
手把手教你使用SHAP(机器学习模型解释工具)
SHAP简介
SHAP(SHapley Additive exPlanation)是解决模型可解释性的一种方法。SHAP基于Shapley值,该值是经济学家Lloyd Shapley提出的博弈论概念。“博弈”是指有多个个体,每个个体都想将自己的结果最大化的情况。该方法为通过计算在合作中个体的贡献来确定该个体的重要程度。
SHAP将Shapley值解释表示为一种加性特征归因方法(additive feature attribution method),将模型的预测值解释为二元变量的线性函数:
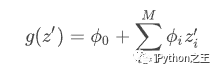
其中![]() ,M是简化输入的特征数,
,M是简化输入的特征数,![]()
假设第i个样本为![]() ,第i个样本的第j个特征为
,第i个样本的第j个特征为![]() ,模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为
,模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为![]() ,那么SHAP value服从以下等式:
,那么SHAP value服从以下等式:
![]()
其中![]() 为
为![]() SHAP值。f(xi,1)就是第i个样本中第1个特征对最终预测值yi的贡献值。每个特征的SHAP值表示以该特征为条件时预期模型预测的变化。对于每个功能,SHAP值说明了贡献,以说明实例的平均模型预测与实际预测之间的差异。当f(xi,1)>0,说明该特征提升了预测值,反之,说明该特征使得贡献降低。
SHAP值。f(xi,1)就是第i个样本中第1个特征对最终预测值yi的贡献值。每个特征的SHAP值表示以该特征为条件时预期模型预测的变化。对于每个功能,SHAP值说明了贡献,以说明实例的平均模型预测与实际预测之间的差异。当f(xi,1)>0,说明该特征提升了预测值,反之,说明该特征使得贡献降低。
加性特征归因方法是满足以下三个条件的唯一解决方案:
局部精度 Local Accuracy:对特定输入x近似原始模型 f 时,局部精度要求解释模型至少和 f 对简化的输入x′ 输出匹配: 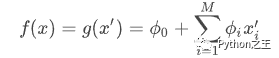 - 缺失性 Missingness:如果简化的输入表示特征是否存在,缺失性要求输入中缺失的特征对结果没有影响:
- 缺失性 Missingness:如果简化的输入表示特征是否存在,缺失性要求输入中缺失的特征对结果没有影响: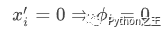 - 一致性 Consistency:一致性要求如果模型发生变化,简化输入的贡献应当增加或不变,与其他输入无关:
- 一致性 Consistency:一致性要求如果模型发生变化,简化输入的贡献应当增加或不变,与其他输入无关: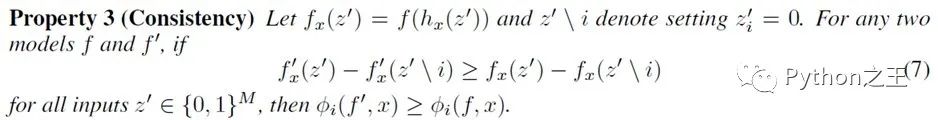
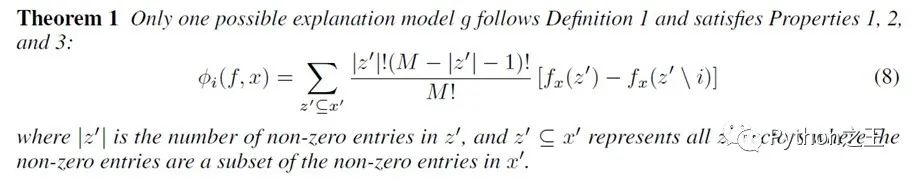
