
【机器学习】SHAP- 机器学习模型解释可视化工具
SHAP 是机器学习模型解释可视化工具。在此示例中,使用 SHAP 计算使用 Python 和 scikit-learn 的神经网络的特征影响 。对于这个例子,使用 scikit-learn 的 糖尿病数据集,它是一个回归数据集。首先安装shap库。
!pip install shap
然后,让导入库。
import shap
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
现在可以加载的数据集和特征名称,这将在以后有用。
X,y = load_diabetes(return_X_y=True)
features = load_diabetes()['feature_names']
现在可以将数据集拆分为训练和测试。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
现在必须创建的模型。由于谈论的是神经网络,必须提前对特征进行缩放。对于此示例,我将使用标准缩放器。该模型本身是一个前馈神经网络,在隐藏层有 5 个神经元,10000 个 epoch 和一个具有自适应学习率的逻辑激活函数。在现实生活中,您将在设置这些值之前适当地优化这些超参数。
model = make_pipeline(
StandardScaler(),
MLPRegressor(hidden_layer_sizes=(5,),activation='logistic', max_iter=10000,learning_rate='invscaling',random_state=0)
)
现在可以拟合的模型。
model.fit(X_train,y_train)
现在是 SHAP 部分。首先,需要创建一个名为explainer的对象。它是在输入中接受模型的预测方法和训练数据集的对象。为了使 SHAP 模型与模型无关,它围绕训练数据集的点执行扰动,并计算这种扰动对模型的影响。这是一种重采样技术,其样本数量稍后设置。这种方法与另一种称为 LIME 的著名方法有关,该方法已被证明是原始 SHAP 方法的一个特例。结果是对 SHAP 值的统计估计。
所以,首先让定义解释器对象。
explainer = shap.KernelExplainer(model.predict,X_train)
现在可以计算形状值。请记住,它们是通过对训练数据集重新采样并计算对这些扰动的影响来计算的,因此必须定义适当数量的样本。对于此示例,我将使用 100 个样本。
然后,在测试数据集上计算影响。
shap_values = explainer.shap_values(X_test,nsamples=100)
出现一个漂亮的进度条并显示计算的进度,这可能很慢。
最后,得到一个 (n_samples,n_features) numpy 数组。每个元素都是该记录的该特征的 shap 值。请记住,形状值是针对每个特征和每个记录计算的。
现在可以绘制“summary_plot”。
shap.summary_plot(shap_values,X_test,feature_names=features)
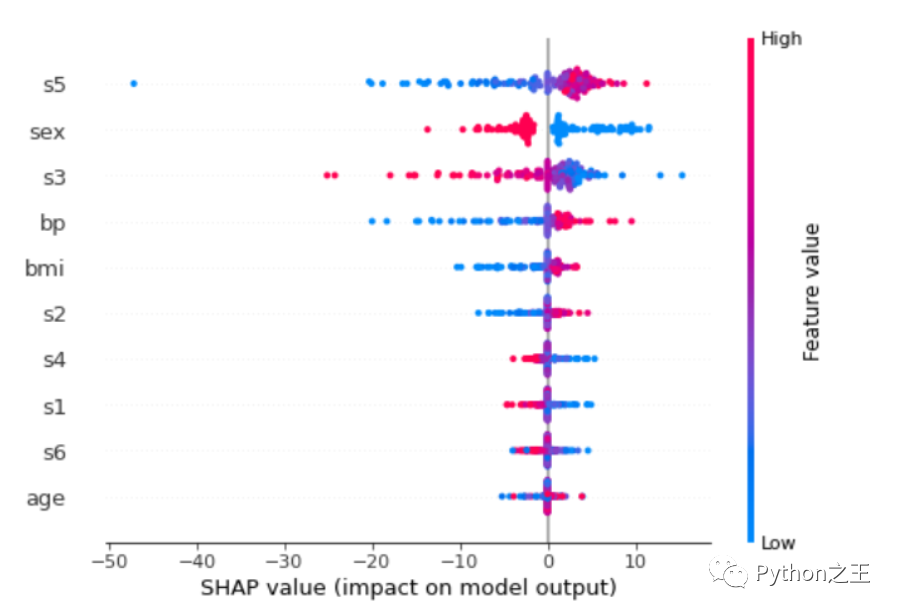
每行的每个点都是测试数据集的记录。这些特征从最重要的一个到不太重要的排序。可以看到s5是最重要的特征。该特征的值越高,对目标的影响越积极。该值越低,贡献越负。
更深入地了解特定记录,可以绘制的一个非常有用的图称为force_plot
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0,:] ,X_test[0,:],feature_names=features)

113.90 是预测值。基值是目标变量在所有记录中的平均值。每个条带都显示了其特征在将目标变量的值推得更远或更接近基值方面的影响。红色条纹表明它们的特征将价值推向更高的价值。蓝色条纹表明它们的特征将值推向较低的值。条纹越宽,贡献越高(绝对值)。这些贡献的总和将目标变量的值从花瓶值推到最终的预测值。
对于这个特定的记录,bmi、bp、s2、sex和s5值对预测值有正贡献。s5仍然是这条记录中最重要的变量,因为它的贡献是最宽的(它具有最大的条带)。唯一显示负贡献的变量是s1,但它不足以使预测值低于基值。因此,由于总的正贡献(红色条纹)大于负贡献(蓝色条纹),因此最终值大于基值。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: