
NLP预训练范式大一统,不再纠结下游任务类型,谷歌这个新框架刷新50个SOTA
编辑:张倩、小舟
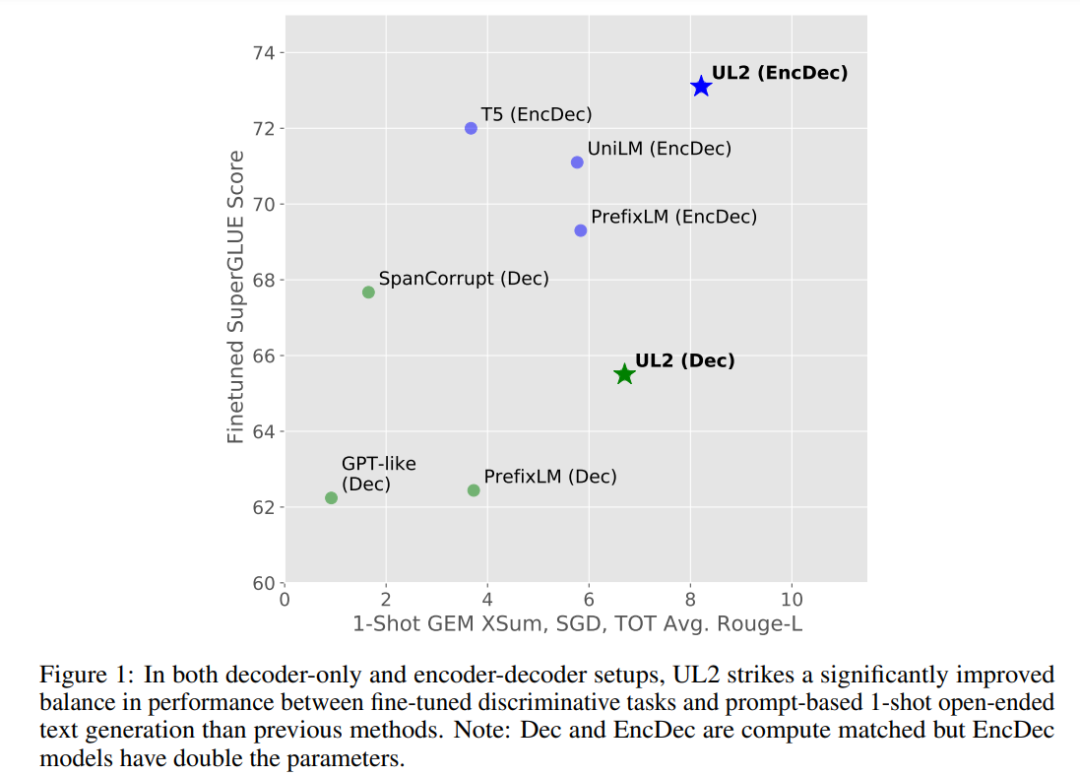
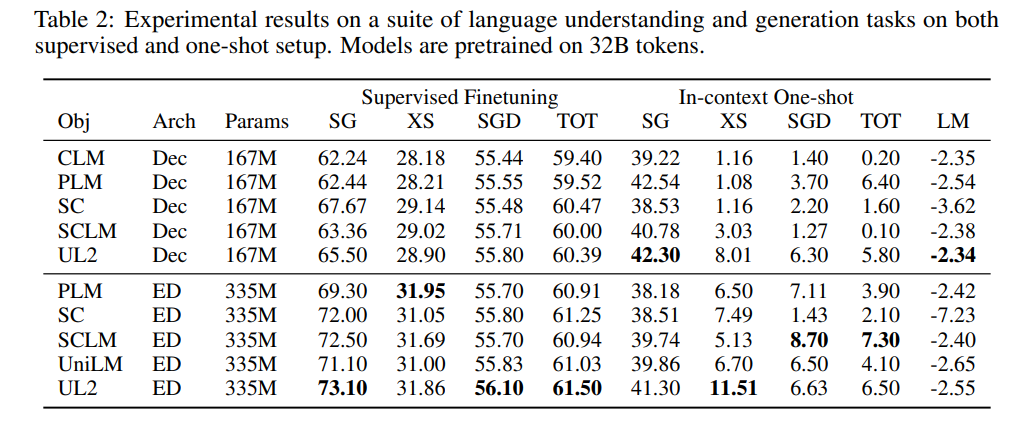
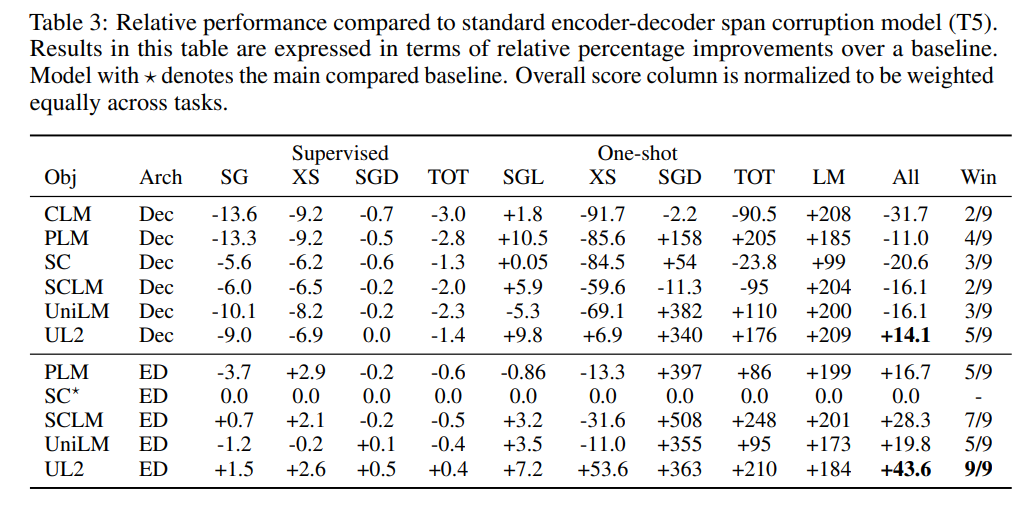
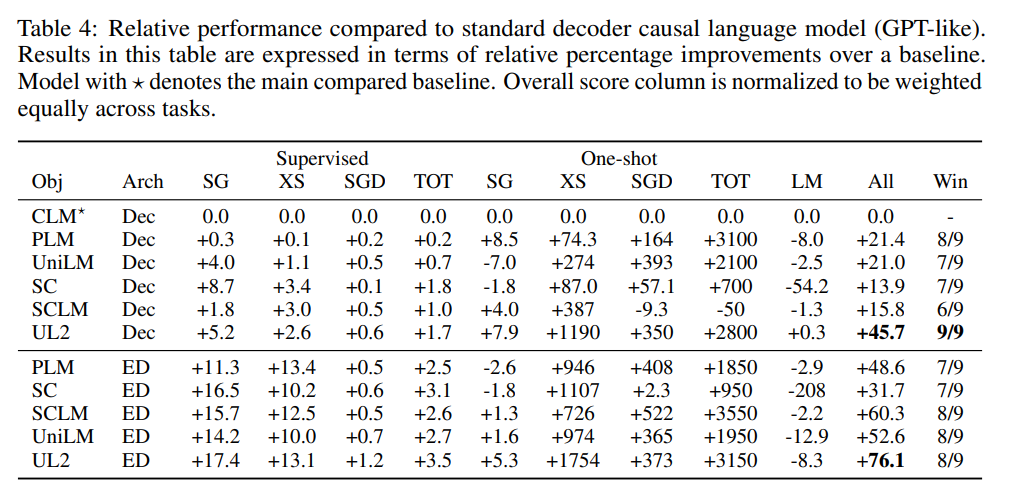
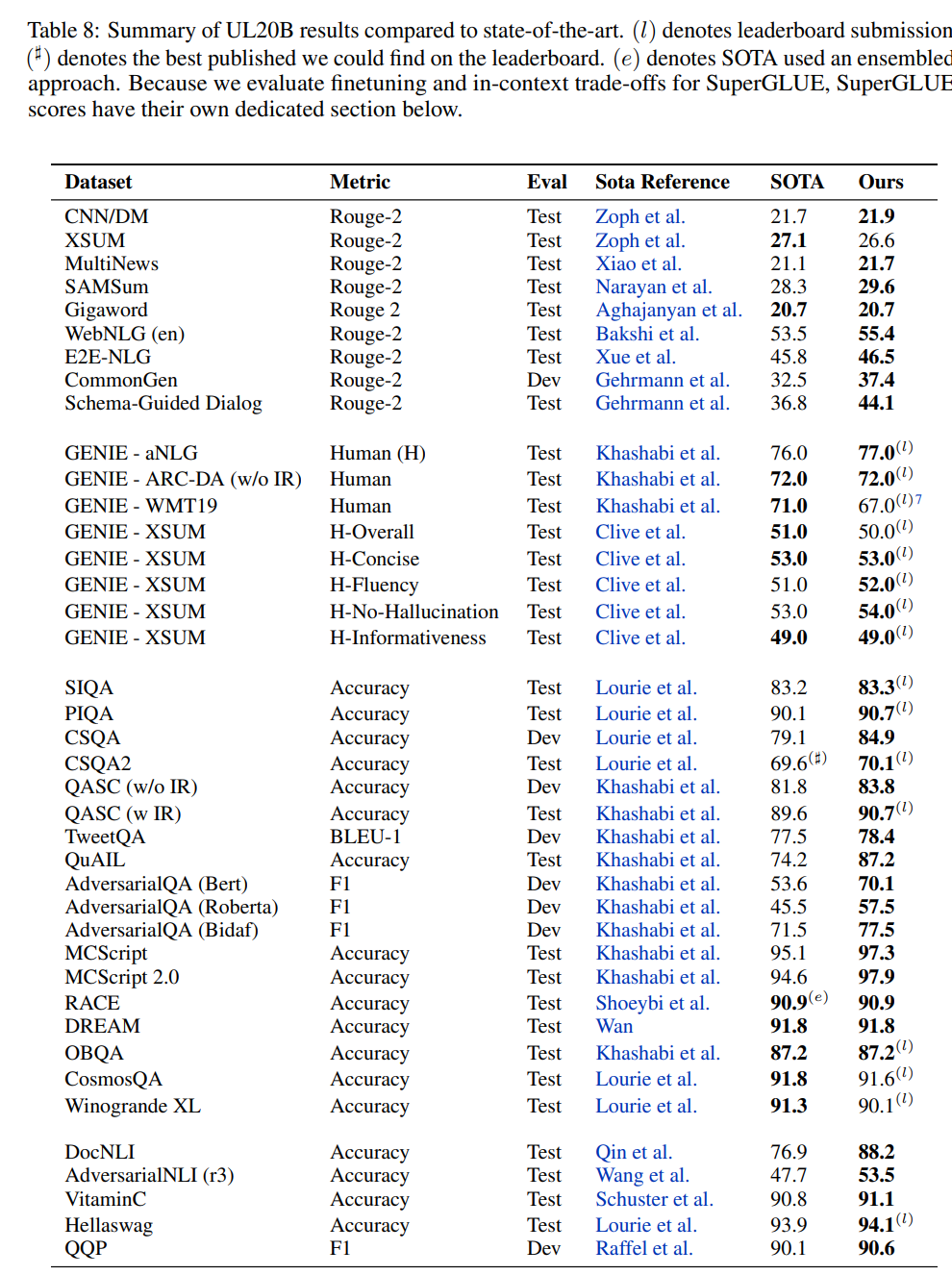
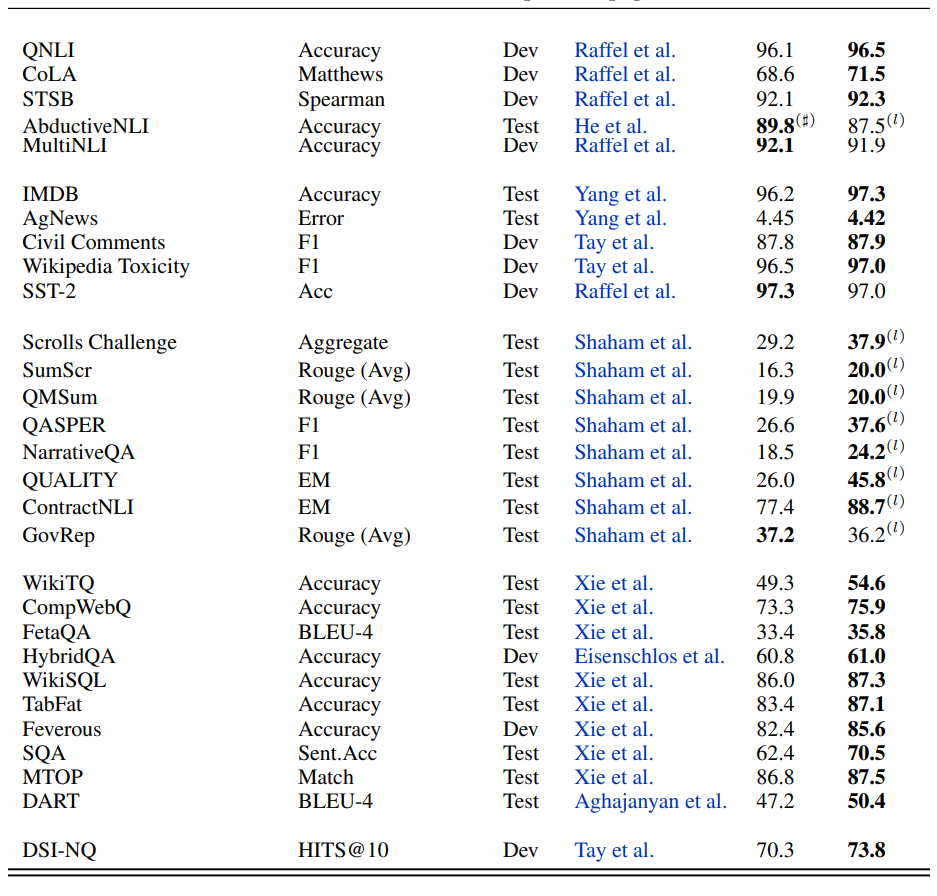
在这篇论文中,来自谷歌的研究者提出了一种统一各种预训练范式的预训练策略,这种策略不受模型架构以及下游任务类型影响,在 50 项 NLP 任务中实现了 SOTA 结果。

论文链接:https://arxiv.org/pdf/2205.05131.pdf
代码地址:https://github.com/google-research/google-research/tree/master/ul2
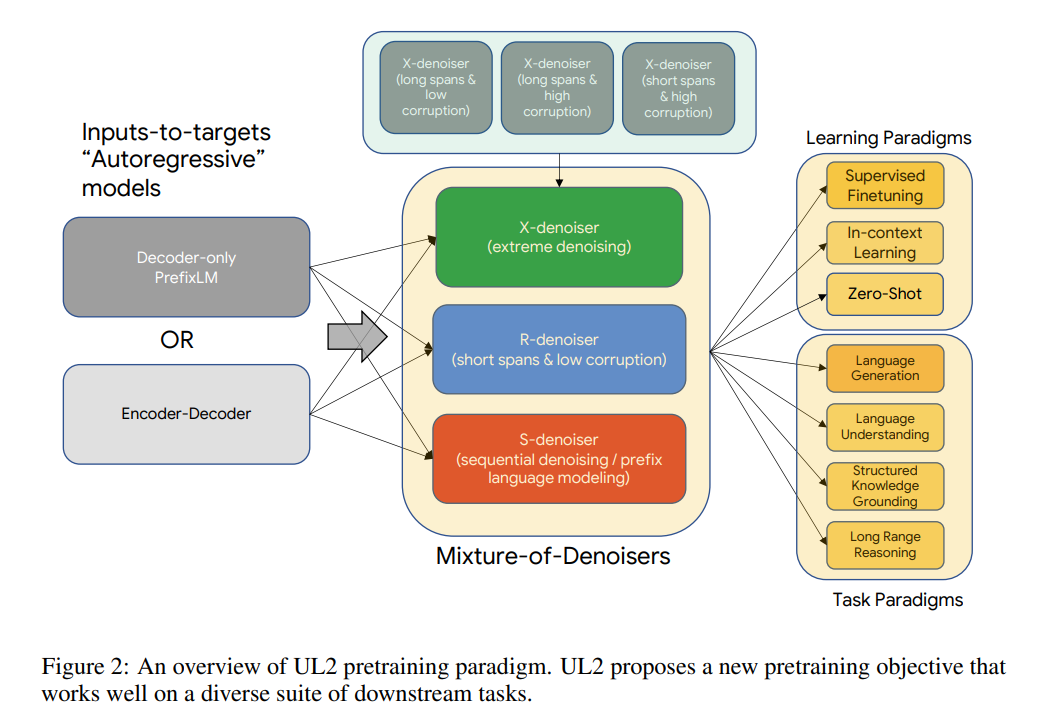
