
YOLOv5超详细的入门级教程(训练篇)——训练自己的数据集

作者 | Vanessa Ni
来源 | https://blog.csdn.net/weixin_44145782/article/details/113983421
编辑 | 极市平台
极市导读
很多同学在后台询问yolo系列的资料,正好看到一篇文章不错,便决定从最简单的流程入手,一步一步来介绍模型是怎样训练出来的,并且如何达到满意的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
数据集标注
选择了一个检测鱼类的数据集,想要尝试自己去制作一个数据集。选择了60张鱼类的图片,准备标注数据:
由于自身强迫症,看着这些文件名太难受了,改成了VOC格式的 000005.jpg命名方式,但是从000000.jpg开始,共60张。

换名代码如下,将path更改为你的图片存放路径。
import os
path = "C:/Users/Desktop/fish"
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0 #从零开始
for file in filelist:
print(file)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype=os.path.splitext(file)[1] #文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir)#重命名
count+=1
利用 精灵标注助手进行标注。新建一个位置标注项目,然后开始标注就好了(深海恐惧的我为什么要标这个东西,服气。。)
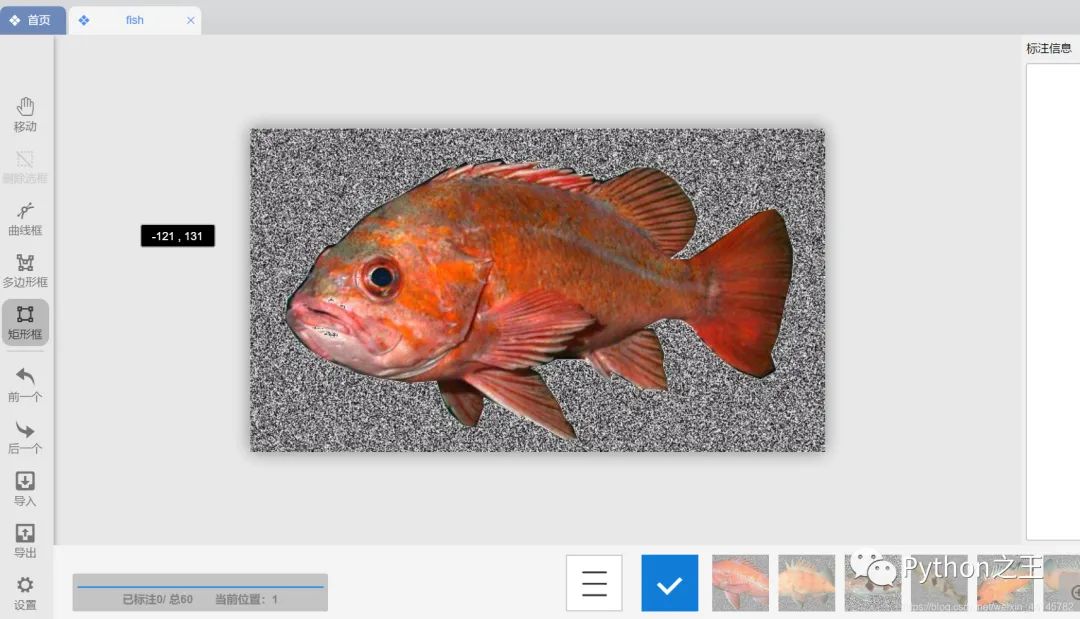
这里只建了一个分类,fish,从最简单的做起,先能识别鱼,再去做识别鱼的类别吧~~ 标完了,眼睛快瞎了,仿佛在玩找不同。导出成xml格式的文件存起来就可以了。(题主又导出了一份pascal-voc格式的xml文件~但是这个格式精灵标注助手不支持查看,所以就先导出了一份xml格式的)

pascal-voc格式的xml文件样例如下:
<?xml version="1.0" ?>
<annotation>
<folder>fish</folder>
<filename>000052.JPG</filename>
<path>C:\Users\Vanessa Ni\Desktop\fish\000052.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1024</width>
<height>768</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>fish</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>498</xmin>
<ymin>227</ymin>
<xmax>696</xmax>
<ymax>350</ymax>
</bndbox>
</object>
<object>
<name>fish</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>225</xmin>
<ymin>602</ymin>
<xmax>336</xmax>
<ymax>749</ymax>
</bndbox>
</object>
</annotation>
到此为止,数据集标注的工作就完成。我们现在手头有:
原始数据集的jpg图片- 图片标注对应的xml文件- 图片标注对应的pascal-voc格式的xml文件
数据集制作
在 yolov5/data文件下创建如下文件目录
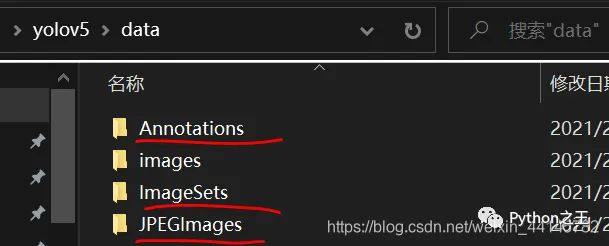
将所有的图片放到 JPEGImages文件夹下,将所有个pascal-voc格式的xml文件放入到Annotations文件夹下 - 在根目录下创建make_txt.py文件,代码如下,运行代码后ImageSets中生成数据集分类txt文件。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行以上代码,可以得到的结果是,在ImageSets中有我们的数据集分类:
根目录下继续创建 voc_label.py文件,代码如下:需要注意的是,sets中改为你的sets的名字(make_txt生成的) classes修改为你需要检测的类别,在本案例中,我们只需要检测fish一种类别。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['fish']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行以上代码后,可以发现生成了voc格式的标签文件labels(显示数据集的具体标注数据),并且在data文件下出现了train、val、test的txt文件,保存了图片的路径。(带有图片的路径)
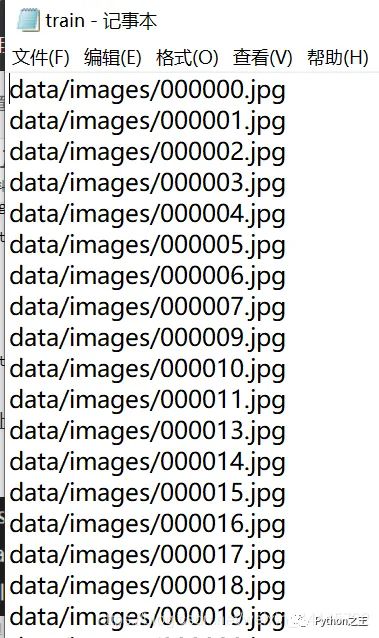
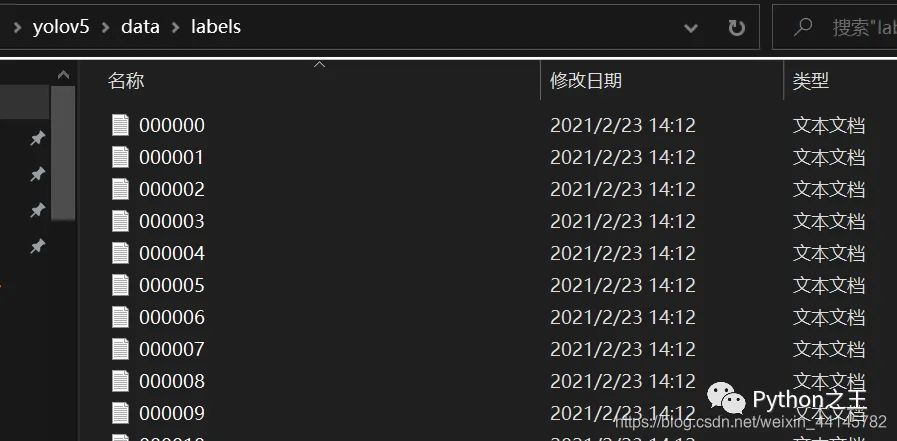

至此,我们的数据集就全部做完啦!!!~~
修改配置文件
修改coco.yaml文件
这里的yaml和以往的cfg文件是差不多的,但需要配置一份属于自己数据集的yaml文件。复制data目录下的coco.yaml,我这里命名为fish.yaml 主要修改三个地方:
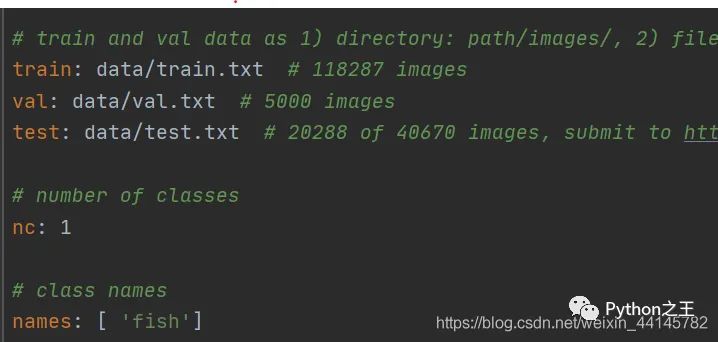
a. 修改train,val,test的路径为自己**刚刚生成的路径
b. nc 里的数字代表数据集的类别,我这里只有鱼一类,所以修改为1
c. names 里为自己数据集标注的类名称,我这里是’fish’
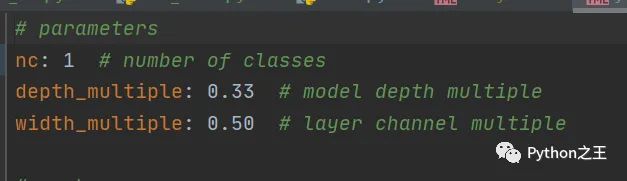
修改model.yaml文件
models下有四个模型,smlx需要训练的时间依次增加,按照需求选择一个文件进行修改即可。
这里修改了yolov5s.yaml,只需要将nc的类别修改为自己需要的即可
训练train.py
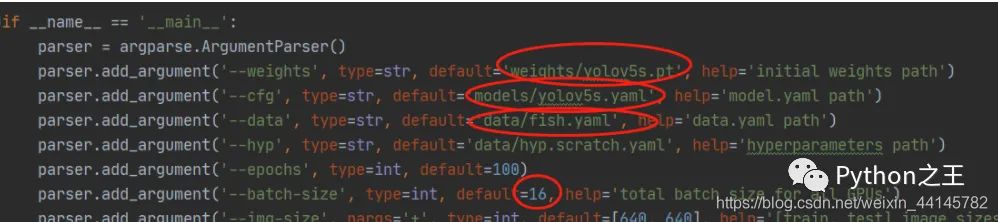
weights,yaml,data按照自己所需文件的路径修改即可 epochs迭代次数自己决定,我这里仅用100次进行测试 batch-size过高可能会影响电脑运行速度,还是要根据自己电脑硬件条件决定增加还是减少 修改完成,运行即可!python train.py 在训练过程的可视化tensorboard tensorboard --logdir runs/train 然后打开localhost:6006即可,效果如下:
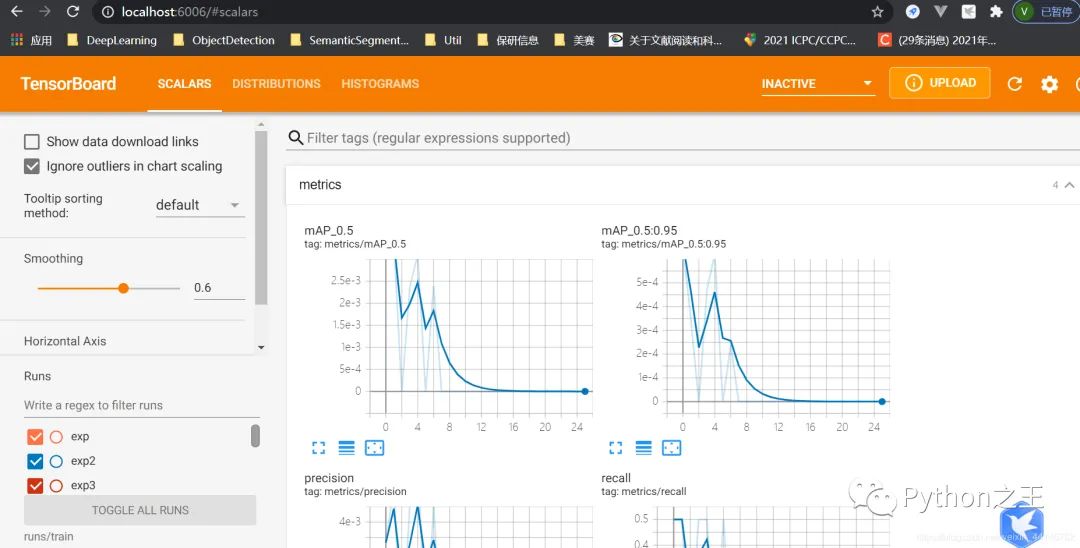
此次训练用了半个小时多一点,数据量比较小所以笔记本的垃圾显卡跑起来也还行。

yolov5就是很不错,调用了很多工具库来进行可视化!!所以最近几年的论文和代码应该都会有很多新的工具能用,等待着我们去探索~以下是训练完成后所有模型自动保存的数据:
可以看到我们的权重文件就在这里安安静静的躺着:
出现的问题
跑起来了也没有报错,但是一直卡在这个界面,显示完了超参数也不进入训练状态,打开tensorboard显示没有训练数据。
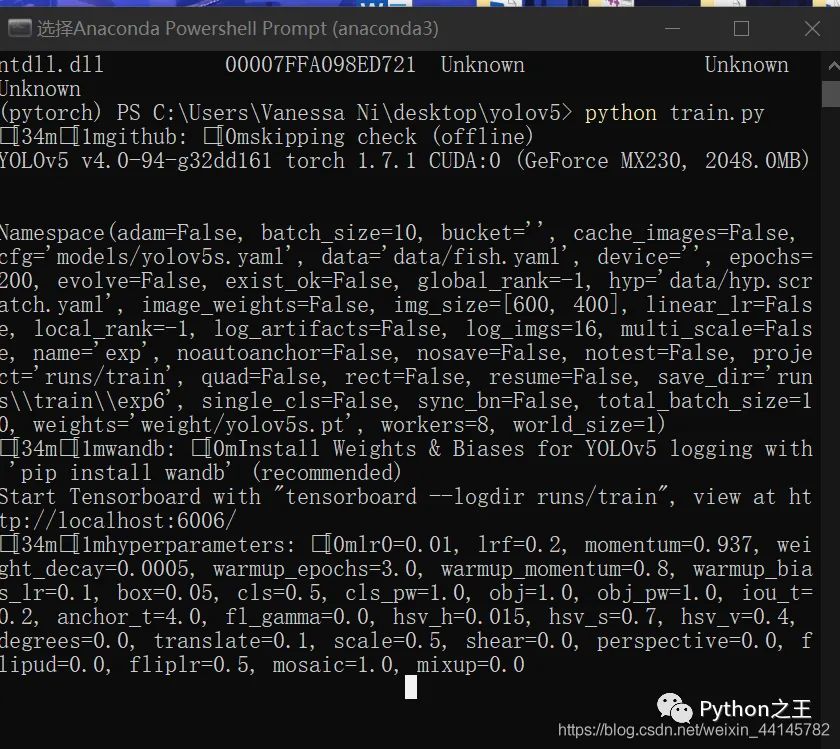
batch_size设小一点,input设置小一点:- 我刚开始取得batch_size是16(没错我的笔记本就是如此的垃圾)- inputsize取得6000X2000(因为之前想要完成的任务是要做焊缝识别的,图片数据的分辨率比较特殊,暴力的修改了inputsize然后忘记修改了) 最终导致了直接卡死~所以说深度学习真的很依赖于硬件配置哦。
train.py中的一个路径名写错了
weights\yolov5s.pt写成了weight\yolov5s.pt可以说是非常容易犯的错误,但是报错很清晰也很容易修改~要注重细节。刚开始进入训练时好像也报了一些错,可能是某些工具库我没有安装,或者其他的一些warning,我会再利用远程服务器进行训练的文章中再分析一下。
测试detect.py
python detect.py --weights runs/train/exp9/weights/best.pt --source data/Samples/ --device 0 --save-txt

