
北京大学提出RGB-D语义分割新网络,多模态信息融合
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


这篇文章收录于ECCV2020,由北京大学、商汤科技、香港中文大学提出的基于RGB-D图像的语义分割算法。充分考虑了RGB图像信息和深度信息的互补,在网络结构中引入了视觉注意力机制分别用于特征分离与聚合。最终在室内和室外环境的数据集上都进行了实验,具有良好的分割性能。
论文地址:http://xxx.itp.ac.cn/pdf/2007.09183v1
代码地址:https://github.com/charlesCXK/RGBD_Semantic_Segmentation_PyTorch
RGB-D信息就是标准的RGB图像信息中引入了深度信息,而深度信息可为RGB图像提供对应的几何关系。现有的大多数工作只是简单地假设深度测量是准确的,且与RGB像素能够良好地对齐,由此将该问题建模为交叉模式特征融合以获得更好的特征表示从而实现更准确的分割,但是,通常传感器无法获得令人满意的精准的深度结果,实际的深度数据通常比较嘈杂,这可能会随着网络的深入而降低分割的准确性。
本文提出了一个统一而有效的跨模态引导的编码器,该编码器不仅可以有效地重新校准RGB特征响应,而且还可以通过多个阶段来提取准确的深度信息,并将两者交替合并在一起重新校准的表示形式。提出的体系结构的关键是新颖的“分离与聚合gate”操作,该操作在交叉模态聚合之前共同过滤和重新校准两种表示形式。同时,一方面引入了双向多步传播策略,以帮助在两种形态之间传播和融合信息,另一方面,在长期传播过程中保持它们的特异性。
此外,提出的编码器可以轻松地注入到先前的编码器-解码器结构中,以提高其在RGB-D语义分割任务上的性能。在室内和室外具有挑战性的数据集上,本文的模型均始终优于最新技术。
简介
旨在为每个像素分配不同语义标签的语义分割是一项长期的任务。除了从视觉提示中利用各种上下文信息外,深度数据最近还被用作RGB数据的补充信息,从而提高了分割精度。深度数据通过为2D视觉信息提供3D几何形状,自然地补充了RGB信号,这对于照明的变化是稳定的,并有助于更好地区分各种对象。
尽管在RGB语义分割方面已经取得了重大进展,但是直接将互补深度数据输入到现有的RGB语义分割框架中或仅将两种模态简单地集成在一起可能会导致性能下降。将两种数据更好地融合关键挑战在于两个方面:
(1)RGB和深度模态之间的显著变化。RGB和深度数据显示出不同的特性,如何有效地识别它们之间的差异并将两种类型的信息统一为一种有效的语义分割方法,仍然是一个悬而未决的问题。
(2)深度测量的不确定性。现有基准提供的深度数据主要由飞行时间或Kinect,AsusXtion和RealSense等结构化摄像头捕获,由于物体材料的不同和测量距离范围的受限,深度测量通常比较嘈杂,噪声较多。如图1所示,该噪声在室外场景中更为明显,并导致错误的分割。

