
目标检测系列 | 无NMS的端到端目标检测模型,超越OneNet,FCOS等SOTA!


全卷积检测器放弃一对多匹配,采用一对一匹配策略实现端到端检测,但存在收敛速度慢的问题。在本文中重新审视了这两种匹配方法,发现将一对多匹配带回端到端全卷积检测器有助于模型收敛。
基于这一观察,作者提出了端到端全卷积检测(DATE)的双重匹配。本文的方法在训练期间构造了两个具有一对多和一对一匹配的分支,并通过提供更多监督信号来加快一对一匹配分支的收敛。DATE只使用带有一对一匹配策略的分支进行模型推理,这不会带来推理开销。
实验结果表明,Dual Assignment在OneNet和DeFCN上提供了显著的改进,并加快了模型的收敛速度。
代码:https://github.com/YiqunChen1999/date
1、简介
单阶段目标检测器,例如RetinaNet和FCOS,因其简单性而被社区广泛采用。尽管他们取得了成功,但一对多匹配(o2m)策略使他们依靠非最大抑制(NMS)来消除重复的预测。这种过程使它们对NMS的超参数敏感,并可能导致次优解决方案。
这个问题促使研究人员消除NMS,以实现端到端的完全卷积目标检测。OneNet受到DETR的启发,讨论了端到端检测的原因。通过对匈牙利匹配进行详细的实验,OneNet认识到具有分类成本的一对一匹配(o2o)策略是端到端检测的关键。具体而言,通过考虑分类成本,仅为GT分配一个预测,可以防止其产生冗余预测。
尽管OneNet很简单,并实现了端到端检测,但它存在收敛速度慢的问题。作者的研究表明,OneNet需要比FCOS更多的训练时间来实现具有竞争的性能。结果,在相同的设置下,采用一对一分配策略训练的模型要比采用一对多分配策略的模型差。然而,如上所述,一对多正样本分配策略使得NMS有必要在推断过程中删除重复预测。
基于这些观察结果,我们很自然地会问:我们能在相同的环境下训练出具有竞争力的端到端检测器吗?

