 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
本文转自机器之心
在这篇论文中,来自谷歌的研究者提出了一种统一各种预训练范式的预训练策略,这种策略不受模型架构以及下游任务类型影响,在 50 项 NLP 任务中实现了 SOTA 结果。
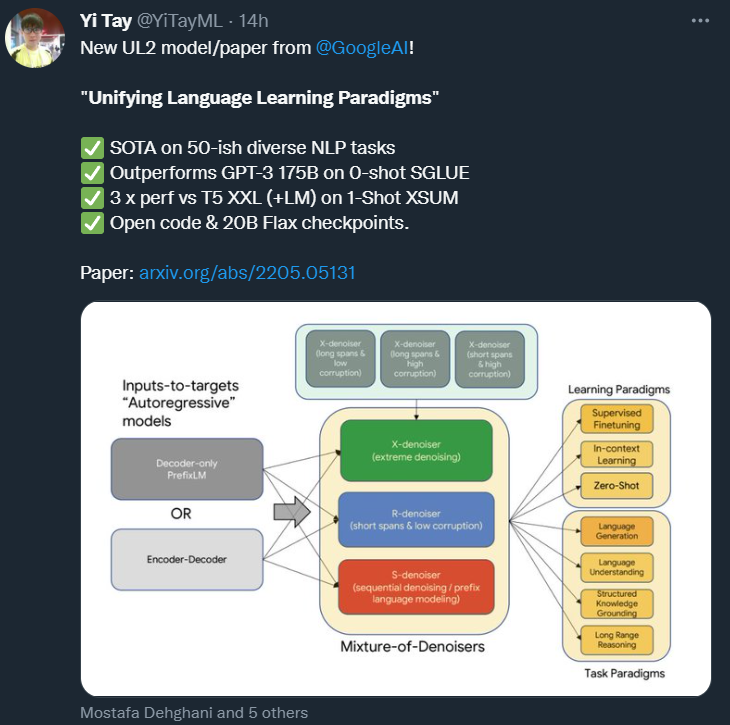
当前,NLP 研究人员和从业者有大量的预训练模型可以选择。在回答应该使用什么模型的问题时,答案通常取决于需要完成什么任务。这个问题并不容易回答,因为涉及许多更细节的问题,例如使用什么样的架构?span corruption 还是语言模型?答案似乎取决于目标下游任务。来自谷歌的研究者重新思考了这一问题,他们具体回答了为什么预训练 LM 的选择要依赖于下游任务,以及如何预训练在许多任务中普遍适用的模型。该研究试图让普遍适用的语言模型成为可能,提出了一个统一的语言学习范式,简称 UL2 框架。该框架在一系列非常多样化的任务和环境中均有效。
如下图 1 所示,与其他需要权衡取舍的模型不同。UL2 模型的性能普遍良好。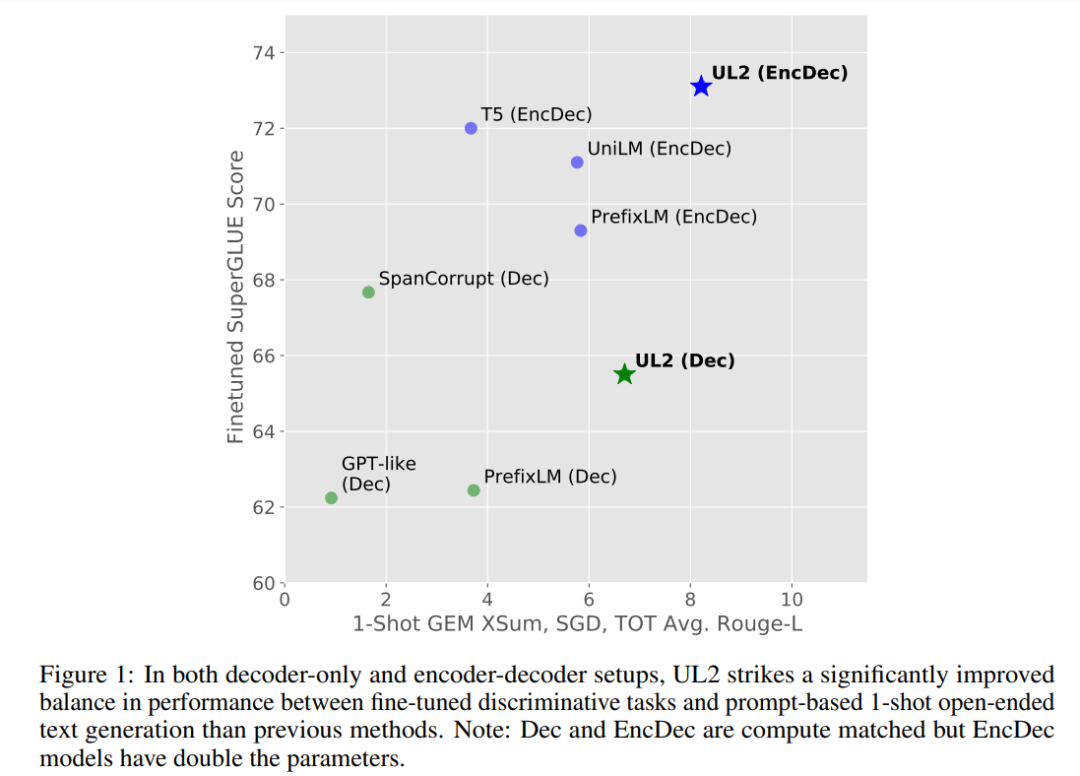
通用模型的优势是显而易见的。有了通用模型,研究者就可以集中精力改进和扩展单个模型,而不是在 N 个模型上分散资源。此外,在只能为少数模型提供资源的受限环境下,最好有一个可以在多种任务上表现良好的预训练模型。UL2 的核心是一种新提出的预训练目标 Mixture-of-Denoisers(MoD),可实现跨任务的强大性能。MoD 是几个成熟的去噪目标和新目标的混合体,包括考虑 extreme span 长度和损坏率的 X-denoising(extreme denoising)、严格遵循序列顺序的 S-denoising(sequential denoising)和标准 span 损坏目标的 R-denoising(regular denoising)。该研究表明,MoD 虽然在概念上很简单,但对于多种任务都非常有效。该方法利用一种思路:对于大多数预训练目标来说,模型所依赖的上下文类型各有不同。例如,span corruption 目标类似于调用前缀语言建模 (PLM) 的多个区域(Liu et al., 2018; Raffel et al., 2019),其中前缀是 non-corrupted token 的连续片段,目标(target)具有所有 PLM 片段前缀的访问权限。span 接近全序列长度的设置可以近似看作一个以长程上下文为条件的语言建模目标。因此,研究者认为可以设计一个预训练目标,将这些不同的范式结合起来( span corruption vs 语言建模 vs 前缀语言建模)。不难看出,每个去噪器(denoiser)的难度不同,其外推或内插的性质也不同。根据 MoD 的公式,研究者推测该模型不仅能在预训练期间区分不同的去噪器,而且在学习下游任务时能自适应地切换模式,这种形式是很有益的。该研究提出了模式切换,这是一个将预训练任务与专用标记 token 相关联的新概念,允许通过离散 prompting 进行动态模式切换。该模型在经过预训练后能够按需在 R、S 和 X 去噪器之间切换模式。然后,研究者将该架构与自监督方案解耦。虽然「预训练模型的主要特征是其主干架构」这一说法可能是一个常见的误解,但研究者发现,denoiser 的选择实际上具有更大的影响。MoD 支持任一主干架构,类似于 T5 的 span corruption 可以用一个 decoder-only 模型来训练。因此,架构的选择对 UL2 影响不大。研究者认为主干架构的选择主要是不同效率指标之间的权衡。研究者在 9 种不同的任务上进行了系统的消融实验,这 9 个任务旨在解决不同的问题。此外,该研究在开放文本生成任务上进行了评估,并在基于 prompt 的单样本环境下对所有任务进行了评估。消融实验的结果表明,UL2 在所有 9 个任务上都优于 T5 和 GPT 类基线。平均而言,UL2 比 T5 基线高出 +43.6%,比一个语言模型高出 +76.1%。在其他竞争基线中,UL2 是唯一在所有任务上都优于 T5 和 GPT 类模型的方法。研究者进一步将 UL2 扩展到大约 20B(准确地说是 19.5 B)参数的中等规模,并在包含 50 多个 NLP 任务的多样化的组合中进行实验,这些任务包括语言生成(具有自动和人工评估)、语言理解、文本分类、问答、常识推理、长文本推理、结构化知识基础和信息检索。实验结果表明,UL2 在绝大多数任务和环境下都达到了 SOTA。最后,研究者使用 UL2 进行了零 / 少样本实验,并表明 UL2 在零样本 SuperGLUE 上的性能优于 GPT-3 175B。与 GLaM (Du et al., 2021)、PaLM (Chowdhery et al., 2022) 和 ST-MoE (Zoph et al., 2022) 等较新的 SOTA 模型相比,UL2 尽管仅在 C4 语料库上进行了训练,但在计算匹配环境下的性能仍然极具竞争力。研究者深入分析了零样本与微调性能之间的权衡,表明 UL2 在两种学习范式上都是帕累托有效的。UL2 的性能是一个 LM adapted T5 XXL 模型的三倍,在相同的计算成本下可与 PaLM 和 LaMDA 媲美。