
yolox-keras的源码,超越YOLOv5,可以用于训练自己的模型

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
YOLOX的一个创新点在于, 基于YOLOv3的整体架构, 将Head进行了decouple:
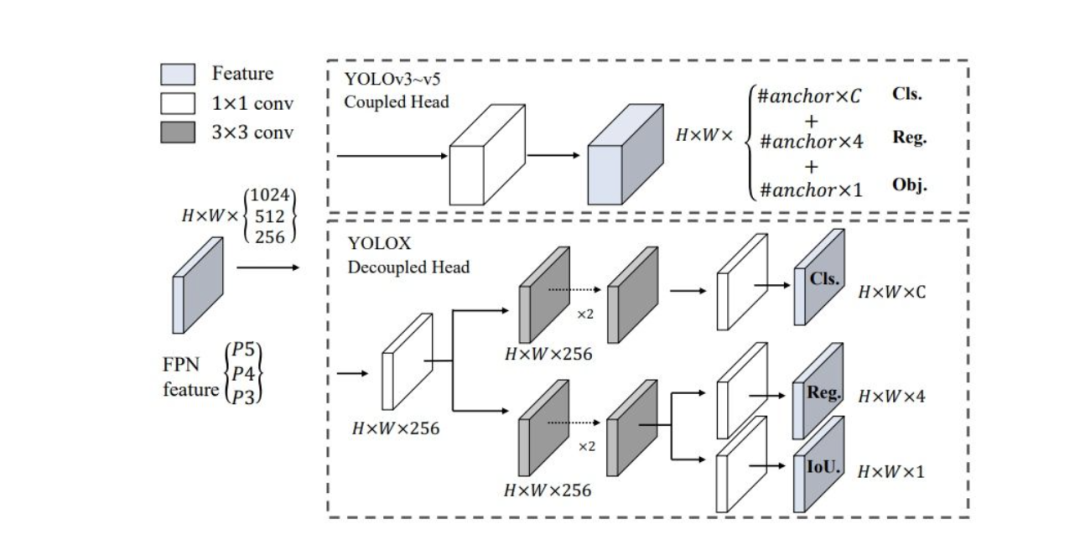
可以看到,现在的Cls, Reg, IoU分支被进行了解耦和, 并且将这些输出分别用对应的维度来进行回归. 这和YOLOv3中的处理方式, 输出直接用一个5维度的向量来堆叠不同, 这种去耦合方式能够更好的让网络学习到类别和对应的坐标回归.
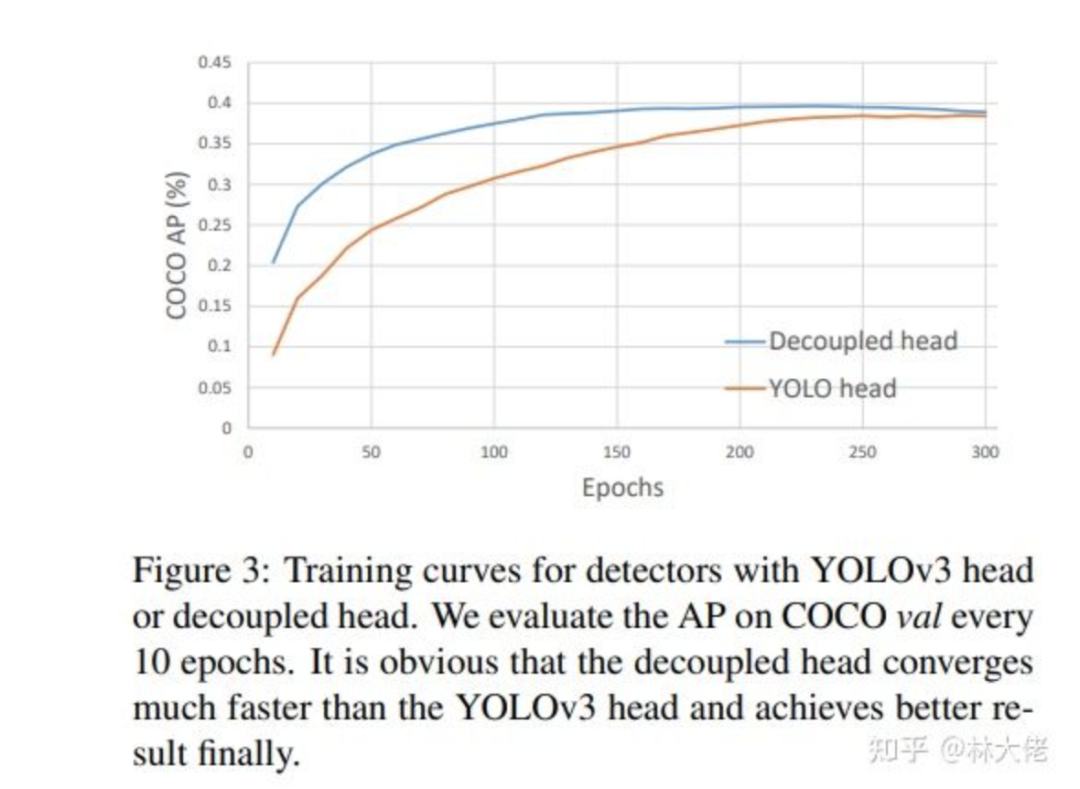
实验结果表情, Decouple的方式能够更快的加速收敛, 尽管他们能达到的上限差不多, 但是收敛速度被大大的加快.
除了decouple以外, 还增加了诸如, 数据增强, AnchorFree, MultiPositives, SimOTA等新的trick, 结果就是AP直接增加了3个点.
相比于原版本的YOLOv3更是直接增加了9个点.
结果更是直接超越了Yolov5的性能. 以增加1ms的计算量为代价. 不过整体的速度依旧很低.
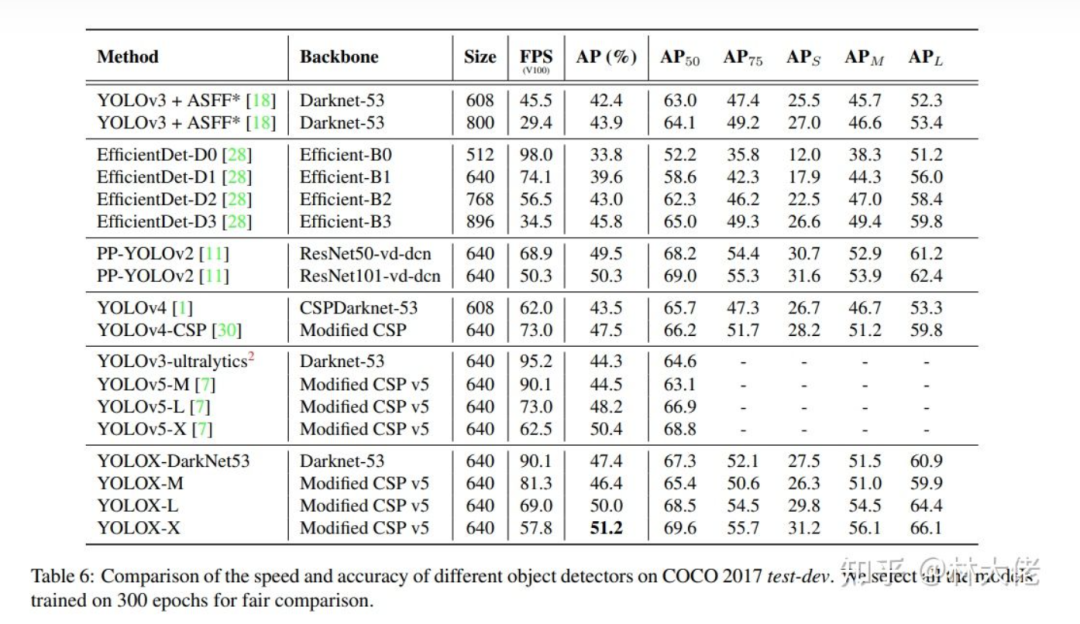

性能情况
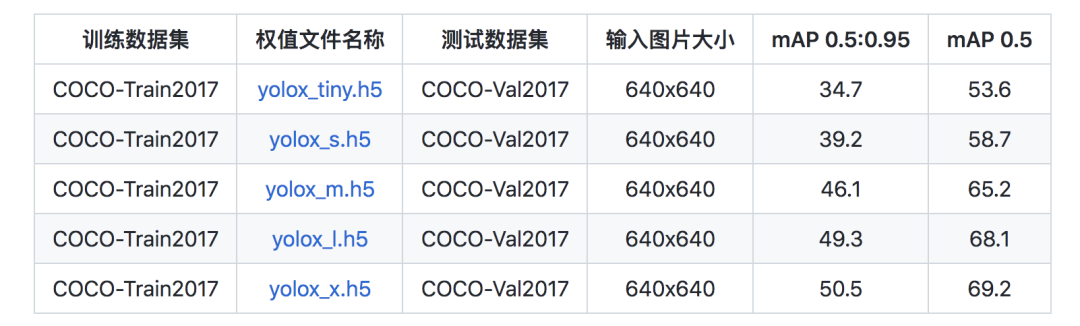
代码 获取方式:
关注微信公众号 datayx 然后回复 yolox 即可获取。
实现的内容
主干特征提取网络:使用了Focus网络结构。
分类回归层:Decoupled Head,在YoloX中,Yolo Head被分为了分类回归两部分,最后预测的时候才整合在一起。
训练用到的小技巧:Mosaic数据增强、CIOU(原版是IOU和GIOU,CIOU效果类似,都是IOU系列的,甚至更新一些)、学习率余弦退火衰减。
Anchor Free:不使用先验框
SimOTA:为不同大小的目标动态匹配正样本。
所需环境
tensorflow-gpu==1.13.1
keras==2.1.5
