
端到端伪激光图像3D目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文由博主: 授权转载,二次转载请联系原作者
原文地址:https://blog.csdn.net/qq_26623879/article/details/109234324
End-to-End Pseudo-LiDAR for Image-Based 3D Object Detection
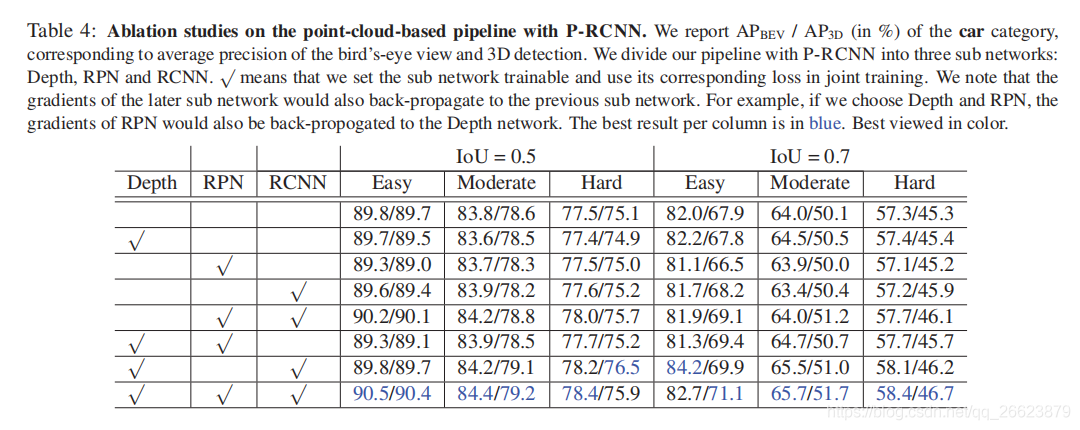
自主驾驶是安全、准确检测三维物体的必要条件。尽管激光雷达传感器可以提供精确的三维点云环境估计值,但在许多情况下,它们的成本也高得让人望而却步。最近,伪激光雷达(PL)的引入使得基于LiDAR传感器的方法与基于廉价立体相机的方法之间的精度差距大大缩小。PL通过将二维深度图输出转换为三维点云输入,将用于三维深度估计的最新深度神经网络与用于三维目标检测的深度神经网络相结合。然而,到目前为止,这两个网络必须分开训练。在本文中,我们介绍了一个新的框架,它基于可微的表示变化(CoR)模块,允许对整个PL管道进行端到端的训练。该框架与大多数最先进的网络兼容,适用于这两项任务,并与PointRCNN相结合,在所有基准测试中始终优于PL—在提交时,在基于KITTI图像的3D目标检测排行榜上获得了最高的排名。
基于激光雷达的方法存在问题
目标检测严重依赖与3D point的准确性,位置和检测需要近似object surfaces
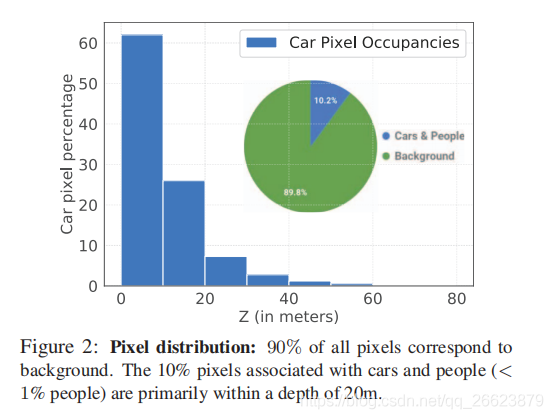
不能够检测到远处的目标,由于车和人在图像中只占10%(kitti),受激光范围限制,训练的时候会忽略远处的物体当前伪激光雷达存在的问题
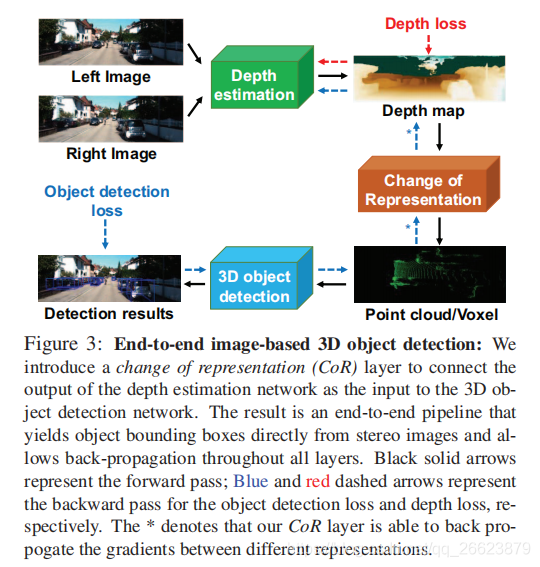
没有实现端到端的深度预测和目标检测联合训练
本文提出的端到端框架解决不能够联合训练的缺点。其中,错误检测或错误定位对象的错误信号可以“softly attend ”影响预测最大的像素(可能是2D中对象上或周围的像素),引导深度估计器为后续检测器改进提供依据。为了使来自最终检测损失的误差信号反向传播,深度估计器和目标检测器之间的表示变化(CoR)必须相对于估计的深度是可微的。
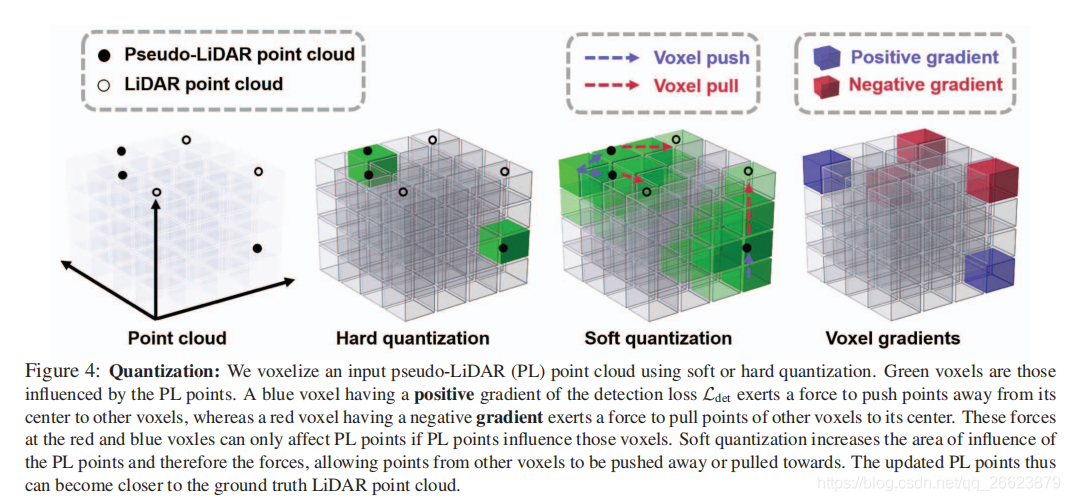
本文确定了两种主要的CoR类型-子采样和量化-将现有的基于LiDAR的探测器合并到伪LiDAR框架中。
三维点的位置被离散成一个固定的网格,在得到的张量1中只记录占用(即{0,1})或密度(即[0,1])。这种方法的优点是可以直接应用二维和三维卷积从张量中提取特征。然而,这种离散化过程使得反向传播变得困难。

本文引入了一个 radial basis function(RBF)在给定的面元m的中心ˆpm附近,而不是二进制占用,这样保持了一个“Softly”计数的点,由RBF加权。进一步地,允许任何给定的m受到close bins Nm的影响。然后我们相应地修改了T的定义。让Pm表示落入bin m的点集:

首先,我们去除所有高于激光雷达信号可以覆盖的正常高度的3D点,例如天空的像素点。此外,我们还可以通过亚抽样来稀疏化剩余的点。第二步是可选的,但在[45]中建议使用,因为深度图生成的点数量比激光雷达大得多:伪激光雷达信号中平均有300000个点,而激光雷达信号中有18000个点(在汽车的正面视图中)。虽然密集的表示在精确度方面是有利的,但它们确实减慢了目标检测网络的速度。我们采用了一种基于角度的稀疏化方法。我们通过将球坐标(r,θ,φ)离散化来定义三维空间中的多个料仓。具体来说,我们离散θ(极角)和φ(方位角)来模拟激光雷达光束。然后我们保持一个单一的三维点(x,y,z)的球坐标落在同一个箱子里。因此,生成的点云模拟真实的激光雷达点。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~