
文本生成图像的新SOTA:Google的XMC-GAN
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
来源:新智元
【导读】从图像到生成文本、从文本生成图像,多模态模型的探索一直未停止。最近Google又出从文本到图像的新模型,75%的人类都说超过了传统的SOTA模型,直呼脑子里有画面了!
文本到图像的自动合成(automatic text-to-image synthesis)是一个具有挑战性的研究课题,也逐渐引起了学界的重视,模型的训练输入只有文本,输出为一个图像。
这项研究能够让研究人员了解机器学习(ML)模型如何获得视觉属性,并将它们与文本联系起来。
与素描图、物体遮罩或矢量图等其他类型的图像创建的输入相比,描述性的句子是一种更直观和灵活的视觉概念表达方式。
“别说了,有画面了”就是这个意思。

因此,一个强大的自动文本到图像生成系统也可以成为快速创建内容的有用工具,并且可以应用于许多其他创造性应用,类似于将机器学习融入艺术创作。
一个典型的例子是Magenta,由谷歌大脑创造的,旨在推进 AI 在艺术领域的发展,可以进行包括 AI 音乐、绘画、笑话生成在内的多个项目。计算机能否具有创造力,这个问题也许还没有答案,但 AI 能创作出富有趣味的音乐和画作,则已经被Magenta带进了现实。
最先进的图像合成结果通常使用生成对抗性网络(GANs)来实现,该网络训练两个模型: 一个是试图创造真实图像的生成器,另一个是试图判断图像是真实还是虚构的鉴别器。
许多文本到图像的生成模型都是有限制条件的,例如类别标签等,它使用文本输入来生成语义相关的图像。
这个任务是非常具有挑战性的,特别是在提供长而模糊的描述时。
此外,GAN 的训练还很容易出现模式崩溃,也是训练过程中常见的失败案例,在这种情况下,生成器学习只产生有限的一组输出,因此鉴别器无法学习识别伪造图像的稳健策略。为了减少模式崩溃,一些方法使用多阶段细化网络迭代细化图像。
然而,这种系统需要多阶段的培训,并且效率远低于简单的单阶段端到端模型。其他的工作则依赖于分层的方法,即在最终合成一个真实的图像之前,首先对模型对象进行布局。这需要使用带标签的分段数据,这可能很难获得。
基于这个问题,Google在CVPR 2021上发表了一篇论文《跨模态对比学习: 文本到图像的生成》,提出了一个跨模态对比生成语法网络(XMC-GAN) ,该网络通过学习使图像和文本之间的互信息最大化,利用图像-文本和图像-图像之间的对比丢失来实现文本到图像的生成。

这种方法有助于判比器学习更健壮和鉴别特征,因此即使是一阶段的训练, XMC-GAN 也更不容易模式崩溃。
重要的是,与以前的多级或分级方法相比,XMC-GAN 通过简单的一阶段生成就实现了sota性能。它是端到端可训练的,只需要图像-文本对(相对于标记分割或边界框数据)即可训练。
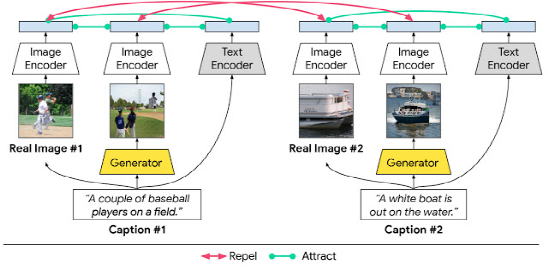
文本到图像合成的对比损失文本到图像合成系统的目标是生成清晰的、具有高语义逼真度的、符合条件的文本描述的真实场景。为了实现这一目标,Google提出最大化相应对之间的互信息: (1)图像(真实的或生成的)与描述场景的句子; (2)生成的图像和具有相同描述的真实图像; (3)图像的区域(真实的或生成的)和与之相关的单词或短语。
在 XMC-GAN通过对比损失来增强效果。与其他 GANs 类似,XMC-GAN 包含了一个合成图像的生成器,以及一个判别器,它被训练成为真实图像和生成图像之间的判别器。
三组数据共同构成系统的对比损失,即真实图像、描述图像的文本以及由文本描述生成的图像。生成器和鉴别器的单个损失函数是从整个图像计算的损失与全文描述的损失的组合,再加上从带有相关单词或短语的细分图像计算的损失。
对于每一批训练数据,计算每一个文本描述和真实图像之间的余弦距离得分,同样,每一个文本描述和生成的图像之间的得分,目标是使匹配对(文本到图像和真实图像到生成的图像)具有较高的相似性得分,而非匹配对的相似性得分较低。执行这样的对比损失可以使鉴别器学习更健壮和鉴别特征。
XMC-GAN 成功应用于三个具有挑战性的数据集,一个是 MS-COCO 图像的描述集,另外两个是带有局部叙事注释的数据集,其中一个包括 MS-COCO 图像(也称为 LN-COCO) ,另一个描述开放图像数据(LN-OpenImages)。
结果发现,XMC-GAN 实现了一个新的国家的艺术在每一个。由 XMC-GAN 生成的图像所描绘的场景质量高于使用其他技术生成的图像。在 MS-COCO 上,XMC-GAN 将最先进的 Fréchet 起始距离(FID)评分从24.7提高到9.3,并且明显受到人类评估者的青睐。

同样,其他三个sota模型相比(CP-GAN,SD-GAN,和 OP-GAN),77.3%的人类评分员更喜欢 XMC-GAN 生成的图像质量,和74.1% 的认为模型图像文本对齐更好。

XMC-GAN 也很好地概括了具有挑战性的本地化叙事数据集,其中包含更长和更详细的描述。我们之前的工作 TReCS 解决了文本到图像生成的本地化叙事使用鼠标跟踪输入,以改善图像生成质量。尽管没有收到鼠标跟踪注释,但 XMC-GAN 能够在 LN-COCO 上显著优于 TReCS 的图像生成,将最先进的 FID 从48.7提高到14.1。将鼠标轨迹和其他额外输入纳入端到端模型,如 XMC-GAN,将是今后工作中值得研究的。
此外,我们还在 LN-OpenImages 上进行培训和评估,这比 MS-COCO 更具挑战性,因为数据集更大,图像覆盖的主题范围更广,也更复杂(平均8.4个对象)。据我们所知,XMC-GAN 是第一个在开放图像上训练和评估的文本到图像合成模型。XMC-GAN 能够产生高质量的结果,并在这个非常具有挑战性的任务上设置了一个强大的基准 FID 分数26.9。

在这项工作中,Google提出了一个跨模态对比学习框架,用于文本到图像合成的 GAN 模型的训练,并研究了几种加强图像和文本对应的跨模态对比损失。
对于人类评估和定量指标,XMC-GAN 建立了一个显着改进以前的模型对多个数据集。它生成高质量的图像,很好地匹配他们的输入描述,包括长的、详细的叙述,这样做的同时,还能够保持一个简单的端到端模型。
研究人员相信这代表了从自然语言描述生成图像的创造性应用的一个重大进步。随着这项研究的继续,根据人类社会的人工智能原则,还应该不断评估方法、潜在的应用和风险缓解方案。
参考资料:
https://ai.googleblog.com/2021/05/cross-modal-contrastive-learning-for.html
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》