
无需NMS、二分匹配的一阶段端到端目标检测网络,港大提出OneNet

极市导读
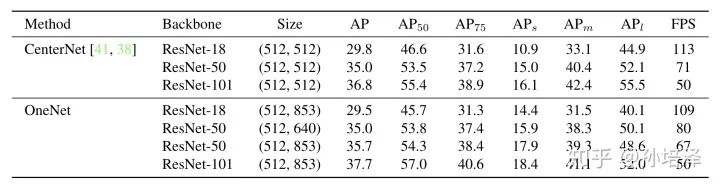
由于各种复杂的layer的存在不容易部署,而one-stage在工业应用中有着更大的潜力,作者团队提出了OneNet,首次实现了end-to-end dense detector without NMS。本文详细解释了OneNet的相关架构及优势,并给出了相关实验的结果表格:OneNet在标准的COCO benchmark上达到了37.7 AP / 50 FPS,35.0 AP / 80 FPS。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1. 简介
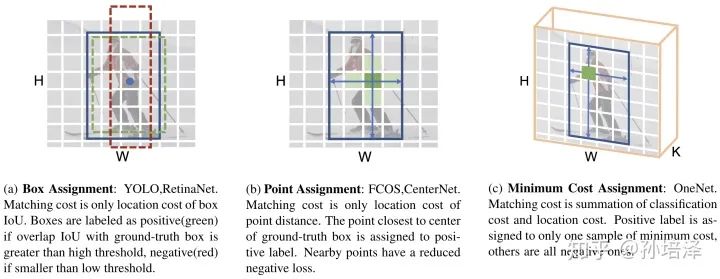
整个网络是全卷积的,没有各种非常规的layer(比如GN,RoI-Align,Dynamic Conv)。 无需Non-Maximum Suppression(NMS)后处理或者self-attention模块。 样本匹配策略是简单的Minimum Cost,无需启发式规则或者复杂的最优二分匹配。
2. OneNet
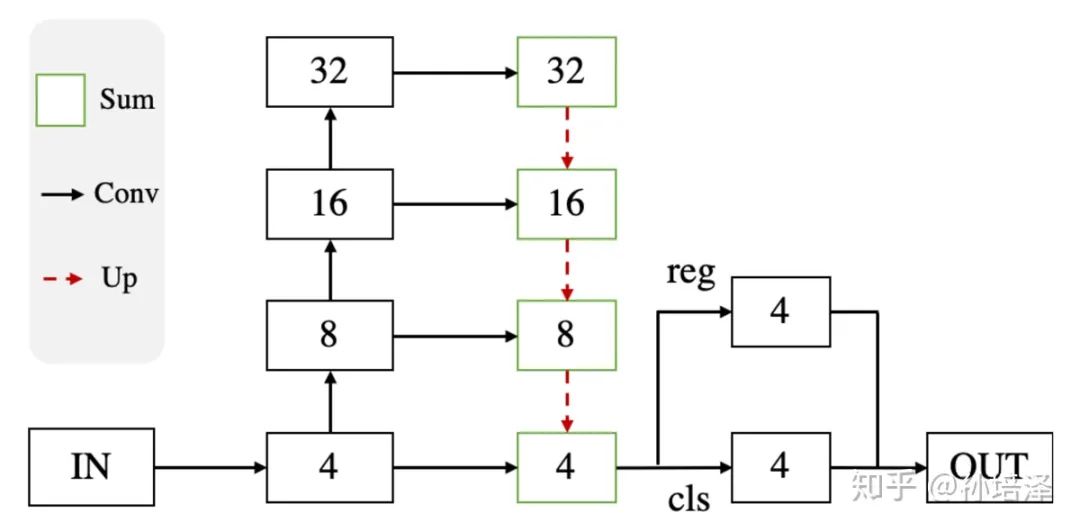
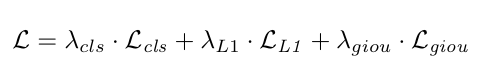
# C is cost matrix, shape of (nr_sample, nr_gt)
C = cost_class + cost_l1 + cost_giou
# Minimum cost, src_ind is index of positive sample
_, src_ind = torch.min(C, dim=0)
tgt_ind = torch.arange(nr_gt)3. 实验
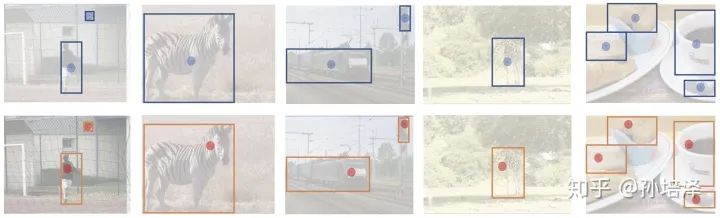





4. 讨论

5. 彩蛋
推荐阅读

评论