
【NLP】Sentence-T5|谷歌提出文本表示新SOTA
卷友们好,我是rumor。
又出新SOTA了。
每个新SOTA,都意味着下一位要卷得更辛苦、调得更猛烈一些。
而这个SOTA还出在我一直关注的文本表示赛道。

这次谷歌用了T5,把STS的平均分从82.52提到了83.34。

题目:Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
地址:https://arxiv.org/abs/2108.08877
模型结构
乍一看题目还是蛮期待的,用T5做文本表示,会不会玩出什么花来?不过读了之后有些略微调低期望,这篇文章提出了三种从T5拿文本表示的方法:
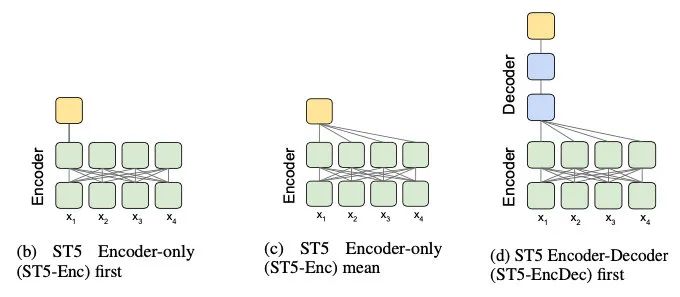
直接拿encoder输出的第一个token表示,类似CLS,但由于T5在训练时就没有CLS,实验下来效果不好就去掉了 直接拿encoder输出的mean pooling,实验下来发现这个最好,不精调的时候也比BERT的好很多,作者分析是T5更多的训练数据+预训练时加了下游任务 拿decoder的第一个输出,直接用不太好,但精调后还可以,作者分析是这个相当于加了attention pooling
有监督Loss
精调时采用了双塔结构,比以往不同的是多加了一层投影和L2-Norm。
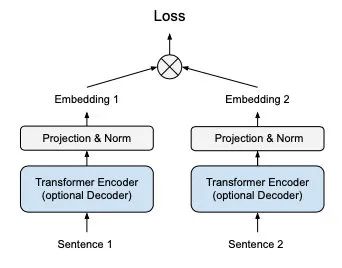
在精调时参考了对比学习的NT-Xent loss,但输入的都是有监督数据(不用对比学习的数据增强了,直接输入有标注的正负样本)。
同时提出了tow-stage的精调:先用网上挖掘的20亿弱监督QA对精调,再用NLI精调(entailment=1,contradict=0)。
实验结果
除了在STS上对比之外,还在SentEval上进行了实验(给表示加一个分类器,测试embedding迁移到下游任务的效果):
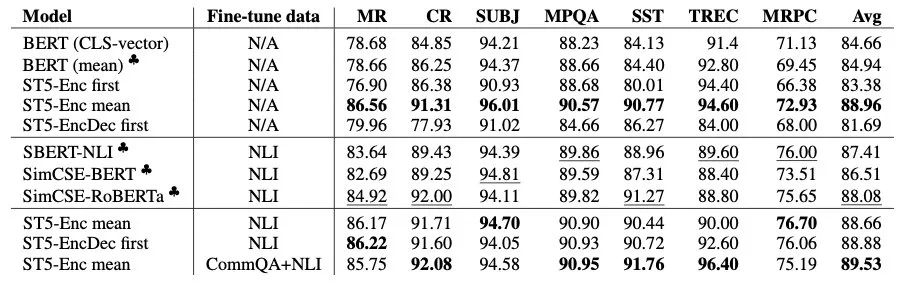
最终加了其他数据的Sentence-T5以不到1个点的微弱优势登上SOTA。
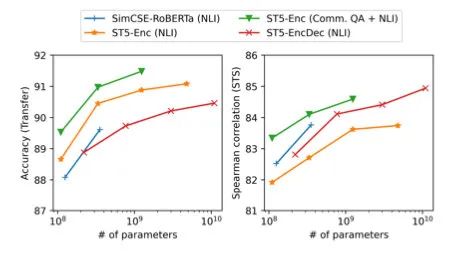
同时作者验证了尺寸越大效果越好:
总结
看得出来我这篇文章写得不是很快乐,主要是感觉新意比较有限,懒穷的我可能也不会去挖20亿的数据,也没有卡去跑更大的模型。

不过!还是有几点启发可以分享一下:
作者加了Proj&Norm层但是没有做消融实验,这个对效果究竟有多少影响呢? 作者在对比loss上的temperature=100,之前无监督对比学习的T都很小,这是为什么呢? 最近一直在想prompt learning怎么用来做文本表示,而T5天生就契合prompt,既然作者证实了decoder精调后是可以用的,那是不是。。。
往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论