
《YOLOv5全面解析教程》二,YOLOv5数据集结构解析&如何制作一个可以获得更好训练效果的数据集
前言
🎉代码仓库地址:https://github.com/Oneflow-Inc/one-yolov5欢迎star one-yolov5项目 获取 最新的动态。 如果您有问题,欢迎在仓库给我们提出宝贵的意见。🌟🌟🌟 如果对您有帮助,欢迎来给我Star呀😊~ 本系列教程原文点击 https://start.oneflow.org/oneflow-yolo-doc 可达(保持动态更新教程和源码解读和修复一些bug)。
本文主要介绍 one-yolov5 使用的数据集的格式以及如何制作一个可以获得更好训练效果的数据集。本节教程好的数据集标准部分翻译了 ultralytics/yolov5 wiki 中对数据集相关的描述(https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results) 。
数据集结构解读
1.创建dataset.yaml
COCO128是官方给的一个小的数据集 由COCO(https://cocodataset.org/#home) 数据集前 128 张图片组成。这128幅图像用于训练和验证,判断 yolov5 脚本是否能够过正常进行。数据集配置文件 coco128.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/master/data/coco128.yaml) 定义了如下的配置选项:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── one-yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
# 训练和验证图像的路径相同
train: ../coco128/images/train2017/
val: ../coco128/images/train2017/
# number of classes
nc: 80 # 类别数
# class names 类名列表
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# Download script/URL (optional) 用于自动下载的可选下载命令/URL 。
download: https://ultralytics.com/assets/coco128.zip
注意:如果是自定义数据集的话按自己需求修改这个yaml文件。主要修改以下两点。
修改训练和验证图像的路径为自定义数据集路径 修改类别数和类名列表
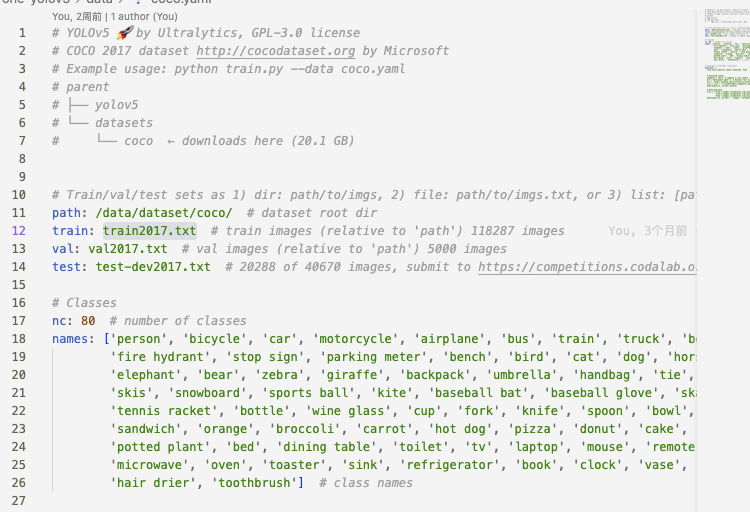
再展示一下 coco.yaml 的数据集路径配置,这里的训练和验证图像的路径就是直接用txt表示:
2.创建 Labels