小技巧的设置
在train.py文件下:
1、mosaic参数可用于控制是否实现Mosaic数据增强。
2、Cosine_scheduler可用于控制是否使用学习率余弦退火衰减。
3、label_smoothing可用于控制是否Label Smoothing平滑。
文件下载
训练所需的权值可在百度网盘中下载。
链接: https://pan.baidu.com/s/18vaa1ehQuS4vN6xRc2Qidg
提取码: 28mx
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:
链接: https://pan.baidu.com/s/1YuBbBKxm2FGgTU5OfaeC5A
提取码: uack
训练步骤
a、训练VOC07+12数据集
数据集的准备
本文使用VOC格式进行训练,训练前需要下载好VOC07+12的数据集,解压后放在根目录数据集的处理
修改voc_annotation.py里面的annotation_mode=2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt。开始网络训练
train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练。训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。我们首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
b、训练自己的数据集
数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集,
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
model_data/cls_classes.txt文件内容为:
cat
dog
...
修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。
开始网络训练
训练的参数较多,均在train.py中,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的classes_path。
classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样!训练自己的数据集必须要修改!
修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。在yolo.py里面修改model_path以及classes_path。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
预测步骤
a、使用预训练权重
下载完库后解压,在百度网盘下载yolo_weights.pth,放入model_data,运行predict.py,输入
img/street.jpg在predict.py里面进行设置可以进行fps测试和video视频检测。
b、使用自己训练的权重
按照训练步骤训练。
在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。

运行predict.py,输入
img/street.jpg在predict.py里面进行设置可以进行fps测试和video视频检测。
评估步骤
a、评估VOC07+12的测试集
本文使用VOC格式进行评估。VOC07+12已经划分好了测试集,无需利用voc_annotation.py生成ImageSets文件夹下的txt。
在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
b、评估自己的数据集
本文使用VOC格式进行评估。
如果在训练前已经运行过voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。
利用voc_annotation.py划分测试集后,前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。
在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx