
ECCV2020 商汤提出语义分割模型新范式
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:学术头条
【导读】在ECCV 2020 上,商汤自动驾驶团队提出了一种新型基于解耦优化思路的语义分割模型。现有的语义分割方法要么通过对全局上下文信息建模来提高目标对象的内部一致性,要么通过多尺度特征融合来对目标对象的边界细节进行优化。我们提出了一种新的语义分割方法,本文认为性能强的语义分割方法需要明确地建模目标对象的主体(body)和边缘(edge),这对应于图像的高频和低频信息。为此,本文首先通过warp图像特征来学习 flow field 使目标对象主体部分更加一致。在解耦监督下,通过对不同部分(主体或边缘)像素进行显式采样,进一步优化产生的主体特征和残余边缘特征。我们的实验表明,所提出的具有各种基准或主干网络的框架可有更好的目标对象内部一致性和边缘部分。我们提出的方法在包括 Cityscapes、CamVid、KITTI 和 BDD 在内的四个主要道路场景语义分割数据集上实现了 SOTA 的结果,同时保持了较高的推理效率。我们的方法仅使用精细标注的数据就可以在 Cityscapes 数据集上达到 83.7 mIoU。
挑战和动机
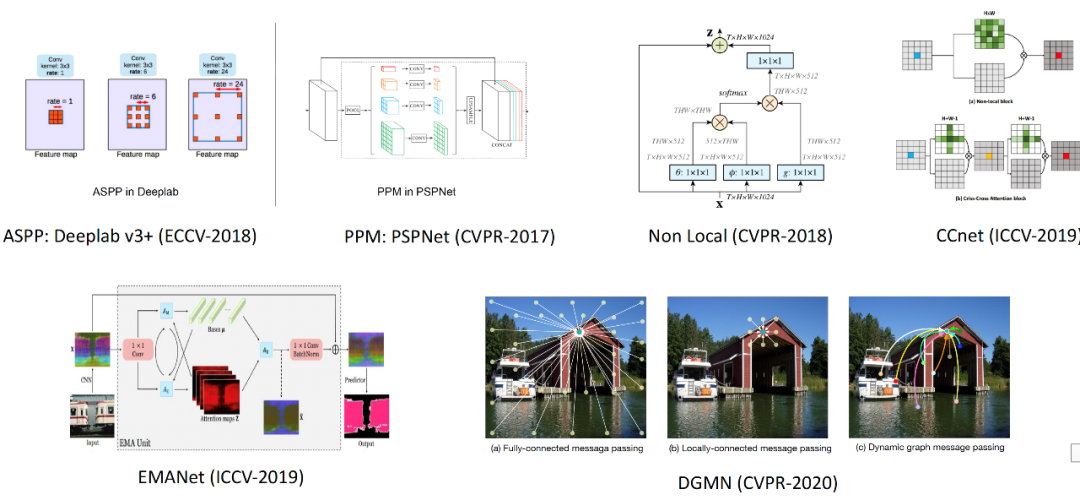
图2 较底层信息融合
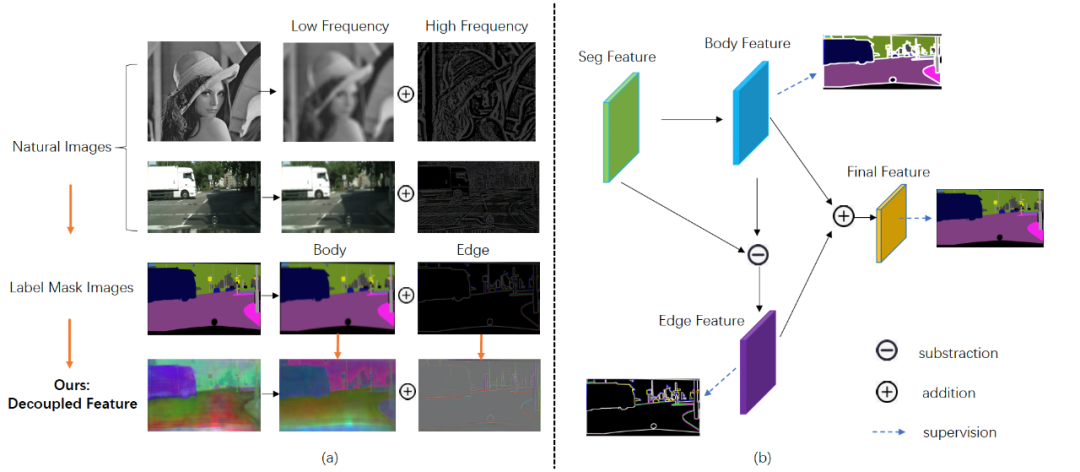
图3 动机示意图
方法介绍
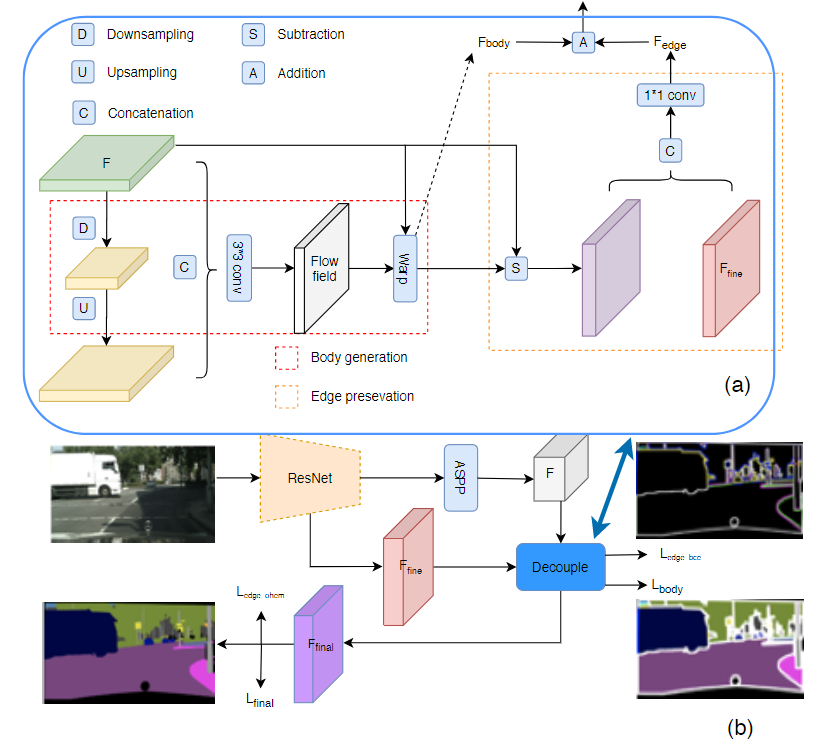
图4方法示意图
给定一个特征图 H×W×C,其中 C 表示通道尺寸,H×W 表示空间分辨率,所提出的模块输出具有相同大小的细化特征图。特征图可以分解为 body 主体部分和 edge 边缘部分。在本文中,假设它们满足加法规则,这意味着特征图 F:F = F_body + F_edge。本文模型目标是设计具有特定监督权的组件,分别处理每个部分。因此,首先通过执行 body 部分,然后通过显式减法获得边缘部分。主体生成模块旨在聚集对象内部的上下文信息并为每个对象形成清晰的主体对象。边缘保留模块用来保留更多的边缘信息,学习到更好的边缘特征。这两个模块采用不同的损失函数进行监督训练。
2,主体生成模块
主体生成模块负责为同一对象内的像素生成更一致的特征表示。因为物体内部的像素彼此相似,而沿边界的像素则显示出差异,因此可以显式地学习主体和边缘特征表示,为此,我们采用学习流场的方式(flow field),并使用 flow field 对原始特征图进行 warp 以获得显式的主体特征表示。该模块包含两个部分:flow field 生成和特征差值。
2.1,Flow field generation 流场生成
为了生成主要指向对象内部的流场,突出对象中心部分的特征作为显性引导是一种合理的方法。一般来说,低分辨率的特征图(或粗表示)往往包含低频项。低空间频率项捕捉了图像的总和,低分辨率特征图代表了最突出的部分,在这里我们将其视为伪中心位置或种子点的集合。如图 4(a)所示,我们采用了编码器-解码器的设计,编码器将特征图下采样为低分辨率表示,并有较低的空间频率部分,这里我们采用三次连续的 3×3 深度卷积来实现。对于 flow field 的生成,与 FlowNet-S 中做法一样。我们首先将低频特征图上采样插值到与原始特征图相同的大小,然后将它们连在一起,并应用 3×3 卷积层来预测流场。由于我们得模型都是基于带孔型的主干网络,因此这里 3×3 的卷积核足够大,在大多数情况下可以获取到像素之间的长距离依赖关系。
2.2,Feature warping 特征差值
我们使用可微分的双线性采样机制进行插值生成主体部分的每个点, 其过程如下面公式所示:
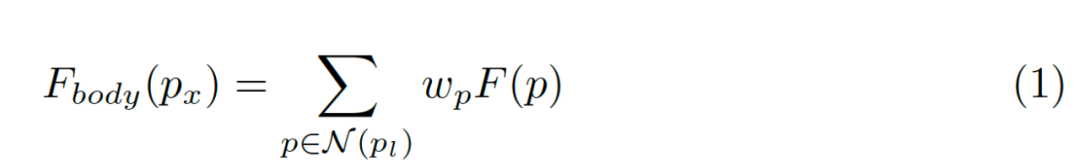
3,Edge preservation module边缘保留模块
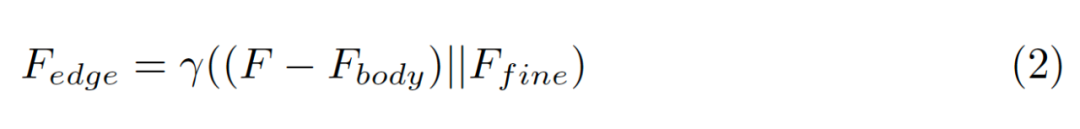
边缘保留模块旨在处理高频项。它还包括两个步骤:1)从原始特征图F中减去主体特征图;2)添加更精细的细节信息的低级特征作为补充。首先,从原始输入特征图F中减去主体特征,添加了额外的低级特征输入,以补充缺少的细节信息,以增强主体特征中的高频项。最后,将两者连接起来,并采用 1×1 卷积层进行融合。该模块可以用下面等式表示,其中 γ 是卷积层并且表示级联运算。
4,Decoupled body and edge supervision解耦的损失函数
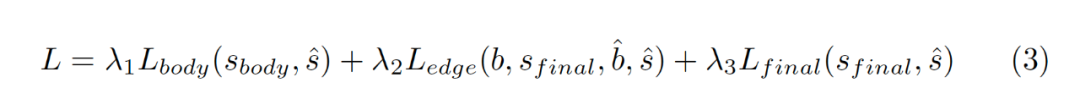
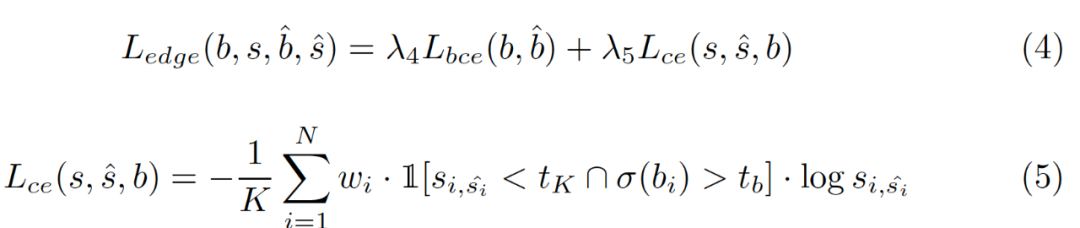
实验部分
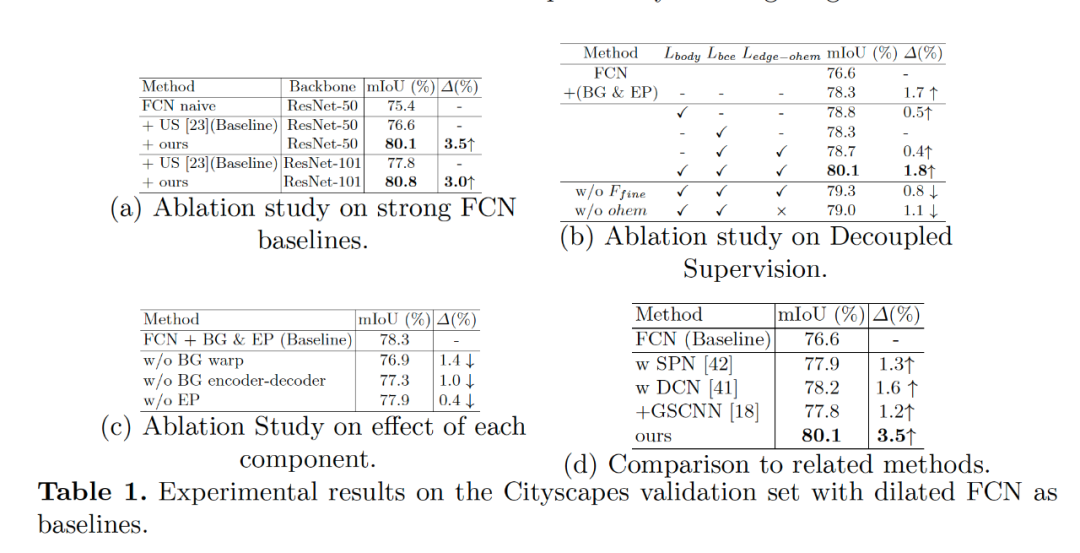
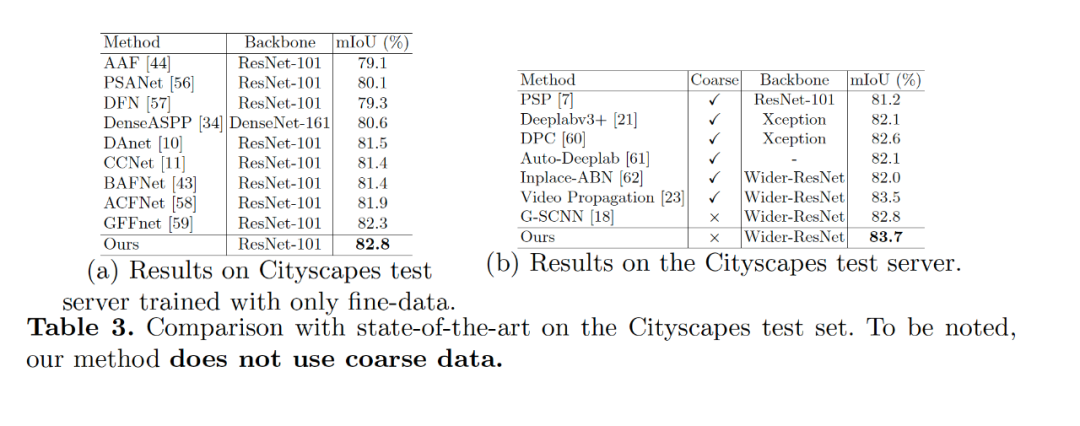
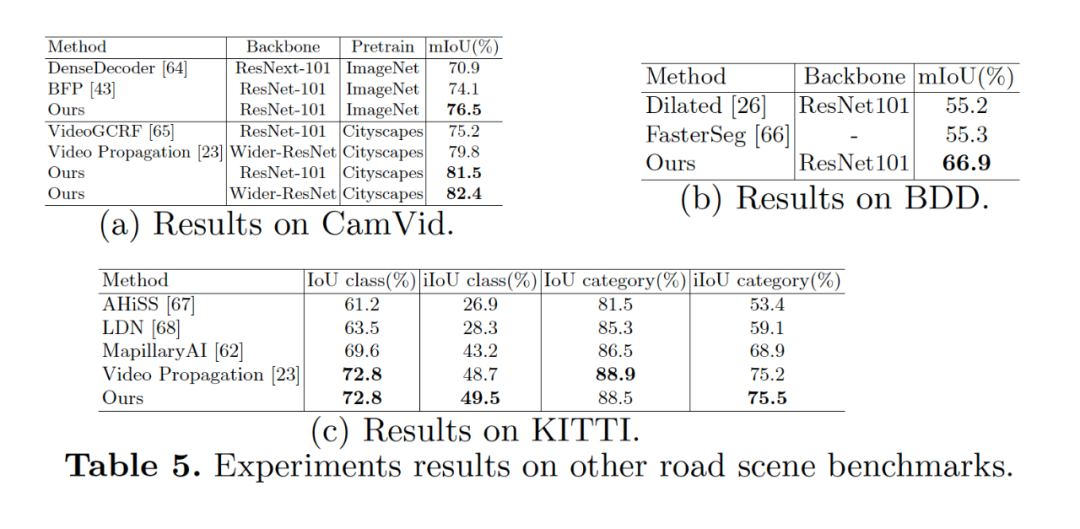
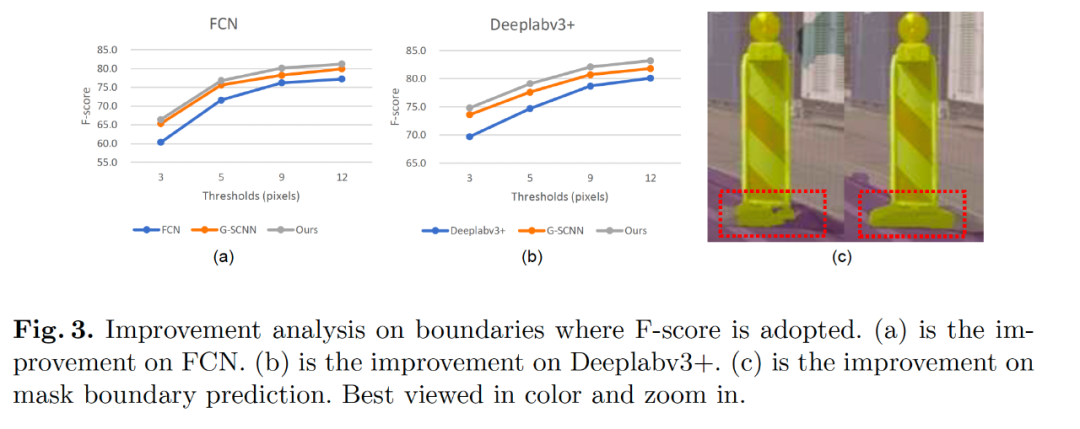
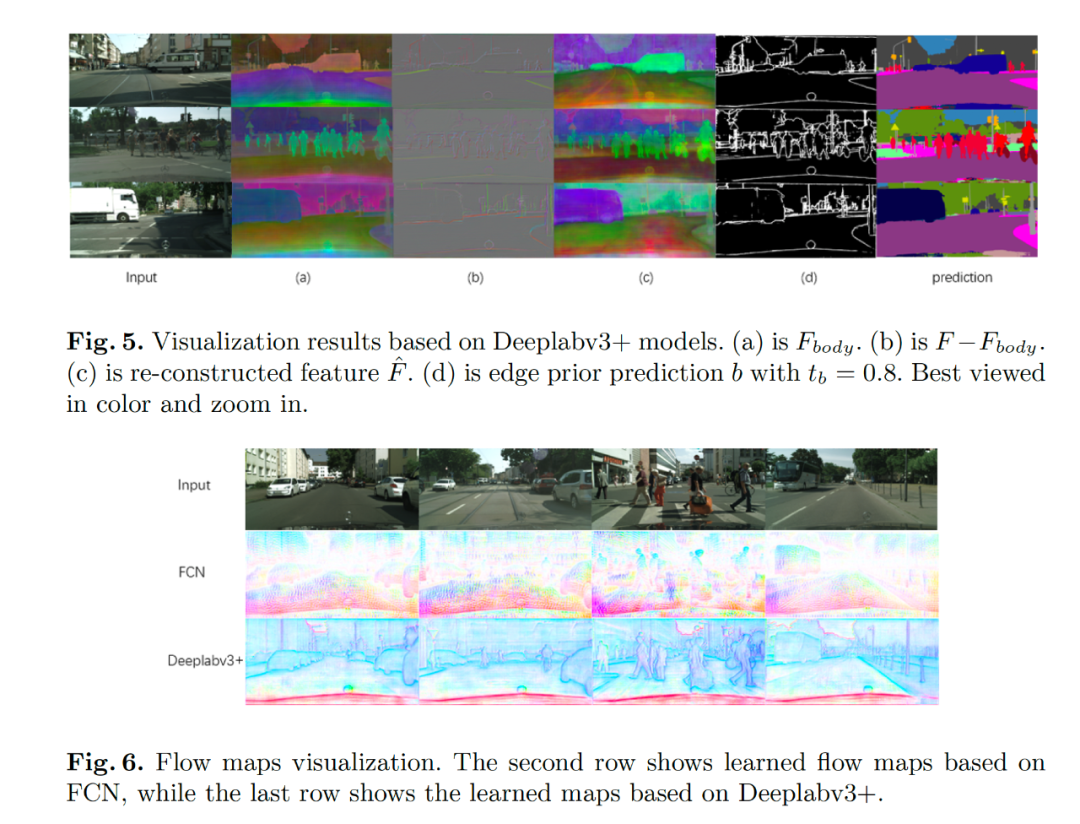
Fig3 中展示了我们分割结果的在边缘的评测指标中也比之前最好的 G-SCNN 的结果要好。Fig5 展示了我们学习到解耦的特征表示,Fig6 给出了学习到的流场的可视化图像,其中可以看到对于 FCN 的结构,流场是指向物体的内部,对于目前的 state-of-the-art 的 deeplabv3+ 模型,流场是均匀地分布在边缘点上,原因是大部分内部区域 deeplabv3+ 已经很一致了。
结论
在这项研究中,我们提出一个新颖的语义分割框架。我们通过把语义分割的特征进行解耦操作,进而让每个部分单独由不同的监督信号进行监督,因此我们实现同时提升分割物体的内部一致性和边缘部分。并且我们的模块十分轻量级,可以做到即插即用,可以用于优化任何基于 FCN 的语义分割模型。我们的方法在 4 个主流的道路场景的语义分割数据集上面取得领先的效果。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

评论