使用工具例如 CVAT(https://github.com/opencv/cvat) , makesense.ai(https://www.makesense.ai/``), Labelbox(https://labelbox.com/``) ,LabelImg(在下一节制作数据集中介绍LabelImg工具使用) 等,在你自己的数据集提供的图片上做目标框的标注,将标注信息导出为一个txt后缀结尾的文件。(如果图像中没有目标,则不需要*.txt文件)。
*.txt文件规范如下所示:
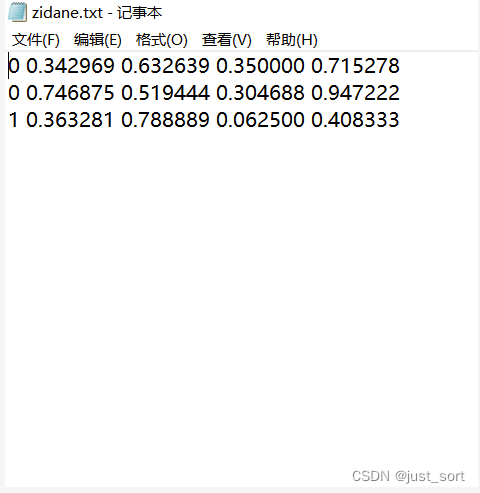
每一行 一个目标。 每一行是 class x_center y_center width height 格式。 框坐标必须采用标准化xywh格式(从0到1)。如果框以像素为单位,则将x_center和width除以图像宽度,将y_centre和height除以图像高度。 类号为零索引的编号(从0开始计数)。

这里假设以 COCO 数据集的目标类别约定来标注
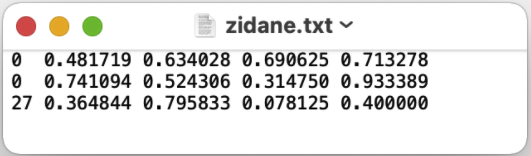
与上述图像相对应的标签文件包含2个人(class 0)和 一个领带(class 27):
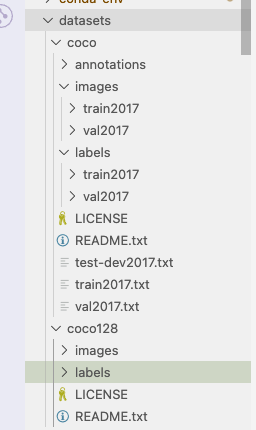
3.COCO128 数据集目录结构组织
在本例中,我们的 coco128 是位于 yolov5 目录附近。yolov5 通过将每个图像路径 xx/images/xx.jpg 替换为 xx/labels/xx.txt 来自动定位每个图像的标签。例如:
dataset/images/im0.jpg # image
dataset/labels/im0.txt # label
制作数据集
数据集标注工具
这里主要介绍 LabelImg: 是一种矩形标注工具,常用于目标识别和目标检测,可直接生成 yolov5 读取的txt标签格式,但其只能进行矩形框标注。(当然也可以选用其它的工具进行标注并且网上都有大量关于标注工具的教程。)
首先labelimg的安装十分简单,直接使用cmd中的pip进行安装,在cmd中输入命令行:
pip install labelimg
安装后直接输入命令:
labelimg
即可打开运行。
点击Open Dir选择数据集文件夹,再点击Create RectBox进行标注。
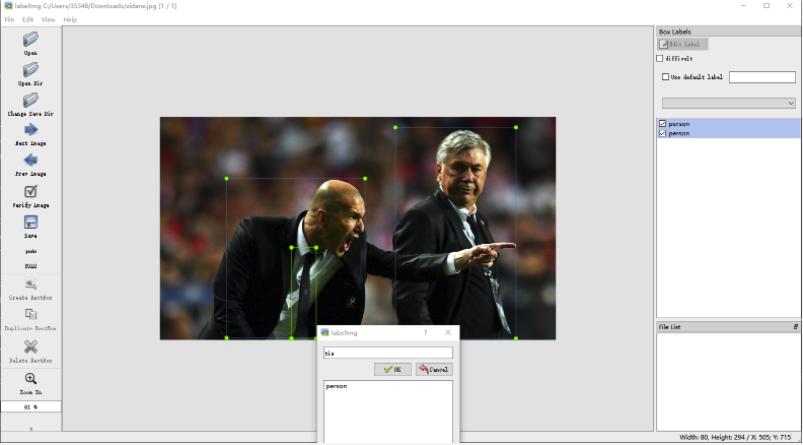
当你绘制框结束就会弹出标签选择框,然后标注类别。这个类别编辑更改在Labelimg文件里,里面有classes.txt文档,打开手动更改类别即可。(当出现新类别时也可在标签选择框里输入点OK就自动添加类别了)
标注好后选择 yolo 格式,点击 Save 保存。标注结果保存在图片名.txt文件中,txt文件和图片名称一致,内容如下:
一个好的数据集标准?