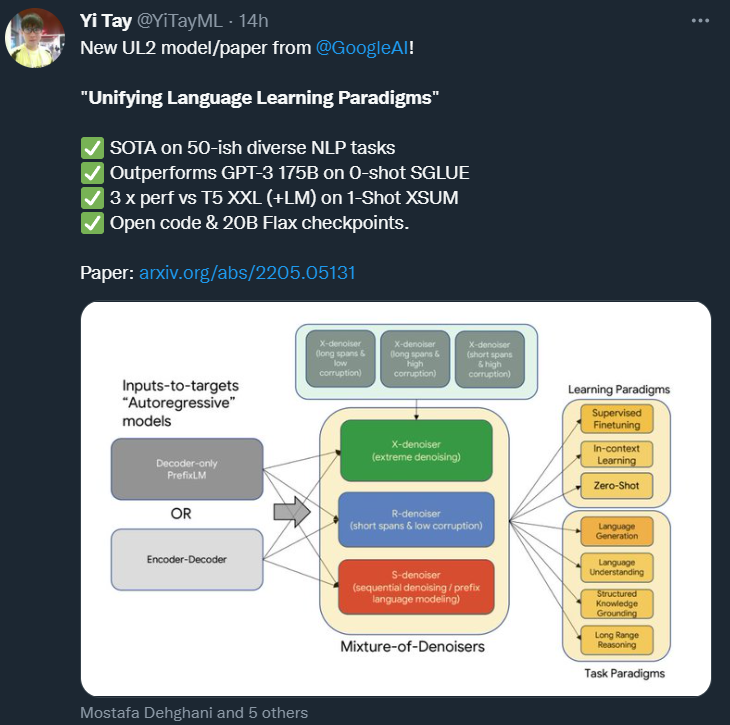
R-Denoiser,regular denoising 是 Raffel et al. (2019) 引入的标准 span corruption,它使用 2 到 5 个 token 作为 span length,遮蔽了大约 15% 的输入 token。这些 span 非常短,可能有助于知识获取(而非学习生成流畅的文本)。
S-Denoiser,去噪的一种具体情况,在构建 inputs-to-targets 任务时遵守严格的顺序,即 prefix 语言建模。为此,研究者只需将输入序列划分为两个 token 子序列,分别作为上下文和目标,这样目标就不依赖于未来的信息。这与标准 span corruption 不同,在标准 span corruption 中,可能存在位置比上下文 token 更早的目标 token。注意,与 Prefix-LM 设置类似,上下文(prefix)保留了一个双向感受野。研究者注意到,具有非常短的记忆或没有记忆的 S-Denoising 与标准的因果语言建模的精神是相似的。
X-Denoiser,去噪的一种 extreme 版本,模型必须恢复输入的绝大部分。这模拟了模型需要借助有限信息记忆生成长目标的情况。为此,研究者选择了包含积极去噪的例子,其中大约 50% 的输入序列被遮蔽。这是通过增加 span 长度和 / 或 corruption 率来实现的。如果预训练任务 span 长(如≥ 12 个 token)或 corruption 率高(如≥ 30%),就认为该任务是 extreme 的。X-denoising 的动机是作为常规 span corruption 和类似目标的语言模型之间的插值而存在。


© THE END
转载请联系原公众号获得授权

点个在看 paper不断!