
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
谷歌最新的研究论文提出了一种Meta Pseudo Labels的半监督学习方法(https://arxiv.org/pdf/2003.10580.pdf),刷新了ImageNet上的最高结果,终于终于,ImageNet的Top-1可以上90%了!
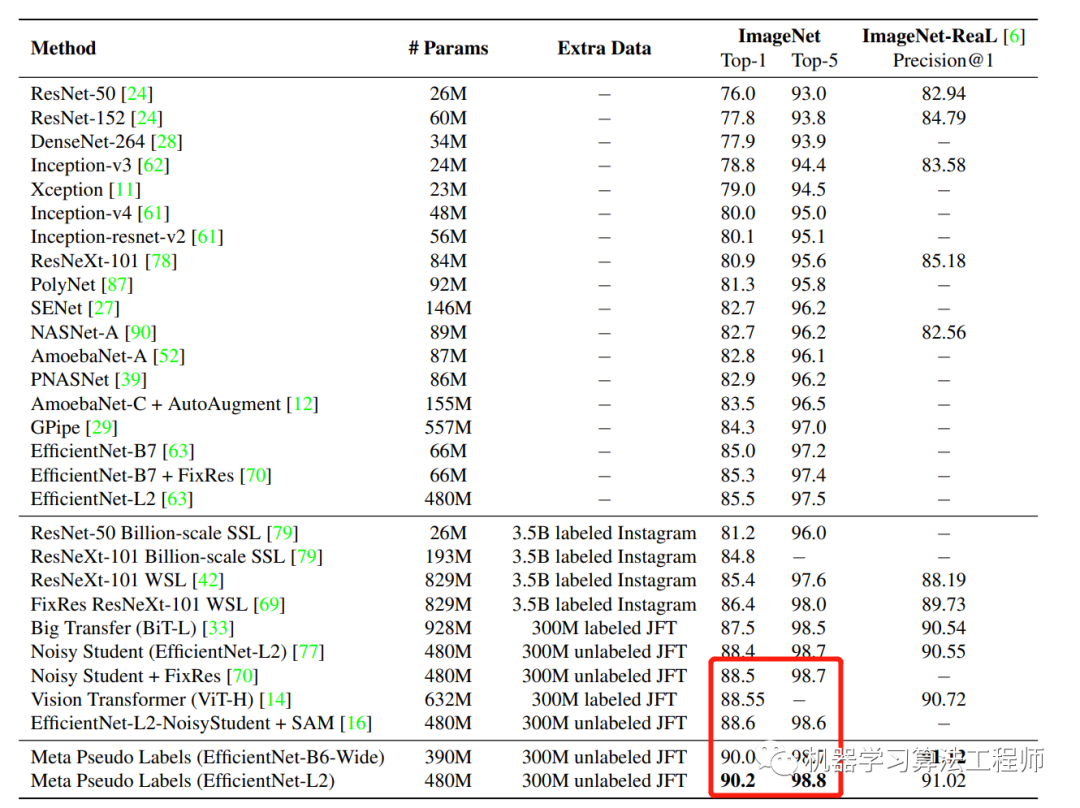
其实谷歌刷新的还是自己的记录,因为目前ImageNet上的SOTA还是由谷歌提出的EfficientNet-L2-NoisyStudent + SAM(88.6%)和ViT(88.55%)。
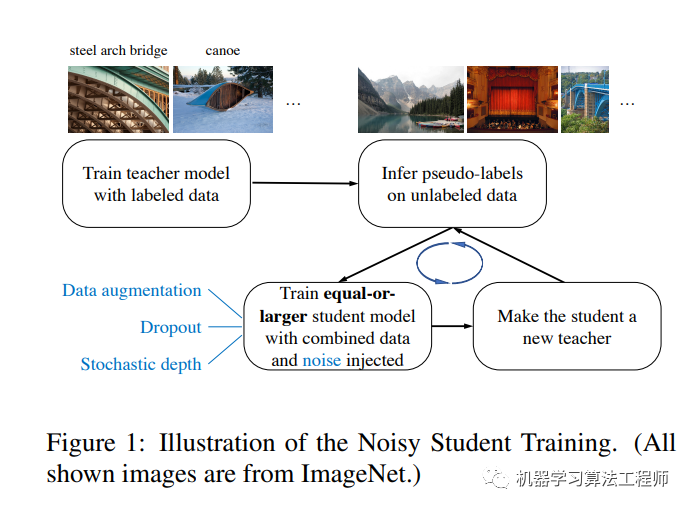
首先谷歌这篇paper所提出的方法Meta Pseudo Labels是一种半监督学习方法(a semi-supervised learning ),或者说是self-training方法。和谷歌之前的SOTA方法一样,这里当然用到了那个未公开的300M JFT数据集。不过这里把它们当成unlabeled的数据(和NoisyStudent一样,但ViT是用的labeled数据pretrain)。Meta Pseudo Labels可以看成是最简单的Pseudo Labels方法的改进,如下图所示。其实之前的SOTA方法Nosiy Student也是一种Pseudo Labels方法,如上图所示。
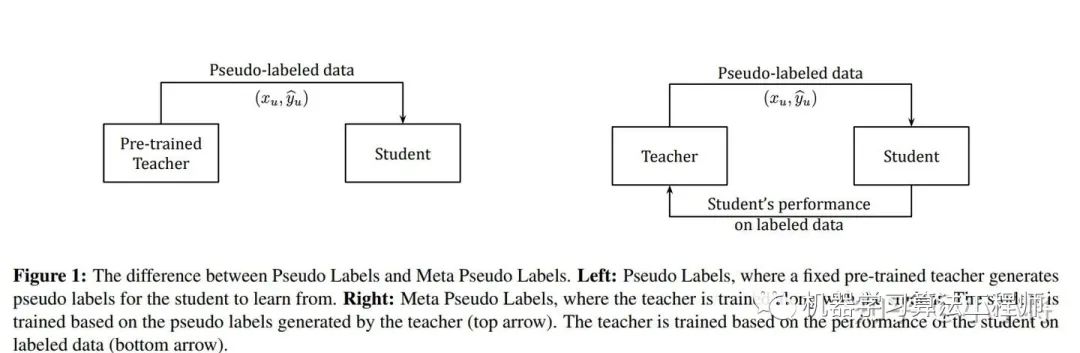
Meta Pseudo Labels要解决的是Pseudo Labels容易出现的confirmation bias:
if the pseudo labels are inaccurate, the student will learn from inaccurate data. As a result, the student may not get significantly better than the teacher. Overfitting to incorrect pseudo-labels predicted by the network is known as confirmation bias.
老师总会犯错,这就会带偏学生。谷歌提出的解决方案,是用学生在labeled数据集的表现来更新老师,就是上图中老师也是不断被训练的,有点强化学习的意味,就是student的preformance应该是teacher进化的一个reward。Meta Pseudo Labels其实也算是对模型训练过程的优化,为什么叫Meta,paper里面也给出解释:
We use Meta in our method name because our technique of deriving the teacher’s update rule from the student’s feedback is based on a bi-level optimization problem which appears frequently in the literature of meta-learning.
虽然思路很简单,但是paper里有非常复杂的推导,这里直接贴出伪代码(训练teacher时其实gradient包含三个部分:来自student的feedback,labeled数据loss,以及UDA loss):

关于Meta Pseudo Labels的benefits,paper里面给出了一个toy case,这个效果让人震惊。简单来说,就是用TwoMoon dataset,这个数据集中共有两类,或者说是两个cluster,总数据是2000个,每个cluster共有1000个,现在每个cluster只有3个labeled数据,其它都是unlabeled的数据。作者在这样的一个任务上对比了三种方法:Supervised Learning, Pseudo Labels, and Meta Pseudo Labels,最终结果如下所示:

红色圈和绿色圈分别是两类的samples,星号表示labeled的6个数据,红色和绿色区域表示模型的分类区域,虽然3类方法都可以对6个训练样本正确分类,但具体到unlabeled的数据效果差别很大。SL方法基本过拟合了,分类区域完全不对;而Pseudo Labels分对了一半,但是Meta Pseudo Labels却找到了一个比较完美的classifier。虽然这个分类任务看起来不难(两个cluster有明显的边界),但是只有6个训练样本,这里finding a good classifier is hard。
当然Google也在论文里狠狠地秀了一把肌肉:
We thus design a hybrid model-data parallelism framework to run Meta Pseudo Labels. Specifically, our training process runs on a cluster of 2,048 TPUv3 cores.
论文最后的D2中说到:
Meta Pseudo Labels Is An Effective Regularization Strategy
这句话应该是对谷歌这个方法的一个较好的总结。
如果想了解更多论文的细节,可以直接看源码:
https://github.com/google-research/google-research/tree/master/meta_pseudo_labels
推荐阅读
CondInst:性能和速度均超越Mask RCNN的实例分割模型
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