在本文中答案是肯定的。假设OneNet收敛速度较慢的原因是一对一分配策略对特征提取器的监督较弱。具体而言,一对一分配策略提供的正样本比一对多匹配少,导致特征提取器缺乏分类和回归监督信号。上述发现激励作者结合一对一和一对多匹配策略的优势。作者将一对多分配策略重新引入OneNet,并提出了一种双任务分配(DATE)来解决这个问题。
具体来说,如图1所示联合训练一对多匹配和一对一匹配分支。一旦完成训练,只使用一对一正样本分配来保持预测器的训练,以实现端到端检测。
实验结果表明,双重分配策略加快了端到端检测器的收敛速度。经过12和36个Epoch的训练,本文的无NMS DATE可以超越或与基于NMS的同行持平。由于轻量级的一对多匹配分支(例如,只有两个或三个卷积层),在训练过程中几乎不需要额外的计算资源,但在模型推断方面可以显著提高性能。
贡献总结如下:
提出了一种双分配策略,通过引入更多监督信号来加快端到端全卷积检测器的收敛。 提出的双重分配策略在训练期间引入了可忽略不计的成本,在推断期间没有开销。 基于提出的双重分配策略,与基于一对多匹配策略的模型相比,本文简单而有效的DATE实现了具有竞争力的性能或略好的性能。
2、本文方法
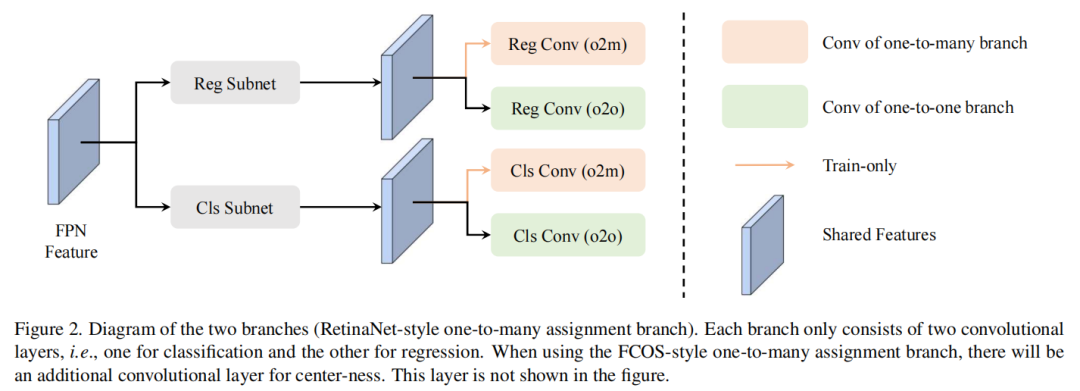
为了克服一对一匹配缺乏监督信号(即很少有正样本)的缺点,作者提出了端到端全卷积检测器(DATE)的双重匹配,如图2所示。在典型的单阶段检测器之后,本文的架构将图像作为输入,并提取多尺度特征用于分类和回归。本文的多尺度特征提取器由主干、特征金字塔网络和两个子网组成。然后,Dual Assignment在训练期间按照特征提取器构造两个分支(Bo2o和Bo2m),并且在推理期间只保留一个分支用于端到端检测。
2.1、Dual Assignment
本文方法的一个重要概念是双重匹配。匹配策略将一个GT分配给一个或多个预测以监督网络。双重匹配策略在训练期间使用不同的样本匹配策略构建了两个分支。第一个分支由Bo2o表示,采用一对一匹配策略进行训练(图1,底部)。第二个名为Bo2m,在训练期间采用一对多匹配政策(图1,顶部)。这些分支将共享的分类特征和回归特征作为输入进行预测。然后,他们的匹配策略将构建(GT、预测)对来计算损失。
优化DATE是一个多目标优化问题。理想情况下希望寻求一种乌托邦解决方案,同时最大限度地减少两个分支的损失。然而,一个解很难同时是不同任务的目标函数的局部极小值。获得帕累托边界的帕累托最优解是一个更常见的选择。
由于多目标优化问题有无限个帕累托解,通常需要做出决定,从中选择一个或一些。理想情况下,优化过程应该反映用户的偏好。最常见的方法之一是权重和方法,它为每个目标函数匹配权重:
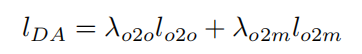
其中和分别是一对一和一对多匹配分支的损失。,分别是和的权重。直觉上,相对较大的权重意味着相应的目标函数比其他函数更重要。例如,在极端情况下,如果将等式(1)中的置为零,则它将退化为只训练一对一分支,而不关心一对多分支,反之亦然。
1、One-to-one Assignment Branch
如图2所示,这个称为的分支由两个卷积层组成,一个用于分类,另一个用于回归。一对一匹配策略将一个GT分配给一个预测,并构建G(GT,预测)对,其中G是一个图像中注释目标的数量。不符合任何GT的预测是负样本。通常,采用匈牙利匹配损失或质量度量作为一对一匹配算法。作者通过遵循OneNet以一对一的匹配来训练这个分支,但使用POTO作为质量度量。通过以下方式监督该分支结构:
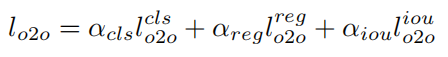
其中、和分别为分类、回归和IoU损失。、和是相应损失的权重。这些权重与OneNet相同。
2、One-to-many Assignment Branch
一对多匹配将一个GT分配给多个预测,并构造N个(GT,预测)对,例如最大IoU匹配策略。通常N>G。主要考虑广泛研究的单阶段检测器RetinaNet和FCOS来构建这个分支()。具体而言,DATE采用了两层RetinaNet卷积层或三层FCOS。通过最小化以下内容来训练该分支:
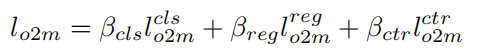
