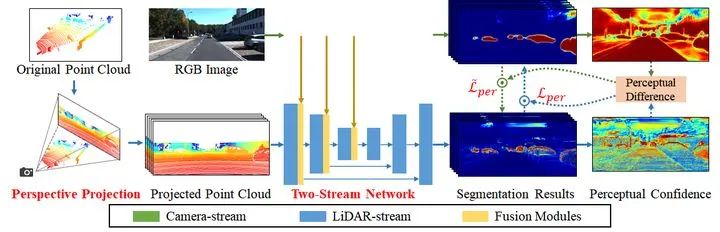
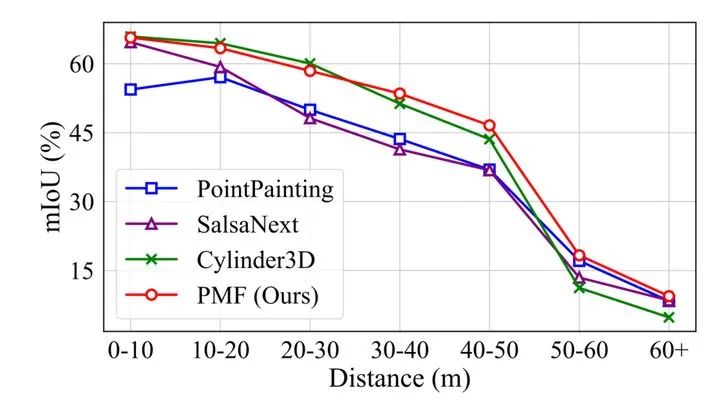
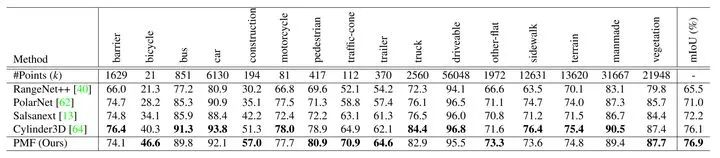
考虑到之前的方法一般采用球面投影的方式将点云投影到图像上,获取相关的像素信息,然后将相关的图像像素投影回点云空间,在点云空间上进行多传感器融合。而这导致了严重的信息损失。为了解决这个问题,作者提出基于透视投影的融合方法,通过把激光雷达数据投影到相机坐标系下,来保留足够多的相机传感器数据。把激光雷达数据投影到图像的过程借助已知的标定参数来实现。对于投影之后的每个激光雷达点,采用跟backbone方法SalsaNext[5]一样的设计,即保留(d, x, y, z, r)五个维度的特征。其中,d表示深度值。
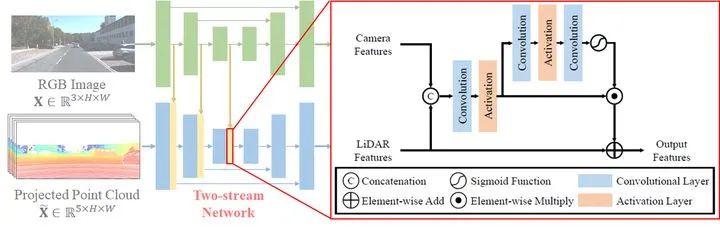
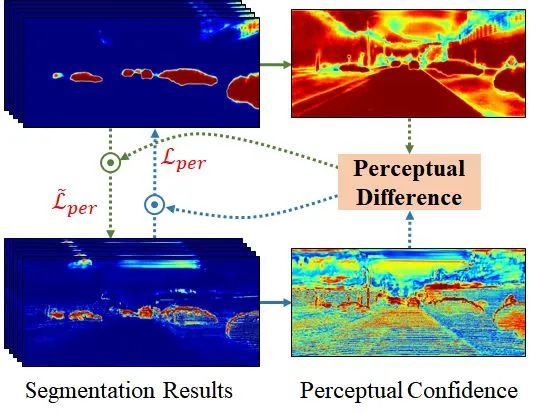
3.3. 模块二:Two stream network with residual-based fusion modules
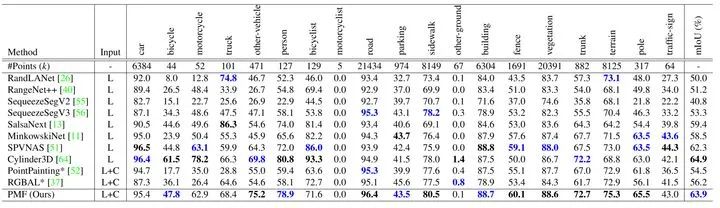
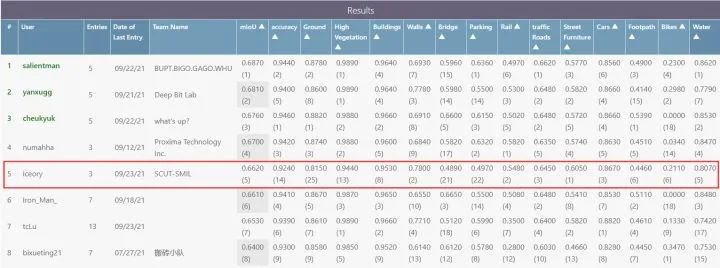
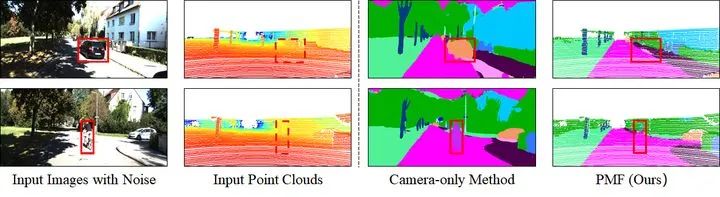
最后总结一下,本文提出了一个有效的融合相机和激光雷达数据的语义分割方法PMF。与现有的在激光雷达坐标系中进行特征融合的方法不同,本方法将激光雷达数据投影到相机坐标系中,使这两种模态的感知特征(RGB图像的颜色和纹理,激光雷达数据的几何形状)能够协同融合。在两个基准数据集上的实验结果和对抗攻击实验的结果表明了该方法的优越性。表明了,通过融合来自相机和激光雷达的互补信息,PMF对复杂的户外场景和光照变化具有高度的鲁棒性。未来,作者将尝试提高 PMF 的效率,并将其扩展到其他自动驾驶任务上。 论文连接Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation(https://openaccess.thecvf.com/content/ICCV2021/papers/Zhuang_Perception-Aware_Multi-Sensor_Fusion_for_3D_LiDAR_Semantic_Segmentation_ICCV_2021_paper.pdf) 代码连接GitHub - ICEORY/PMF: Perception-aware multi-sensor fusion for 3D LiDAR semantic segmentation (ICCV 2021)(https://github.com/ICEORY/PMF)
参考文献
[1] Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848.[2] Milioto, Andres, et al. "Rangenet++: Fast and accurate lidar semantic segmentation." 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019.[3] El Madawi, Khaled, et al. "Rgb and lidar fusion based 3d semantic segmentation for autonomous driving." 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019.[4] Vora, Sourabh, et al. "Pointpainting: Sequential fusion for 3d object detection." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.[5] Cortinhal, Tiago, George Tzelepis, and Eren Erdal Aksoy. "SalsaNext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds." International Symposium on Visual Computing. Springer, Cham, 2020.[6] Zhu, Xinge, et al. "Cylindrical and asymmetrical 3d convolution networks for lidar segmentation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.