
YOLOv5超详细的入门级教程(思考篇)(一)——关于遮挡问题与小目标检测问题
一些拙见,欢迎大家在评论区指出问题,交流讨论。
1. Introduction

还是这张老图,16年到18年CVPR和ICCV的高频词词云。从2012年进入深度学习时代开始,目标检测、图像分割这样的视觉基本任务到现在已经火了有10年已久了(如果算上传统图像处理的方法,那么目标检测到现在已经被集中攻克22年了)。
最新出炉的18篇CVPR2021oral,里面值得注意的一点就是3D目标检测的研究。比如3D场景理解、3D中摄像机重定位、3D分割与运动估计、单目3D目标检测、3D点云注册和检测、3D物体渲染…(18篇里好几篇都是新颖的3D目标检测任务),可以看出来2D大家已经研究腻了(或者说是放弃了),其中一个新的方向就是,开始集中火力攻克3D目标检测的问题。目前我也有研究一些关于3D点云目标检测的内容,可以参考我的其他博客。
BUT!!!这18篇新的CVPR2021oral里面,有这样一篇,开放世界中的目标检测。该模型的任务是:1)在没有明确监督的情况下,将尚未引入该对象的对象识别为“未知”,以及2)当逐渐接收到相应的标签时,逐步学习这些已识别的未知类别,而不会忘记先前学习的类别。简单来说,识别现实世界中的所有物体,并且能够逐渐学习认知新的未知物体。我的理解就是,可以识别更多的物体,接收标签来学习对象的类别,降低训练成本。
那么2D目标检测的一些瓶颈究竟在哪,以下是我目前能总结出来的点。
识别更多的物体。早在YOLO9000这篇论文里,作者就提出了利用词树的方法来实现能够识别更广泛类别物体的目标检测。- 遮挡问题。我认为MSCOCO数据集识别准确率难以上升的一个关键性要素就是大量的遮挡。- 小目标检测问题。- …待补充
接下来我将简单介绍一下关于遮挡和小目标检测问题的相关内容。
2. 遮挡问题
在YOLOv5中,引入了许多方法,在nms阶段进行遮挡问题的处理。我觉得这个出发点很高效,毕竟在模型设计和训练阶段去解决遮挡问题需要研究非常多的内容,还不一定能解决问题。但是在利用更好的非极大值抑制算法时,能够大大提升遮挡物体的查全率。
最初我在利用YOLOv5进行NEU-DET实验时,就发现最终结果总是有重复检测的部分。所以如何解决遮挡问题(保留更多的框)的同时,减少重复检测(保留更少的框),也是我认为nms优化算法的一个值得研究的点。
Yolov4在CIOU_Loss的基础上采用DIOU_nms的方式,可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。 在YOLOv5中使用DIOU_loss,对于一些遮挡重叠的目标,确实会有一些改进。
在YOLOv5中使用DIOU_loss,对于一些遮挡重叠的目标,确实会有一些改进。
3. 小目标检测
另外一个让人痛心的问题就是小目标检测。不训不知道,一训吓一跳,利用yolov3训练出的模型识别小物体的效果真的是太太太太差劲了。
目标检测发展很快,但对于小目标的检测还是有一定的瓶颈,特别是大分辨率图像小目标检测。比如7920 * 2160,甚至16000 * 16000的图像。
这么看来,博主的任务还不是非常困难。背景是这样的:船厂给的6000 *2000 分辨率的x光胶片,焊缝在图片的正中间,所占的空间位置已经很小了。但是我们要识别的是缺陷啊喂!!!缺陷可太小了,博主拿肉眼识别都极其困难(心疼船厂的工人几秒)!首先先数据增强一下,增大一下前景背景的对比度,不然眼睛就要瞎掉了。其次,缺陷的形状也是五花八门。所以上升到识别缺陷的形状这种任务,还是分割来做比较合适。
 像上图这种遥感图像识别的简直是炼狱级的吧。
像上图这种遥感图像识别的简直是炼狱级的吧。
那么是什么因素使得小目标检测如此困难的呢?
小目标尺寸。以网络的输入608608为例,yolov3、yolov4,yolov5中下采样都使用了5次,因此最后的特征图大小是1919,3838,7676。三个特征图中,最大的7676负责检测小目标,而对应到608**608上,每格特征图的感受野是608/76=88大小。再将608608对应到76802160上,以最长边7680为例,7680/608**8=101。即如果原始图像中目标的宽或高小于101像素,网络很难学习到目标的特征信息。(PS:这里忽略多尺度训练的因素及增加网络检测分支的情况) - 高分辨率。在很多遥感图像中,长宽比的分辨率比76802160更大,比如上面的1600016000,如果采用直接输入原图的方式,很多小目标都无法检测出。- 显卡爆炸。很多图像分辨率很大,如果简单的进行下采样,下采样的倍数太大,容易丢失数据信息。但是倍数太小,网络前向传播需要在内存中保存大量的特征图,极大耗尽GPU资源,很容易发生显存爆炸,无法正常的训练及推理。如何解决呢?
我的一个思路就是把图像做分割,一张张送进去识别呗,数据集还变大了。果不其然,别人也这么想的,并且都做出来了。
2018年YOLT算法,改变一下思维,对大分辨率图片先进行分割,变成一张张小图,再进行检测。
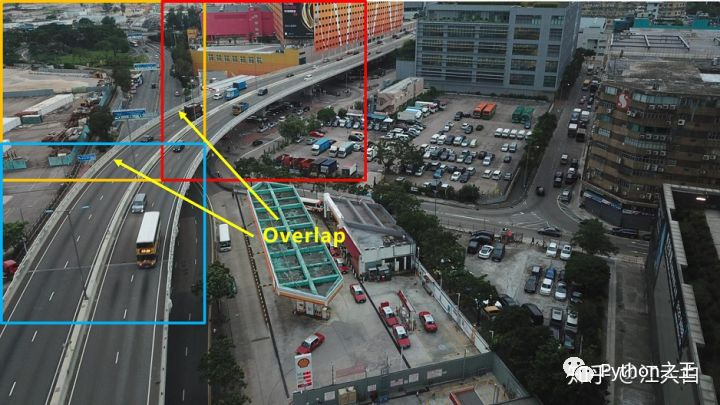
为了避免两张小图之间,一些目标正好被分割截断,所以两个小图之间设置overlap重叠区域,比如分割的小图是960960像素大小,则overlap可以设置为96020%=192像素。
每个小图检测完成后,再将所有的框放到大图上,对大图整体做一次nms操作,将重叠区域的很多重复框去除。(按照在大图上裁剪的位置,直接回归到大图即可。)
 坏处就是增加了计算量,我们选用更轻的网络来balance一下吧~
坏处就是增加了计算量,我们选用更轻的网络来balance一下吧~
References
目标检测一卷到底之后,终于有人为它挖了个新坑|CVPR2021 Oral 1. 一文概览 CVPR2021 最新18篇 Oral 论文 1. You only look twice.


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!