其中和是FCOS中心度预测的权重和损失函数。其他符号的含义类似于一对一分支。RetinaNet的为0,因为RetinaNet中没有中心度预测。一旦完成训练,将放弃这一分支。权重保持与RetinaNet或FCOS相同。
2.2、Discussion
一对一匹配只提供与GT相同数量的正样本,这小于一对多匹配策略。假设用一对一匹配策略训练的检测器的缓慢收敛问题主要是由于监督信号不足而发生的。由于缺乏足够的正样本,特征提取器可能需要更多的训练迭代来产生用于分类和回归的合适特征。
相反,一对多匹配策略将多个正样本分配给GT。假设,足够数量的正样本减少了更多训练迭代的必要性。然而,一对多匹配策略依赖于NMS来删除重复的预测。
双重任务结合了一对一和一对多任务的优点。一对多匹配分支提供足够的监督信号以加快共享多尺度特征提取器的训练。一对一匹配分支的作用类似于接收和调整特征以进行端到端检测。
作者猜测一对多匹配策略有助于缓解优化问题,使一对一匹配分支更专注于拟合所接收的表示。在第4.6节中根据经验表明,由一对多分支监督的特征提取器是加速DATE收敛的重要因素。
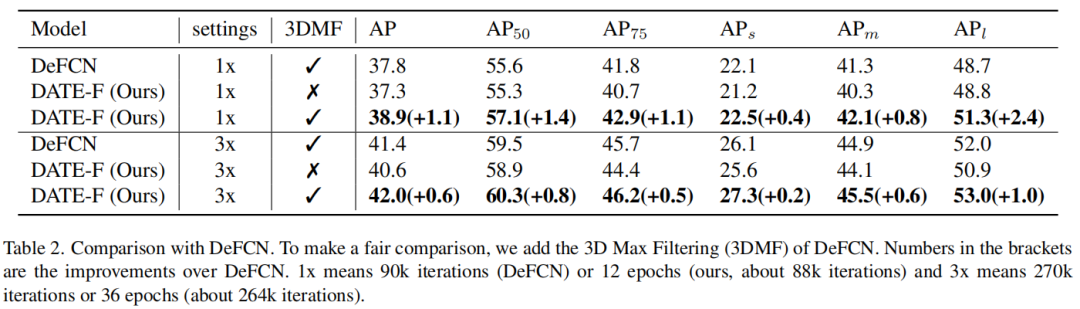
训练DATE就像训练两个参数共享的网络,然后在推理过程中丢弃其中一个(例如,一对多匹配分支)。这种设计不会在模型推断过程中引入任何开销。由于共享参数,DATE在训练期间只引入了微不足道的成本,使其对资源有限的机器友好。所提出的双重匹配使本文的方法与一对一匹配分支的修改正交,从而可以集成其他改进。在第4.3节中表明,改进一对一匹配分支可以进一步提高性能。
3、实验
3.1、DATE的优势
3.2、Promising Extension to DATE
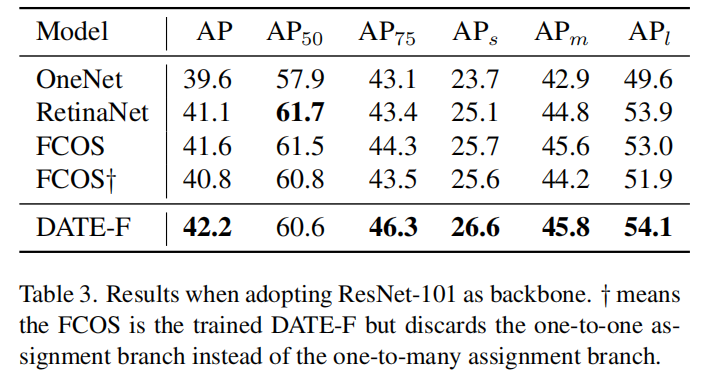
3.3、更强的骨干
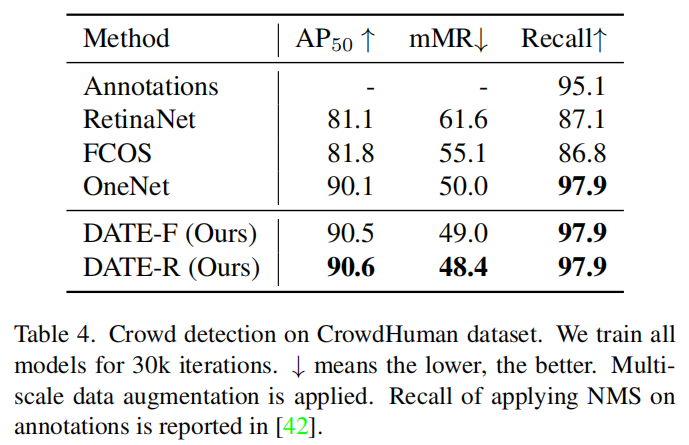
3.4、拥挤的场景检测
3.5、为什么要进行双重匹配?
1、Basic Observations