图1.(a)RGB-D baseline,采用常规的跨模态融合模式设计,导致RGB和深度模态之间存在实质性差异的区域分类不准确。(b)室外环境的深度测量数据比较嘈杂。若没有本文所提出的模块,分割结果将急剧下降。
现有的大多数基于RGB-D的语义分割算法的标准做法是使用深度数据作为另一种输入,并采用特定的特征融合方案(例如,基于卷积和基于模态的相似性的融合方案)的完全卷积网络(FCN)类架构,以融合两种模态的特征。然后将融合的特征用于重新校准RGB特征响应或用于预测结果。尽管这些方法为统一这两种信息提供了可行的解决方案,但其假设前提需要输入深度数据是准确的,并且与RGB信号良好对齐的假设可能不成立,从而使这些方法对噪声样本敏感。而且,如何确保网络充分利用两种方式的信息仍然是一个未解决的问题。最近,一些方法(《Pattern-affinitive propagation across depth, surface normal and semantic segmentation》)试图通过降低网络对深度测量质量的敏感性来应对第二个挑战。他们提议不通过使用深度数据作为额外的输入,而是建议通过多任务学习来提取深度特征,并将深度数据视为训练的额外监督。具体来说,《 Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing》介绍了一个两阶段框架,该框架首先预测包括深度估计在内的几个中间任务,然后将这些中间任务的输出用作最终任务的多输入。
在上述观察的基础上,本文提出在一个简单而有效的框架中解决这两个挑战,在类似FCN的RGB-D语义分割骨架中引入一种新型的跨模态引导编码器。所提出的框架的关键思想是利用两种模态的通道相关性和空间相关性,首先压缩squeeze深度的特殊特征响应,从而有效地抑制低质量深度测量的特征响应,然后利用被抑制的深度表示来完善RGB特征。在实际应用中,本网络设计的步骤是双向的,因为室内RGB源图像也含有噪声特征。与深度数据相比,RGB噪声特征通常是由不同邻近物体的相似外观引起的。我们将上述过程分别称为深度特征重新校准和RGB特征重新校准。因此,引入了一个新的门单元,即Separation-and-Aggregation Gate(SA-Gate),通过鼓励网络先重新校准和聚焦每个模态的特定特征,然后有选择地聚合两个模态的信息特征进行最终分割,以提高多模态表示的质量。为了有效地利用两种模态之间的特征差异,进一步引入了双向多步传播(Bi-direction Multi-step Propagation,BMP),鼓励两种流在编码器阶段的信息交互过程中更好地保持其特殊性。
本文方法
