
比9种SOTA GNN更强!谷歌大脑提出全新图神经网络GKATs

来源:Google、新智元 本文约2550字,建议阅读5分钟 本文为你介绍谷歌大脑与牛津大学、哥伦比亚大学的研究人员提出的一种全新GNN:GKATs。
[ 导读 ]GNN虽牛,但也避免不了计算复杂性等问题。为此,谷歌大脑与牛津大学、哥伦比亚大学的研究人员提出了一种全新的GNN:GKATs。不仅解决了计算复杂度问题,还被证明优于9种SOTA GNN。
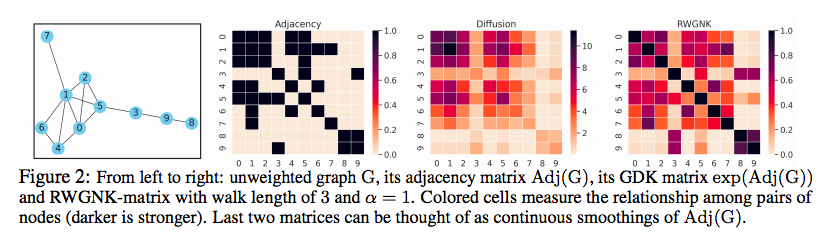
Erdős-Rényi随机图:

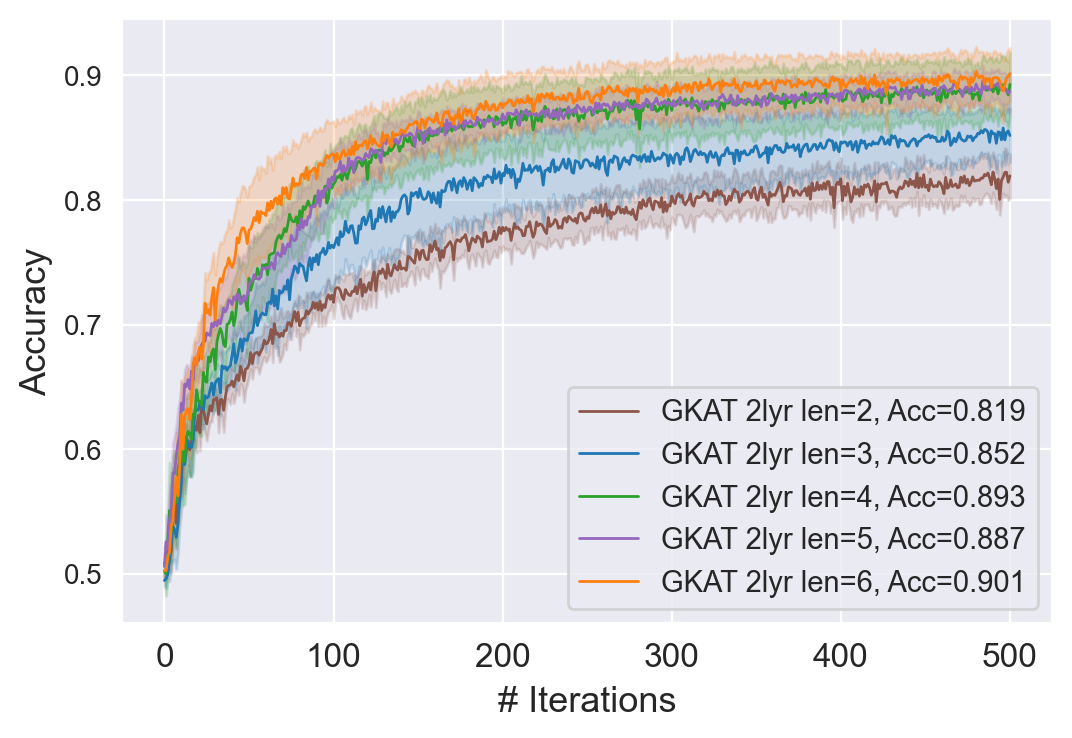
检测长诱导循环和深度与密度注意力测试:
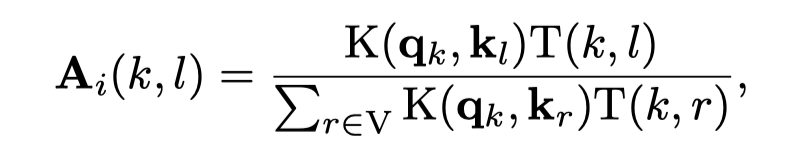
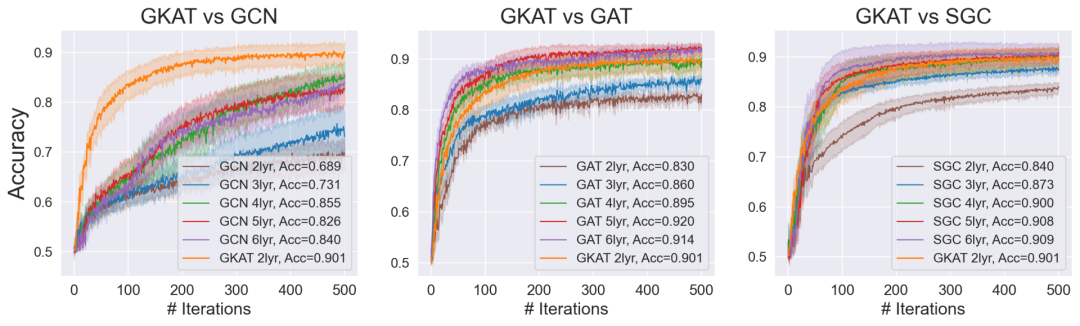
生物信息学任务和社交网络数据测试:


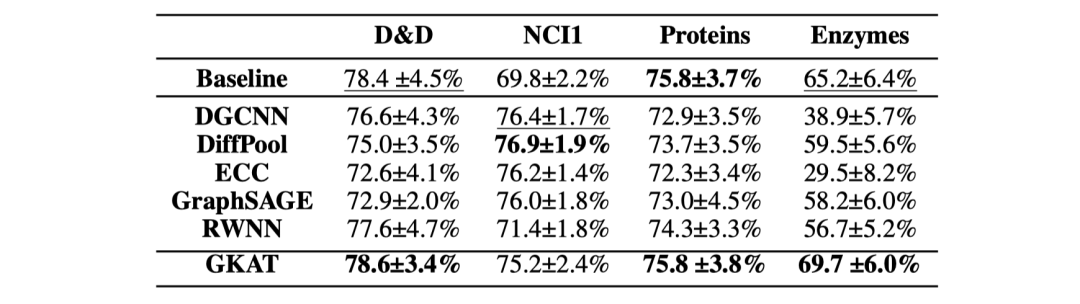
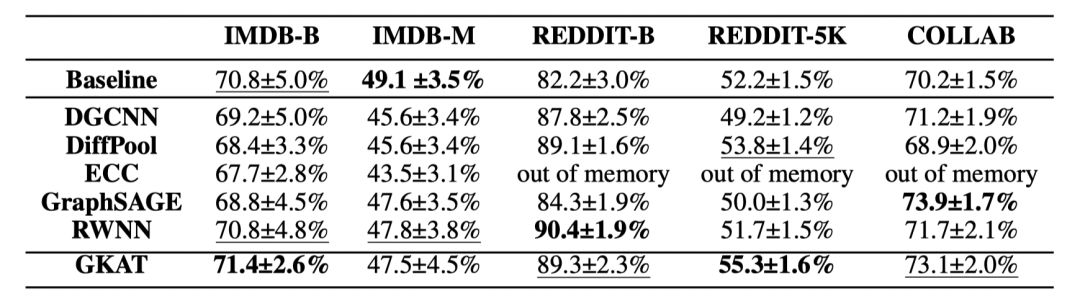
GKAT的空间和时间复杂度增益:
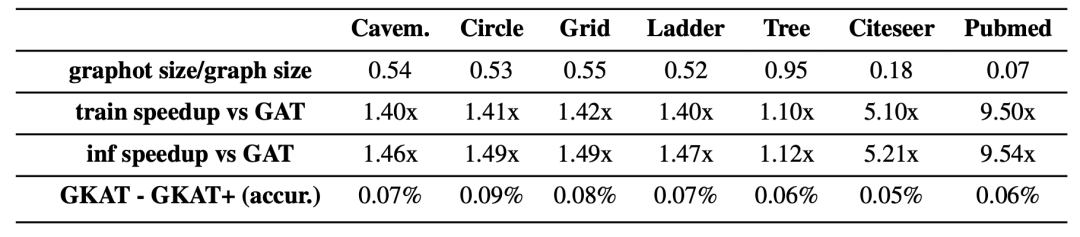

利用了图核方法和可扩展注意力 在处理图数据方面更具表现力 具有低时间复杂性和内存占用 在广泛的任务上优于其他SOTA模型
编辑:黄继彦
评论