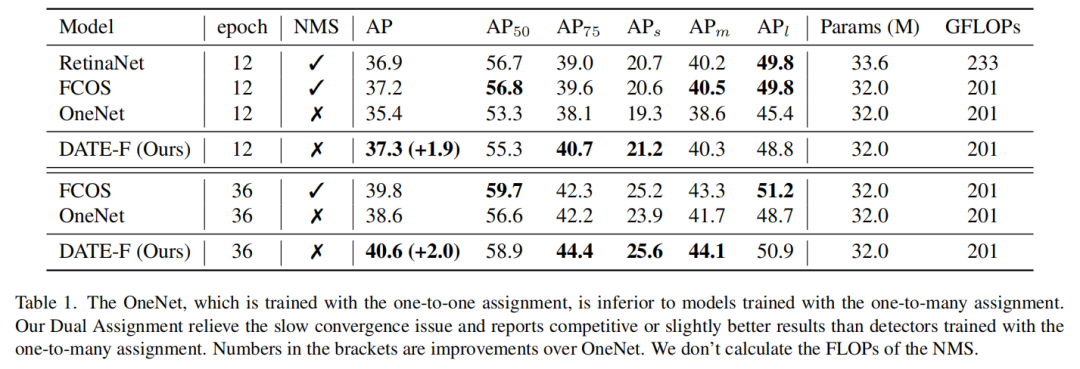
如表1所示,与OneNet(使用一对一匹配策略训练)相比,使用一对多匹配策略训练的检测器收敛更快,即使它们具有类似的架构。例如,经过12个Epoch的训练后,RetinaNet和FCOS分别报告了36.9 AP和37.3 AP。相比之下,本文OneNet基线性能为35.4 AP,远低于RetinaNet和FCOS。这些结果表明,一对多匹配在更快收敛方面可能很重要。假设充分的正样本有助于一对多分配模型的收敛。假设一对多匹配有助于共享特征提取器的学习,并进一步加快一对一指派分支的收敛。
2、关于训练有素的特征提取器
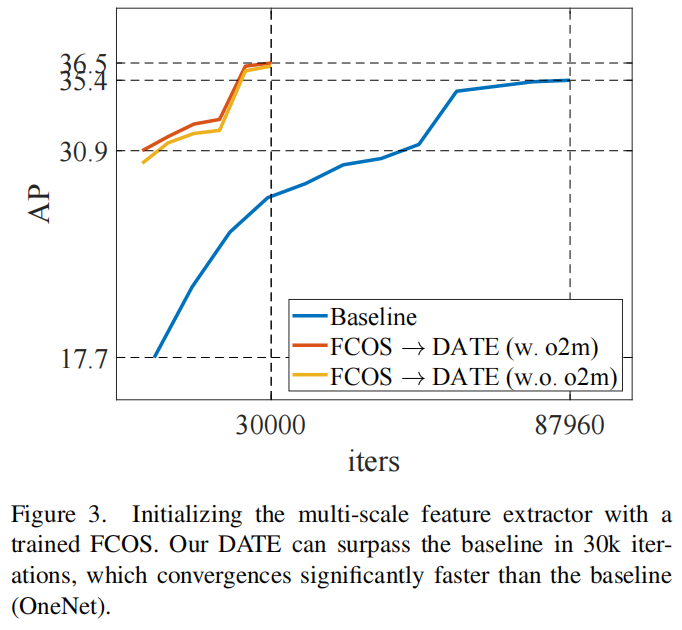
首先设计实验来验证由一对多匹配监督的特征提取器的重要性。使用经过训练的FCOS初始化DATE的多尺度特征提取器。一对一匹配分支保持随机初始化状态。将最大迭代次数设置为30000次。其他设置与从头开始训练DATE保持相同,例如,一起训练两个分支。
图3中的结果表明,只有约三分之一的训练时间足以超过普通OneNet,即36.5 AP,而OneNet的35.4 AP。将这种现象归因于初始化良好的特征提取器。在例子中,经过训练的特征提取器适用于一对多匹配分支。一对一匹配分支所需的特性可能类似于一对多匹配分支,这里只需要进行一些调整。
进一步从DATE中删除一对多任务,只训练一对一任务分支。结果表明,一对多匹配分支对训练有素的特征提取器的影响有限,即最终性能降至36.3 AP(0.2 AP)。
这些现象表明,无论是否存在一对多匹配分支,训练有素的特征提取器对于用一对一匹配训练的检测器来说都是重要的。然而,从头学习此类模型的过程很慢,例如OneNet。假设差异在于正样本的数量。这些观察促使提出双重任务。通过引入用一对多匹配策略训练的分支,双重匹配提供了更多的积极样本来监督特征提取器的学习。
3、论双重匹配的引入
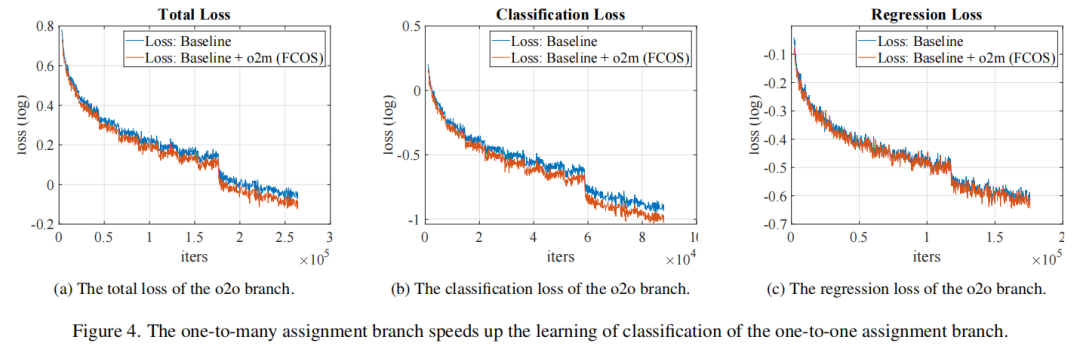