RGB-D语义分割需要将RGB和深度两种模态的特征集合起来,但两种模态都不可避免地存在噪声信息。具体来说,深度测量由于深度传感器的特性而不准确,而RGB特征可能会由于物体之间的高度外观相似性而产生混乱的结果。一个有效的跨模态聚合方案应该能够从每个特征中识别出它们的优势,以及将信息量最大的跨模态特征统一到一个有效的表示中。为此,本文提出了一种新型的跨模态引导编码器。图2(a)描述了所提出的方法的整体框架,它由一个跨模态引导编码器和一个分割解码器组成,给定RGB-D数据作为输入,编码器通过SA-Gate单元对两种模态的互补信息进行重新校准和融合,然后通过双向多步传播(BMP)模块将融合后的多模态特征和特定模态特征一起传播。然后,这些信息被分割解码网络解码,生成分割图。
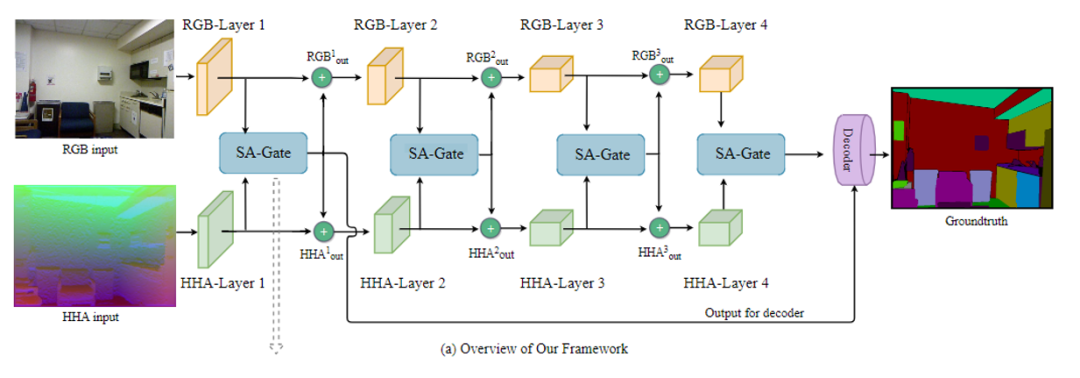
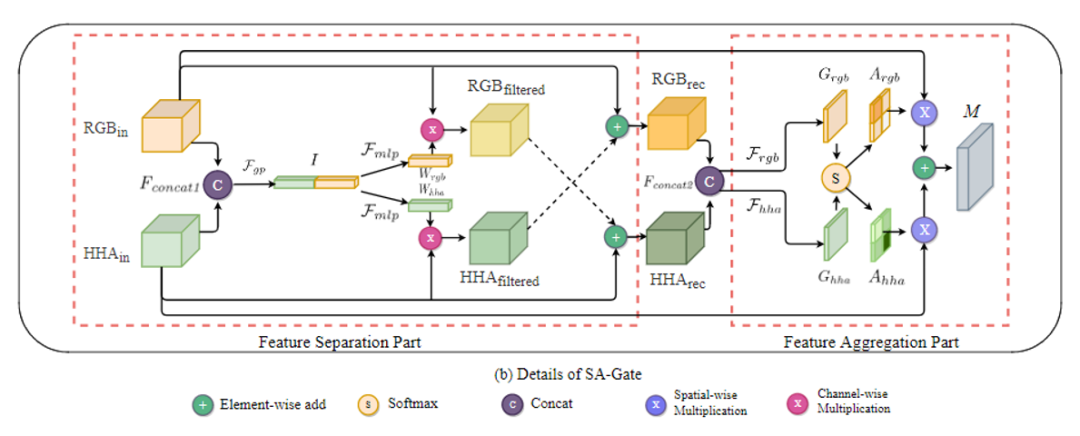
图2.(a)本文的网络结构概述。采用编码器解码器架构,网络的输入是一对RGB-HHA图像。在训练过程中,每对特征图(例如RGB-Layer1和HHA-Layer1的输出)由SA-Gate融合,并传播到编码器的下一级,以进行进一步的特征变换。第一个和最后一个SA-Gate的融合结果将传播到解码器结构(DeepLab V3 +)。(b)SA-Gate的体系结构,包含两个部分,特征分离(FS)和特征聚合(FA)
1、Bi-direction Guided Encoder
Separation-and-Aggregation (SA) Gate
为了确保信息在模态之间传播,SA-Gate设计有两个操作。一个是对每个单一模式进行特征重新校准,另一个是跨模式特征聚合。如图2(b)所示,这些操作是按照特征分离(FS)和特征聚集(FA)的部分进行的。
特征分离(Feature Separation)
以深度流为例。由于深度传感器的物理特性,如图3的第二列所示,深度模态中的噪声信号经常出现在靠近物体边界或深度传感器范围之外的局部表面的区域中。因此,该网络将首先过滤噪声信号围绕这些局部区域以避免在重新校准RGB模态和聚合跨模态特征的过程中产生误导性信息传播。实际上,利用RGB流中的高置信度激活函数来滤除相同level的异常深度。为此,应先嵌入这两种模态的全局空间信息,然后通过squeeze操作获取交叉模态注意向量。具体通过沿两个模态的通道方向维度进行全局平均池化(global average pooling)来实现此目的,然后进行串联和MLP操作以获得注意力向量。
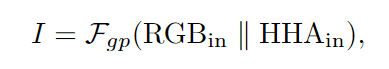
深度输入的跨模态注意力向量为
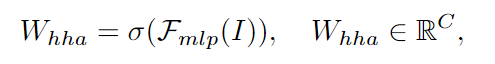
通过这样做,网络可以利用最有用的视觉外观和几何特征,并因此倾向于有效地抑制深度流中嘈杂特征的重要性。然后,可以通过在输入深度特征图和交叉模态门之间进行逐个通道的乘法来获得噪声较小的深度表示,即 Filtered HHA:
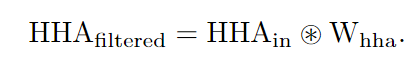
重新校准的公式为:
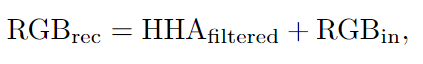
该公式背后的一般思想是,与其直接使用元素乘积来加权RGB特征(将深度特征视为重新校准系数),不如使用求和的操作视为一种偏移量,以在相应位置上改善RGB特征响应。
在实际应用中,作者以对称和双向的方式实现重新校准步骤,这样RGB流中的低置信度激活也可以以同样的方式被抑制,过滤后的RGB信息可以反过来重新校准深度特征响应,形成更稳健的深度表示HHArec。在图3中可视化了特征分离部分前后HHA的特征图。RGB对应的图见补充说明。

图3. 在CityScapes验证集中进行FSP之前和之后的深度特征的可视化比较。可以观察到,在FSP和无效的局部表面完成之后,分割对象具有更精确的形状。
class FilterLayer(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16):
super(FilterLayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_planes, out_planes // reduction),
nn.ReLU(inplace=True),
nn.Linear(out_planes // reduction, out_planes),
nn.Sigmoid()
)
self.out_planes = out_planes
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, self.out_planes, 1, 1)
return y
'''
Feature Separation Part
'''
class FSP(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16):
super(FSP, self).__init__()
self.filter = FilterLayer(2*in_planes, out_planes, reduction)
def forward(self, guidePath, mainPath):
combined = torch.cat((guidePath, mainPath), dim=1)
channel_weight = self.filter(combined)
out = mainPath + channel_weight * guidePath
return out
'''
SA-Gate
'''