结果如下:

???他在测什么????居然把岩石都当成鱼了。。。。。可能跟我选取得数据有关系。所以说数据集是非常非常影响最终模型的性能的
我们换一个比较简单的sample来继续试一试。

有些图片我标注出了很多个模糊的鱼,现在他测出来的结果可以说是非常不准确了。

这个数据集里还有很多这样的椒盐背景的单物体图片,只不过所占的比例非常小,但是在我选取数据集的时候,我选用了非常多的这个类型的图片,由于数据集的数量较少,非常影响最终的结果。
结论
我是非常相信YOLOv5模型的性能的,训练方法和数据集都会在很大的程度上影响最终模型的性能。我参考的博主做的训练最终结果是非常可观的。所以在接下来的优化中,我会进行以下操作:
制作/寻找更完善的数据集:数据集的制作是非常重要的!!!!主要关注以下几点:
数据集的数量:图片的多少
数据集的质量:选用什么样的数据来更好的完成任务。在原始的数据集中,(鱼类数据集)可以看到有不同类别的图片,其中还参杂了一些岩石的图片来喂给模型以区别出鱼类和岩石的区别,(尤其是在自然场景下,有的鱼很容易和岩石、背景融为一体,难以分辨)
数据增强操作:对于图像的预处理,利用opencv对于图像做一些基本的数据增强操作,来扩充数据集的数量,提升质量,都是很关键的步骤。
(我这里用的数据集数目很少,质量也很差劲,所以效果不好是明摆的事情)
对于深度学习来说,数据集就像是我们平时所做软件的代码一样关键,(从一篇paper上看到的)!!!!!!利用更好的硬件来进行模型的训练:在训练参数的设置过程中,受限于电脑配置的影响,我将batchsize调成了1,并且输入图片的大小也和训练图片有所出入(输入图片的大小是解决问题的关键!!尤其是对于焊缝项目,归根结底还是数据集怎么制作,怎么去处理这些数据)
在接下来的教程中我将利用实验室的服务器进行数据训练。
训练的方法:超参数的设定也是一门学问。极大的影响模型的性能。
在完成以上三点改进之后,我才会继续专注于:
模型的改进:网络结构的改进、优化算法的选择、损失函数的选择等等。
本次的教程就到此为止啦~虽然最终训练的模型性能不是很好,但是毕竟也是人生中的第二个模型(第一个模型是lenet-5 helloworld级别的训练!)
BUT!!!
性能不好意味着改进的可能,意味着能够看到更多影响模型的重要因素!!!
我认为这比一帆风顺的训练结果蕴含了更多的价值。
参考
参考了以下博主的博客,如有问题私信联系我,我会更改或撤除引用的部分。
YOLOV5训练自己的数据集(踩坑经验之谈)(https://blog.csdn.net/a_cheng_/article/details/111401500) 这篇强推,本篇文章也是基于这篇文章进行补充的,看了很多经验贴,只有这篇最清晰(可能由于时间的推进吧,手里拿着YOLOv5的代码去看YOLOv3的经验贴,不晕才怪) 使用SSH命令行传输文件到远程服务器向远程服务器传输文件(https://www.cnblogs.com/magicc/p/6490566.html) 训练中突然停止,也不报错,就一直停在那里(https://github.com/bubbliiiing/yolov4-pytorch/issues/49)
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