每个类的图像。>= 1500 张图片。 每个类的实例。≥ 建议每个类10000个实例(标记对象) 图片形象多样。必须代表已部署的环境。对于现实世界的使用案例,我们推荐来自一天中不同时间、不同季节、不同天气、不同照明、不同角度、不同来源(在线采集、本地采集、不同摄像机)等的图像。 标签一致性。必须标记所有图像中所有类的所有实例。部分标记将不起作用。 标签准确性。 标签必须紧密地包围每个对象。对象与其边界框之间不应存在任何空间。任何对象都不应缺少标签。 标签验证。查看train_batch*.jpg 在 训练开始验证标签是否正确,即参见 mosaic (在 yolov5 的训练日志 runs/train/exp* 文件夹里面可以看到)。 背景图像。背景图像是没有添加到数据集以减少 False Positives(FP)的对象的图像。我们建议使用大约0-10%的背景图像来帮助减少FPs(COCO有1000个背景图像供参考,占总数的1%)。背景图像不需要标签。
下图展示了多种数据集的标签特点:
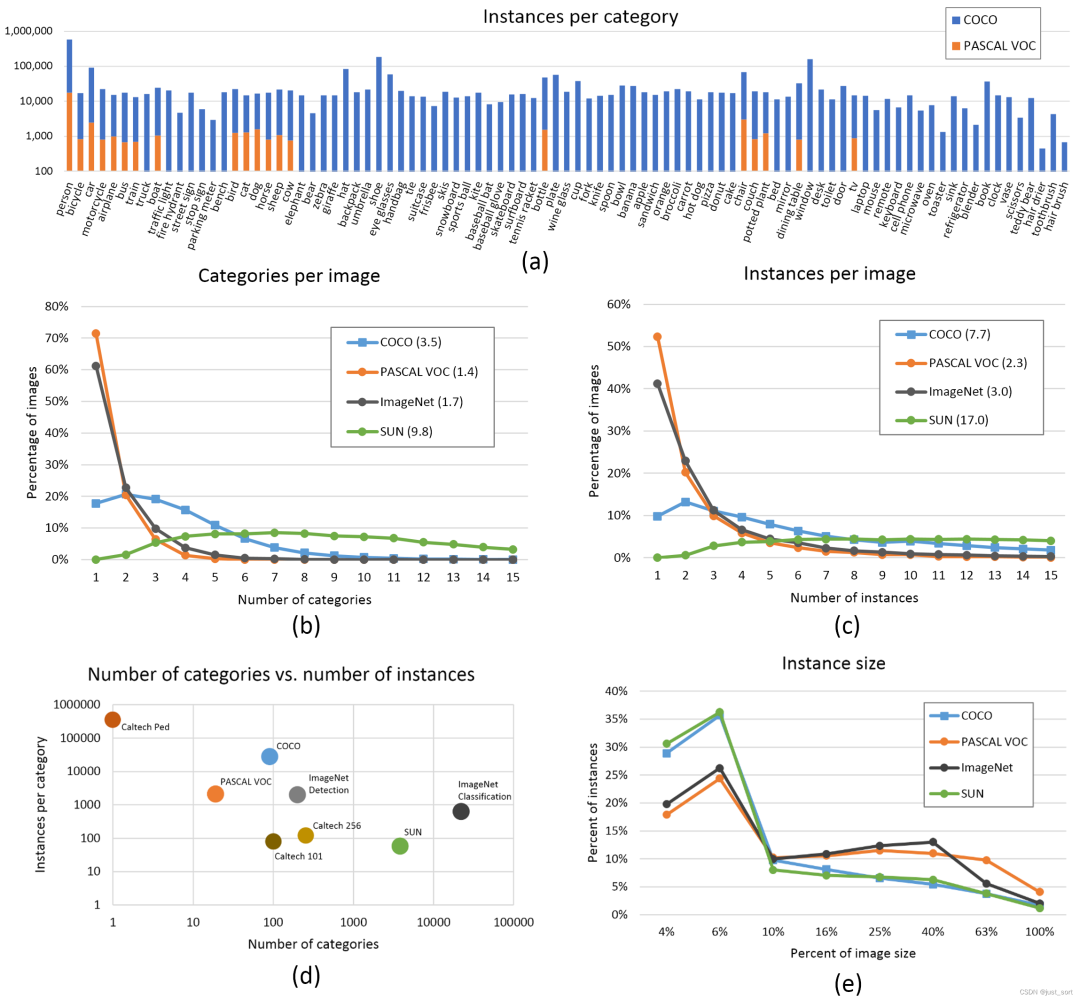
其中:
Instances per category 表示每个类别的实例数 Categories per image 表示每幅图像的类别 (a) Instances per image 表示每幅图像的实例数 (b) Number of categories vs. number of instances 表示类别数目 vs 实例数目 (我们可以看到 COCO 数据集的类别和实例的数目达到了一个较好的平衡) (c) Instance size 表示实例个数 (d) Number of categories 表示类别数 (e) Percent of image size 表示图像大小百分比
参考文章
https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results https://docs.ultralytics.com/tutorials/train-custom-datasets/#weights-biases-logging-new