class SAGate(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16, bn_momentum=0.0003):
self.init__ = super(SAGate, self).__init__()
self.in_planes = in_planes
self.bn_momentum = bn_momentum
self.fsp_rgb = FSP(in_planes, out_planes, reduction)
self.fsp_hha = FSP(in_planes, out_planes, reduction)
self.gate_rgb = nn.Conv2d(in_planes*2, 1, kernel_size=1, bias=True)
self.gate_hha = nn.Conv2d(in_planes*2, 1, kernel_size=1, bias=True)
self.relu1 = nn.ReLU()
self.relu2 = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
rgb, hha = x
b, c, h, w = rgb.size()
rec_rgb = self.fsp_rgb(hha, rgb)
rec_hha = self.fsp_hha(rgb, hha)
cat_fea = torch.cat([rec_rgb, rec_hha], dim=1)
attention_vector_l = self.gate_rgb(cat_fea)
attention_vector_r = self.gate_hha(cat_fea)
attention_vector = torch.cat([attention_vector_l, attention_vector_r], dim=1)
attention_vector = self.softmax(attention_vector)
attention_vector_l, attention_vector_r = attention_vector[:, 0:1, :, :], attention_vector[:, 1:2, :, :]
merge_feature = rgb*attention_vector_l + hha*attention_vector_r
rgb_out = (rgb + merge_feature) / 2
hha_out = (hha + merge_feature) / 2
rgb_out = self.relu1(rgb_out)
hha_out = self.relu2(hha_out)
return [rgb_out, hha_out], merge_feature