引入的一对多匹配使得一对一匹配分支收敛更快。图4中的经验证据表明,一对多匹配分支主要通过减少分类损失来加快一对一匹配分支的收敛。假设共享的多尺度特征提取器起着重要作用。一对多匹配比一对多匹配分支生成更多的正样本,这可以通过减少更多训练迭代的必要性来加快特征提取器的收敛。作者猜测,较早的收敛使得特征提取器产生用于分类的“一般”特征。因此,一对一匹配分支可能主要调整其参数以适应表示。
3.5、消融实验
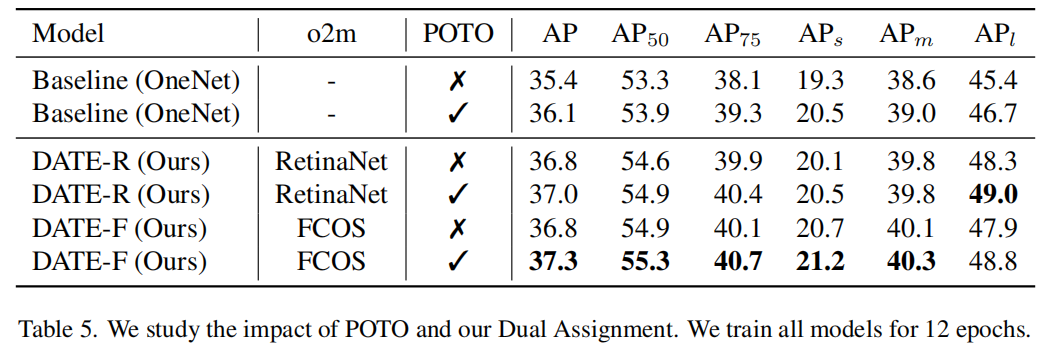
1、Dual Assignment and POTO
2、About NMS

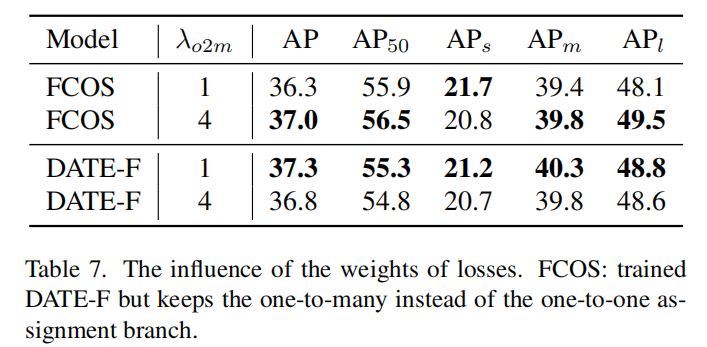
3、Weights of Losses
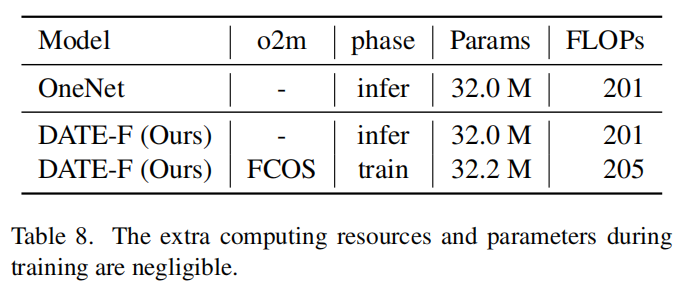
4、Training Cost
5、Not Sharing Subnets

4、参考
[1].DATE: Dual Assignment for End-to-End Fully Convolutional Object Detection.
5、推荐
目标检测落地技能 | 拥挤目标检测你是如何解决的呢?改进Copy-Paste解决拥挤问题!
量化加速系列 | 一文带你对YOLOv5使用PTQ和QAT进行量化加速!!!
ViT系列 | 24小时用1张GPU训练一个Vision Transformer可还好?
扫描上方二维码可联系小书童加入交流群~
想要了解更多前沿AI视觉感知全栈知识【分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF】、行业技术方案【AI安防、AI医疗、AI自动驾驶以及AI元宇宙】、AI模型部署落地实战【CUDA、TensorRT、NCNN、OpenVINO、MNN、ONNXRuntime以及地平线框架等】,欢迎扫描下方二维码,加入集智书童知识星球,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!