
Instant-Teaching: 端到端半监督目标检测框架
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


极市导读
本文是来自阿里团队的工作,作者团队重新审视SSOD并提出InstantTeaching,这是一个完全端到端且有效的SSOD框架,该框架使用即时伪标签和扩展的弱-强数据增强功能在每次训练迭代中进行教学。
简单介绍一下我们CVPR 2021的一项关于半监督目标检测方面的工作:
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
论文链接:https://arxiv.org/pdf/2103.11402.pdf
1. 背景
1.1 为什么需要半监督学习
这些年,数据驱动的深度学习技术在各种视觉任务中(图像分类、目标检测,实例分割,视频检测等)大展身手,屠榜各类benchmark。然而,在实际落地这些深度学习技术时,我们会发现,模型的性能严重依赖带标注的训练数据。比如,在不同场景上线相同功能的检测模型时,往往需要花费较大代价获取足够数量的标注数据来提高模型在相应场景下的性能。
模型对数据的依赖主要体现在以下两个方面:
对应用场景一致数据的依赖:以人体检测模型为例,在室外数据上训练的检测器,在室内场景的检测效果往往差强人意;在白天数据上训练的检测器,在夜晚场景下的效果通常也不会很好。 对数据规模的依赖: 大数据集训练的模型往往比小数据集的精度要高。
虽然有标注数据的获取成本比较高,但是我们可以非常容易的获取海量的无标注数据,如何有效利用这些无标注数据来提高模型的性能,降低模型对标注数据的依赖?半监督学习正是研究如何高效利用无标注数据的一个热门研究方向。
1.2 现有的检测半监督工作
目前,最先进的检测半监督方面的工作,主要是基于self-training以及一致性约束。下面分别介绍其中的代表性工作。
1.2.1 基于一致性约束的方案
CSD[1]是当前基于一致性约束的检测半监督方面的代表性工作。通过对未标注数据做弱增强(flip),组成pair对输入给检测模型,然后对模型预测输出的pair结果进行一致性约束,从而尽可能利用到这些未标注数据。
1.2.2 基于self-training的方案
STAC[2]是当前基于self-training的检测半监督方面的代表性工作。首先所有标注数据训练一个Teacher模型,然后在所有未标注数据上做Inference,并通过NMS和卡阈值的方式制备pseudo labels作为未标注数据的ground truth,然后将所有标注数据和未标注数据同时加入训练得到最终的模型,该方法简单有效,是当前检测半监督方面的SOTA工作。
2. 我们的方案: Instant-Teaching
2.1 Motivation
如下图所示,我们提出了端到端的检测半监督方案Instant-Teaching和增强版Instant-Teaching*:
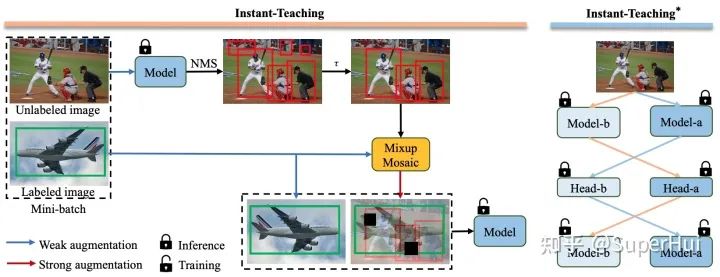
我们改进的motivation主要有三点:
我们发现,现有的检测半监督方面的SOTA方案STAC,其伪标注pseudo labels通过离线获得,并且在训练过程中是不更新的。这样有一个问题,当训练的半监督模型的精度已经超过生成pseudo labels的模型时,继续使用不更新的pseudo labels,会限制半监督模型精度的进一步提升。 data augmentations 在半监督学习中占据非常重要的位置,如何更有效的针对半监督学习设计更适合的数据增强方式? pseudo labels中容易存在错误label,尤其是在训练初期,并且这种错误会在半监督训练中累积,这种现象称为confirmation bias问题,如何设计矫正策略去尽可能修正这些错误的pseudo labels?
针对这三个问题,我们的检测半监督方案如下:
针对问题1,我们采用在线伪标注更新的方式。随着模型训练收敛,模型的精度提升的同时,在线生成的pseudo labels的质量也会得到及时的提高,从而反过来进一步促进模型的学习。 为了更有效的对unlabel images 进行数据增强,我们采用在labeled images 和 unlabeled images 之间进行Mixup和Mosaic增强。 针对confirmation bias 问题,我们提出了Co-rectify的方案,即同时训练两个模型,两个模型分别为彼此检查和纠正pseudo labels,从而有效抑制错误预测的累积,提高模型精度。值得注意的是,虽然在训练时,需要同时训练两个模型,但是infernece时,只需要使用单个模型即可,因此,不影响模型推理的速度。
2.2 主要实验结果
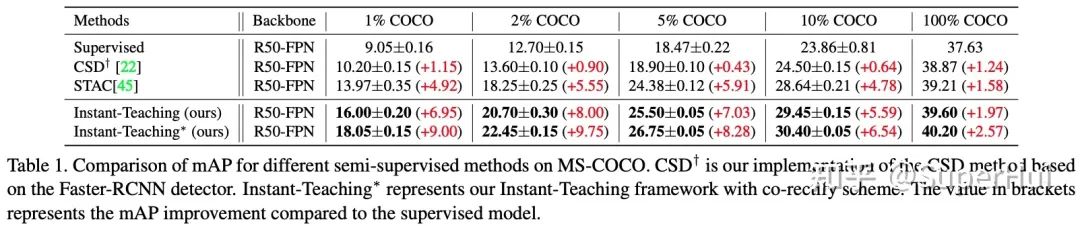
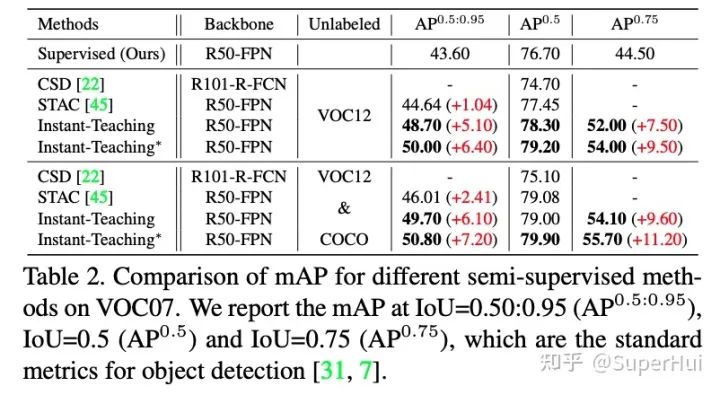
*更多实验验证,欢迎参考我们的论文原文:https://arxiv.org/pdf/2103.11402.pdf
[1]Consistency-based Semi-supervised Learning for Object Detection
[2]A Simple Semi-Supervised Learning Framework for Object Detection
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!