特征聚合(Feature Aggregation)
RGB和D功能彼此非常互补。为了充分利用它们的互补性,需要根据其表征能力在空间中的某个位置交叉互补地聚合特征。为实现此目的,考虑了这两种模态的特征,并为RGB输入和HHA输入生成了空间方向的门Gate,以通过软注意力机制控制每个模态特征图的信息流,如图2(b)所示,并用第二个红色框标记。为了使门更精确,使用了来自FS环节中重新校准的RGB和HHA特征图来生成门。具体地,首先将这两个特征图串联起来,以在空间中的特定位置组合它们的特征。然后,定义两个映射函数以将高维特征映射到两个不同的空间门:
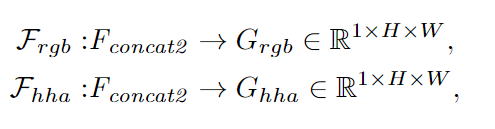
实际上,使用1×1卷积来实现此映射函数,并将softmax函数应用于这两个门:
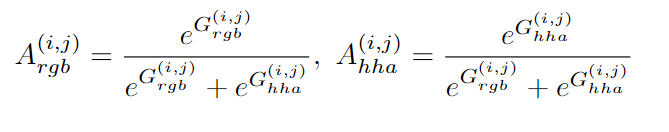
到目前为止,已经添加了门控RGB和HHA特征图以获得融合的特征图M。由于SA-Gate已注入编码器环节,因此将融合后的特征和原始输入取平均,分别获得RGBout和HHAout。
双向多步传播策略(BMP)
通过将每个位置的两个权重之和标准化为1,加权特征的数字比例将与输入RGB或HHA不会有显著差异。因此,它对编码器的学习或预训练参数的加载有负面影响。对于每个层L,我们使用由第L层 SA-Gate生成的输出M来改善编码器中第L层的原始输出:RGBout =(RGBin + M)/ 2,HHAout =(HHAin + M)/ 2。这是双向传播过程,经过改进的结果将被传播到编码器中的下一层,从而对两种模态进行更准确和有效的编码。
2、 Segmentation Decoder
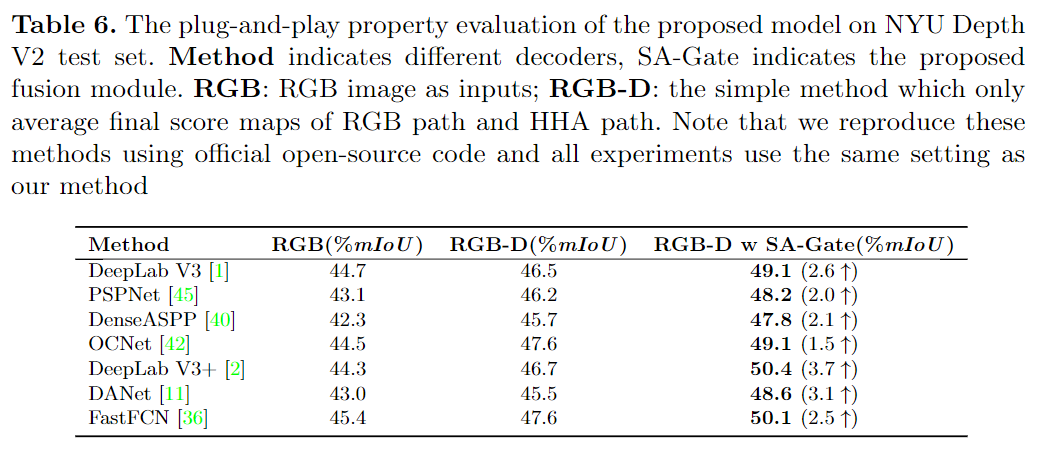
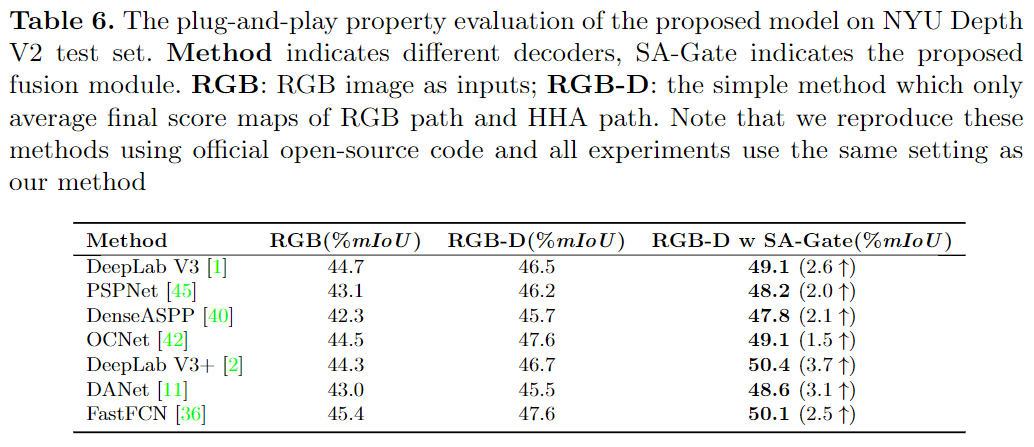
由于SA-Gate是即插即用模块,并且可以在编码器级充分利用交叉模态的互补信息,因此该解码器几乎可以采用基于SOTA RGB的分割网络中的解码器的任何设计。在表6中显示了将编码器与不同解码器组合在一起的结果。最终选择DeepLabV3 + 作为解码器,以实现最佳性能。
实验与结果
数据集与评价指标:室内NYU Depth V2和室外Cityscapes,实验中并不使用粗略标注数据,评价指标为像素精度PA和平均交并比mIoU
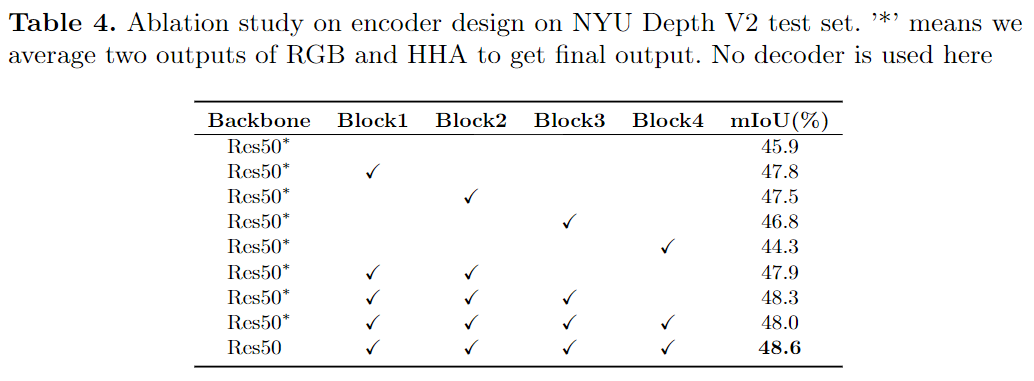
消融实验:



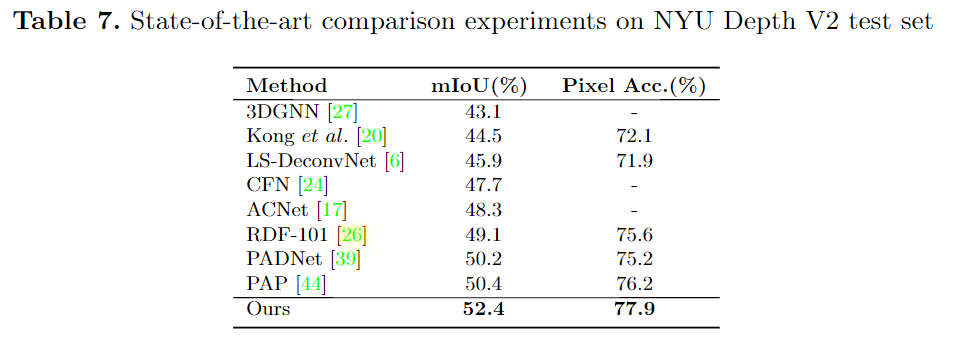
对比实验

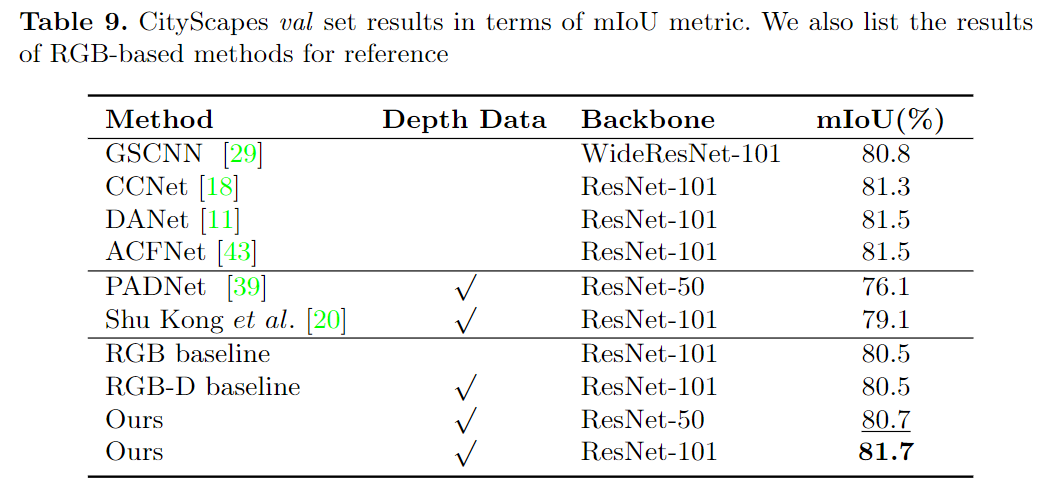
可视化对比




下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~