这篇论文的(并列)第一作者是谷歌 AI 高级研究科学家 Yi Tay 和谷歌大脑研究科学家 Mostafa Dehghani。Yi Tay 2019 年在新加坡南洋理工大学拿到计算机科学博士学位。他是一位高产的论文作者,曾在 2018 年一年之内以第一作者身份发表了 14 篇领域内顶会论文。此外,他的论文也拿到过多个奖项,如 ICLR 2021 年杰出论文奖、WSDM 2021 年最佳论文奖(亚军)和 WSDM 2020 年最佳论文奖(亚军)。此外,他还曾担任 EMNLP 和 NAACL 等顶级 NLP 会议的区域主席。
许多预训练任务可以被简单地表述为「输入到目标(input-to-target)」型任务,其中输入指的是模型所依赖的任何形式的记忆或上下文,而目标是模型的预期输出。语言模型使用所有以前的时间步作为输入来预测下一个 token,即目标。在 span corruption 中,模型利用来自过去和未来的所有未损坏的 token 作为预测 corrupted span(目标)的输入。Prefix-LM 是使用过去的 token 作为输入的语言模型,但它双向使用输入:这比普通语言模型中输入的单向编码提供了更强的建模能力。从这个角度来看,我们可以将一个预训练目标简化为另一个目标。例如,在 span corruption 目标中,当 corrupted span(目标)等于整个序列时,该问题实际上就变成了一个语言建模问题。考虑到这一点,使用 span corruption,通过将 span 长度设置得很大,我们可以在局部区域中有效地模拟语言建模目标。研究者们定义了一个符号,它涵盖了本文中使用的所有不同的去噪任务。