定理1来自于合作博弈论的组合结果,ϕi表示Shapley值。Young (1985)证明了Shapley值是唯一满足局部精度、一致性和一个冗余属性的值。
SHAP****优点:
解决了多重共线性问题- 不仅考虑单个变量的影响,而且考虑变量之间的协同效应
缺点
计算效率低
应用方法
(基于tensorflow和keras)
导入SHAP库
import shap
如果没有这个库,先在terminal安装:
pip install shap
导入模型
以随机森林为例:
导入模型的方法为:
from sklearn.externals import joblib
model = joblib.load('..(你的随机森林模型路径)\RF.model')
确定特征值,也就是你要分析的参数
在本文的例子中,特征参数都在x_test数组中
创建解释器
explainer = shap.TreeExplainer(model) #创建解释器
因为我们的模型是随机森林,所以采用的是针对树的解释器:TreeExplainer
用解释器对特征参数进行解释
shap_values = explainer.shap_values(x_test) #x_test为特征参数数组 shap_value为解释器计算的shap值
绘制单变量影响图
shap.dependence_plot("参数名称", 计算的SHAP数组, 特征数组, interaction_index=None,show=False)
注意:
1)”参数名称“表示要绘制的单变量名称
2)shap_value是第5步计算的SHAP值
3)特征数组为dataframe格式。第一行需要是特征名称,后面是具体的特征数值。如果原始数组是numpy的array数组,需要按照以下代码添加特征名称:
data_with_name = pd.DataFrame(x_test) #将numpy的array数组x_test转为dataframe格式。
data_with_name.columns = ['特征1','特征2','特征3'] #添加特征名称
4)interaction_index 表示是否考虑交互作用,None为只考虑单因素作用,不考虑其他因素。如果不是None,会自动搜索与该参数交互最大的参数,也就是令颜色的离散程度最大的特征进行着色,然后从图中展示出来。
如图所示,如果考虑交互作用,与等效渗透率交互作用最强的是厚度,或者说,厚度这个参数对等效渗透率的SHAP值分布影响最大。当然,这里可以通过设置查看别的参数的交互作用。
图中横坐标表示特征的取值,纵坐标表示特征的SHAP值,也就是特征的取值对于模型的输出会带来的变化量。此外,对于同一个x值,也就是特征取值相同的样本,他们的SHAP值不同,这是因为该特征与其他特征有交互作用。
5)show=False 表示不显示图,如果是true,显示的是默认绘图格式,也就是说坐标的大小啊,含义啊都是默认的。如果不满意自带的绘图格式,可以show=False,然后自定义格式。这里给出一套相关自定义代码:
fig, ax = plt.subplots()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
shap.dependence_plot("等效渗透率", shap_values, data_with_name,show=False)
plt.xticks( fontproperties='Times New Roman', size=20) #设置x坐标字体和大小
plt.yticks(fontproperties='Times New Roman', size=20) #设置y坐标字体和大小
plt.xlabel('Mean(average impact on model output magnitude)', fontsize=20)#设置x轴标签和大小
plt.tight_layout() #让坐标充分显示,如果没有这一行,坐标可能显示不全
plt.savefig("保存.png",dpi=1000) #可以保存图片
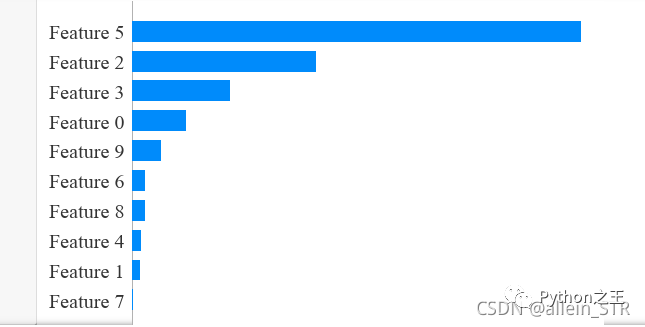
重要性排序绘图
shap.summary_plot(shap_values, x_test, plot_type="bar",show=False)
这行代码可以绘制出参数的重要性排序。
8. 不同特征参数共同作用的效果图
shap.initjs() # 初始化JS
shap.force_plot(explainer.expected_value, shap_values, x_test,show=False)
这个可以体现出不同参数组合对模型的贡献度。也就是说,可以给出模型优化方案,
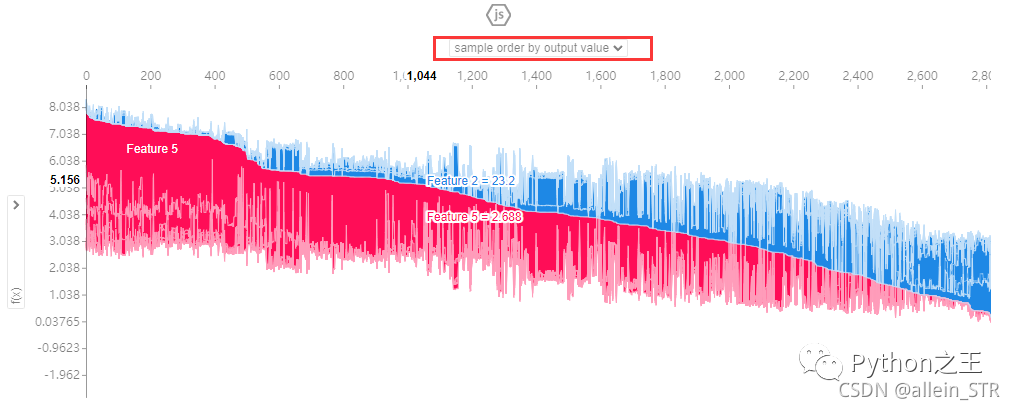
这里有很多种模式可以选择,第一种是根据对模型的贡献度进行排序的,如图所示:
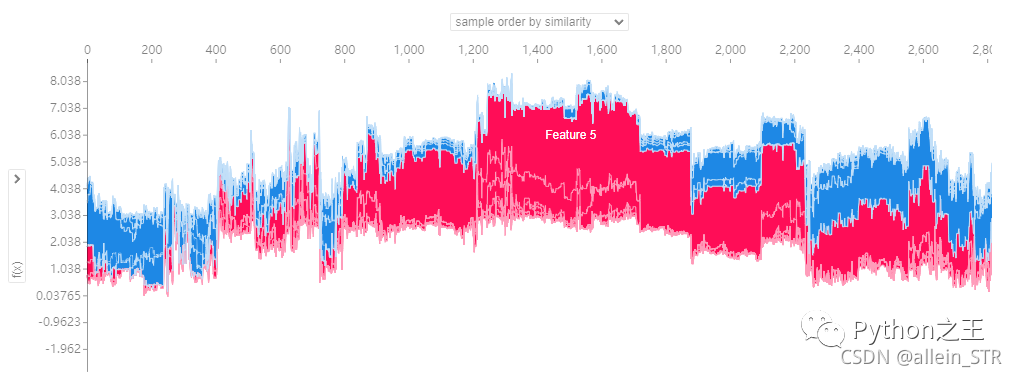
第二种是根据参数的相似性对样本进行排序
第三种是按照原始的样本排序绘图
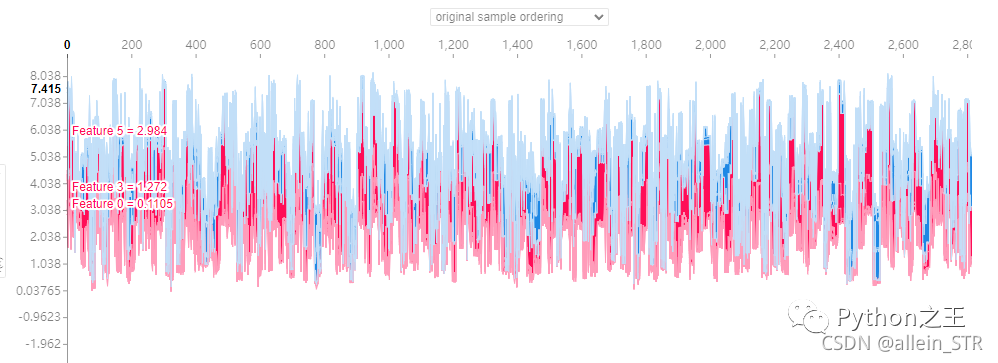
后面几种绘图方式就是根据不同的参数进行绘图:
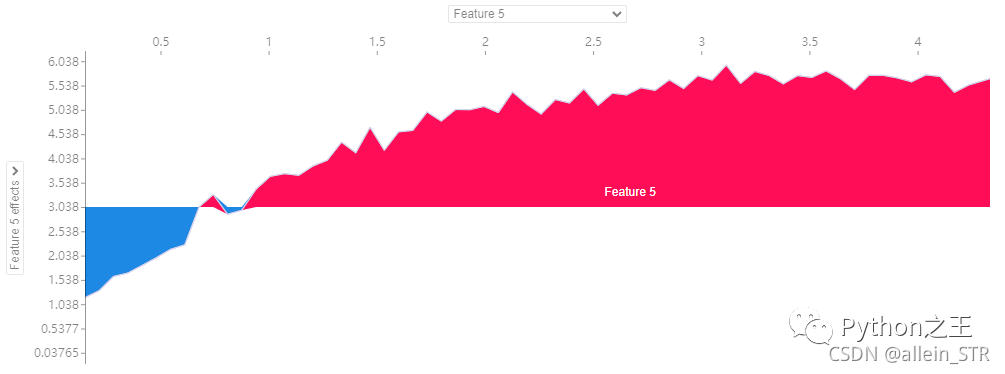
解释:这里鼠标可以随意指到任何位置,然后就可以看到不同的组合情况以及对模型的贡献值(纵坐标显黑的部分)。这里的横坐标表示第几个样本,纵坐标表示不同组合对模型的贡献值。蓝色表示负影响的参数,红色表示正影响的参数。这是一个参数叠加图,红色区域越大,说明正影响越强,反之,蓝色区域越大,说明负影响越强。个人认为这个图的好处就是能够给出明确的对模型贡献大的参数组合。
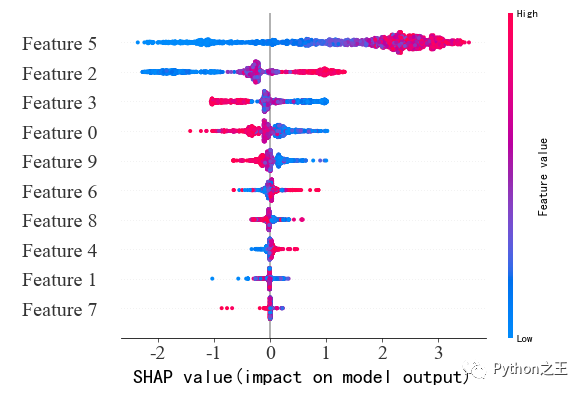
重要性排序图(带正负影响)
传统的feature importance只告诉哪个特征重要,但我们并不清楚该特征是怎样影响预测结果的。SHAP value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
如下图所示,这个图也可以看出参数的重要性,但是比之前的重要性排序图多了具体特征值的影响。以Feature5为例,该参数对模型的影响最大,当feature5的值越小,模型的输出越小,越大,模型的输出越大。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!