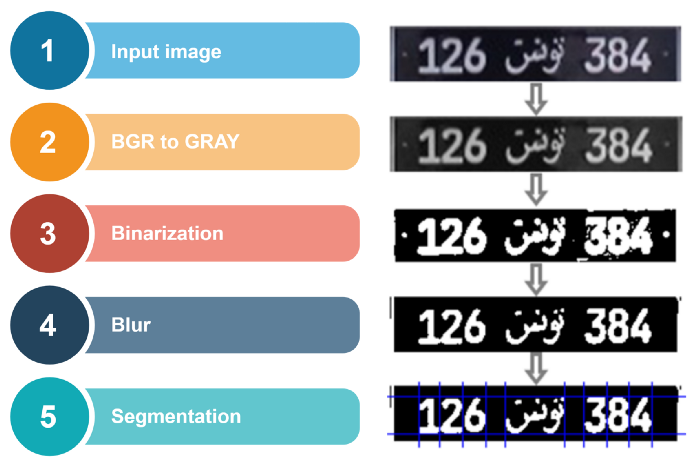
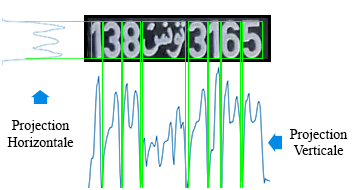
像素投影直方图包括查找每个字符的上下限、左下限和右上限,我们操作水平投影以查找字符的顶部和底部位置,一组直方图的值是沿水平方向上特定线的白色像素的总和。当所有的值沿水平方向的所有直线进行计算,得到水平投影直方图。然后将直方图的平均值用作阈值,以确定上限和下限。直方图分段大于阈值的中心区域记录为由上限和下限分隔的区域。然后,我们以同样的方式计算垂直投影直方图,但通过按图像的列更改行,使每个字符具有两个限制(左和右)。
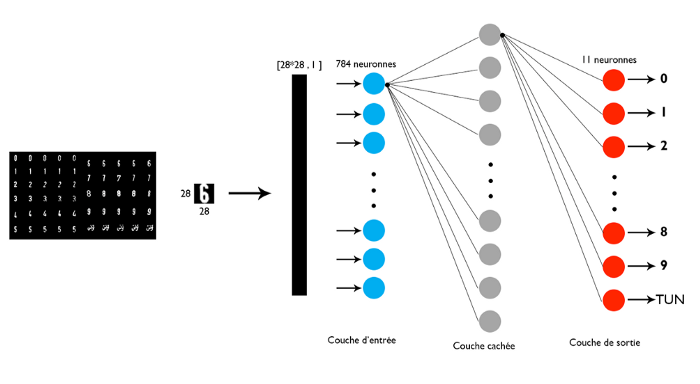
识别阶段是自动车牌阅读器系统开发的最后一步。因此,它关闭图像采集过程中经过的所有过程,然后是板的位置,直到分割。识别必须从分割阶段结束时获得的图像中提取字符。用于此识别的学习模型必须能够读取图像并渲染相应的字符。
为了最大限度地利用可用于学习的数据,我们在应用车牌分割之前使用的相同图像处理步骤后,通过在正方形中调整每个字符的大小来单独切割每个字符。结果,我们获得了一组由11个类组成的数据,对于每个类,我们有30-40张28X28像素尺寸的PNG格式的图像;从0到9的数字和阿拉伯语单词(突尼斯)。
然后,我们在科学论文的基础上对多层感知器(MLP)和分类器K近邻(KNN)进行了比较研究。结果我们发现:如果使用MLP分类器时隐层神经元的数量也增加,并且如果使用KNN时最近邻数也增加,则性能会提高。在这里,调整k-NN分类器性能的能力非常有限。但是,可调整的隐藏层数量和可调整的MLP连接权重为细化决策区域提供了更大的机会。因此,我们将在此阶段选择多层感知器。
本文代码Github链接:
https://github.com/GuiltyNeuron/ANPR
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~