去噪任务的输入和目标由 SPANCORRUPT 函数生成,该函数由三个值 (µ, r, n) 来参数化,其中 µ 是平均 span 长度,r 是 corruption rate,n 是 corrupted span 的数量。注意,n 可能是输入长度 L 和 span 长度 µ 的函数,如 L/µ,但在某些情况下,研究者使用 n 的固定值。给定输入文本,SPANCORRUPT 将 corruption 引入从具有 u 均值的(正态或均匀)分布中提取的长度的 span。在 corruption 之后,输入文本被馈送到去噪任务,corrupted span 被用作要恢复的目标。举个例子,用这个公式来构建一个类似于因果语言建模的目标,只需设置 (µ = L, r = 1.0, n = 1) ,即单个 span 的长度等于序列的长度。要表达一个类似于 Prefix LM 的目标,可以设置 (µ = L − P, r = 1.0 − P/L, n = 1) ,其中 P 是 prefix 的长度,附加的约束是单个 corrupted span 总是到达序列的末尾。研究者注意到,这种 inputs-to-target 的公式既可以应用于编码器 - 解码器模型,也可以应用于单栈 Transformer 模型(如解码器模型)。他们选择了预测下一个目标 token 的模型,而不是就地预测的模型(例如 BERT 中的预测当前掩蔽 token),因为下一个目标公式更通用,并且可以包含更多的任务,而不是使用特殊的「CLS」token 和特定于任务的 projection head。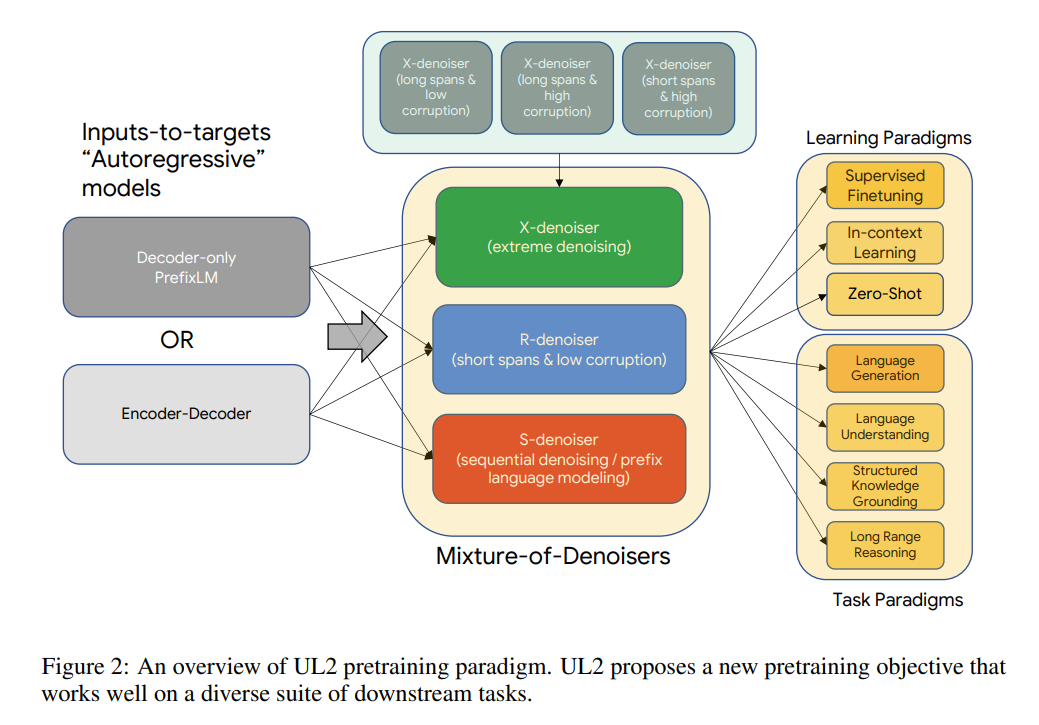
研究者认为,在预训练期间,一个强大的通用模型必须去面对、解决不同的问题集。假设预训练是使用自监督完成的,研究者认为这种多样性应该被注入到模型的目标中,否则模型可能会缺乏某种能力,比如连贯长文本生成能力。基于此,以及当前的目标函数类型,他们定义了预训练期间使用的三种主要范式:
这组 denoiser 与先前使用的目标函数有很强的联系:R-Denoising 是 T5 span corruption 目标,S-Denoising 与类 GPT 的因果语言模型相关,而 X-Denoising 可以将模型暴露给来自 T5 和因果 LM 的目标的组合。值得注意的是,X-denoiser 也被连接起来以提高样本效率,因为在每个样本中可以学习到更多的 token 来预测,这与 LM 的理念类似。研究者提出以统一的方式混合所有这些任务,并有一个混合的自监督的目标。最终目标是混合 7 个去噪器,配置如下:
对于 X - 和 R-Denoiser,span 长度从均值为 µ 的正态分布中采样。对于 S-denoiser,他们使用均匀分布,将 corrupted span 的数量固定为 1,并且具有额外的约束,即 corrupted span 应该在原始输入文本的末尾结束,在 corrupted 部分之后不应该出现未被裁剪的 token。这大致相当于 seq2seq 去噪或 Prefix LM 预训练目标。由于 LM 是 Prefix-LM 的一种特殊情况,研究者认为没有必要在混合中包含一个偶然的 LM 任务。所有任务在混合中具有大致相同的参与度。研究者还探索了一种替代方案,他们将混合配置中 S-denoiser 的分量增加到 50%,其余份额由其他 denoiser 共享。最后,「混合」这一动作使得 Mixture-of-Denoisers 具有非常强的通用性。单独来看,一些 denoiser 类型表现不佳。例如,最初的 T5 论文探索了一个具有 50% corruption rate 的选项(X-denoising),但发现效果不佳。UL2 的 Mixture-of-Denoisers 的实现非常简单,使用 seqio3 之类的库很容易实现。研究者引入了通过模式切换进行范式转换的概念。在预训练期间,他们为模型提供了一个额外的范式 token,即 {[R],[S],[X]},这有助于模型切换到更适合给定任务的模式。对于微调和下游 few-shot 学习,为了触发模型学习更好的解决方案,研究者还添加了一个关于下游任务的设置和要求的范式 token。模式切换实际上是将下游行为绑定到上游训练中使用的模式之一上。表 2 显示了在所有基准测试任务和数据集上的原始结果。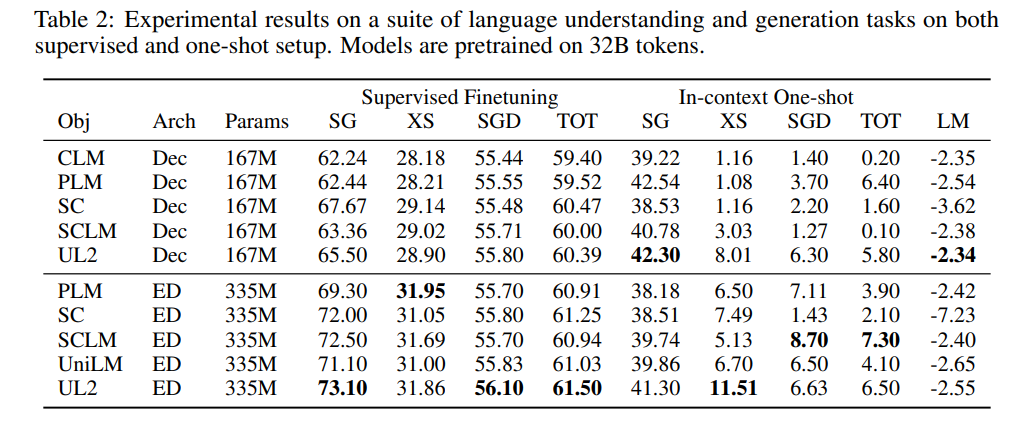
为了方便不同设置之间的比较,研究者还给出了 UL2 与已建立的基线(如 T5 和 GPT 模型)的相对比较,如表 3 和表 4 所示。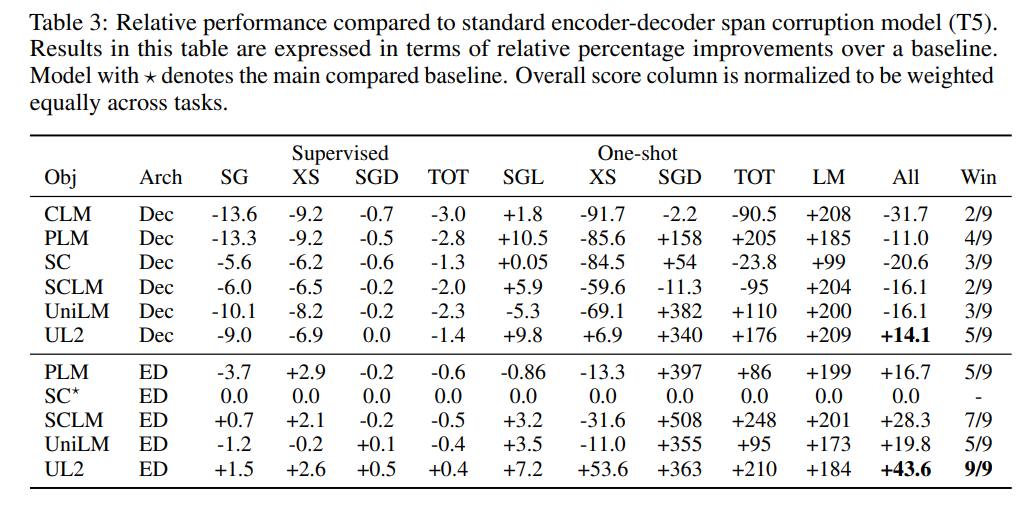
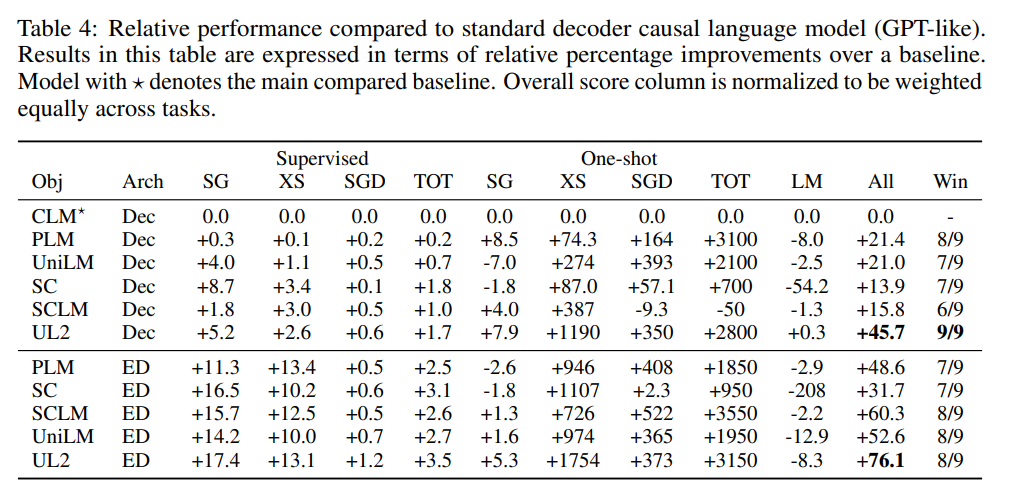
图 8 显示了 UL20B 在不同任务中与之前 SOTA 的对比结果。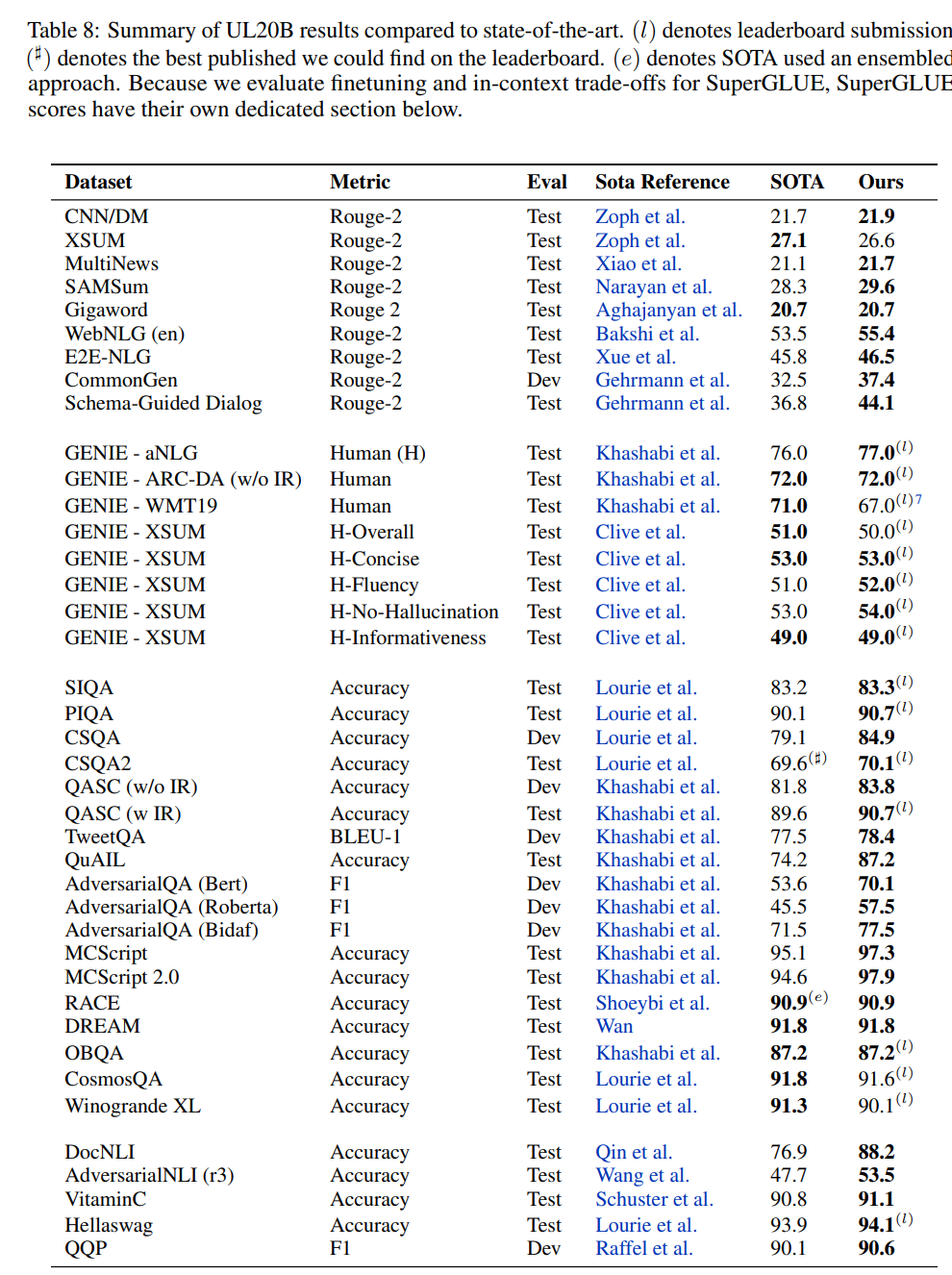
推荐阅读
深入理解生成模型VAE
DropBlock的原理和实现
SOTA模型Swin Transformer是如何炼成的!
有码有颜!你要的生成模型VQ-VAE来了!
集成YYDS!让你的模型更快更准!
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
SimMIM:一种更简单的MIM方法
SSD的torchvision版本实现详解
机器学习算法工程师
一个用心的公众号

