
基于 OpenCV 的图像分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本期我们将一起来实现一个有趣的问题 -图像分割的算法。
本文的示例代码可以在以下链接中找到:
https://github.com/kiteco/kite-python-blog-post-code/tree/master/image-segmentation
作为我们的例子,我们将对KESM显微镜获取的图像进行分割以获取其中的血管组织。
数据科学家和医学研究人员可以将这种方法作为模板,用于更加复杂的图像的数据集(如天文数据),甚至一些非图像数据集中。由于图像在计算机中表示为矩阵,我们有一个专门的排序数据集作为基础。在整个处理过程中,我们将使用 Python 包,以及OpenCV、scikit 图像等几种工具。除此之外,我们还将使用 numpy ,以确保内存中的值一致存储。
主要内容
为了消除噪声,我们使用简单的中位数滤波器来移除异常值,但也可以使用一些不同的噪声去除方法或伪影去除方法。这项工件由采集系统决定(显微镜技术),可能需要复杂的算法来恢复丢失的数据。工件通常分为两类:
1. 模糊或焦点外区域
2. 不平衡的前景和背景(使用直方图修改正确)
分割
对于本文,我们使用Otsu 的方法分割,使用中位数滤波器平滑图像后,然后验证结果。只要分段结果是二进制的,就可以对任何分段算法使用相同的验证方法。这些算法包括但不限于考虑不同颜色空间的各种循环阈值方法。
一些示例包括:
1. 李阈值
2. 依赖于局部强度的自适应阈值方法
3. 在生物医学图像分割中常用的Unet等深度学习算法
4. 在语义上对图像进行分段的深度学习方法
验证
我们从已手动分割的基础数据集开始。为了量化分段算法的性能,我们将真实数据与预测数据的二进制分段进行比较,同时显示准确性和更有效的指标。尽管真阳性 (TP) 或假阴性 (FN) 数量较低,但精度可能异常高。在这种情况下,F1 分数和 MCC是二进制分类的更好量化指标。稍后我们将详细介绍这些指标的优缺点。
为了定性验证,我们叠加混淆矩阵结果,即真正的正极、真负数、假阳性、假负数像素正好在灰度图像上。此验证也可以应用于二进制图像分割结果上的颜色图像,尽管本文中使用的数据是灰度图像。最后,我们将介绍整个实现过程。现在,让我们看看数据和用于处理这些数据的工具。
Loading and visualizing data
我们将使用以下模块加载、可视化和转换数据。这些对于图像处理和计算机视觉算法非常有用,具有简单而复杂的数组数学。如果单独安装,括号中的模块名称会有所帮助。

如果在运行示例代码中,遇到 matplotlib 后端的问题,请通过删除 plt.ion() 调用来禁用交互式模式,或是通过取消注释示例代码中的建议调用来在每个部分的末尾调用 plt.show()。"Agg"或"TkAgg"将作为图像显示的后端。绘图将显示在文章中。
代码导入
import cv2import matplotlib.pyplot as pltimport numpy as npimport scipy.miscimport scipy.ndimageimport skimage.filtersimport sklearn.metrics# Turn on interactive mode. Turn off with plt.ioff()plt.ion()
在本节中,我们将加载可视化数据。数据是小老鼠脑组织与印度墨水染色的图像,由显微镜(KESM)生成。此 512 x 512 图像是一个子集,称为图块。完整的数据集为 17480 x 8026 像素,深度为 799,大小为 10gb。因此,我们将编写算法来处理大小为 512 x 512 的图块,该图块只有 150 KB。
各个图块可以映射为在多处理/多线程(即分布式基础结构)上运行,然后再缝合在一起即获得完整的分段图像。我们不介绍具体的缝合方法。简而言之,拼接涉及对整个矩阵的索引并根据该索引将图块重新组合。可以使用map-reduce进行,Map-Reduce的指标例如所有图块的所有F1分数之和等。我们只需将结果添加到列表中,然后执行统计摘要即可。
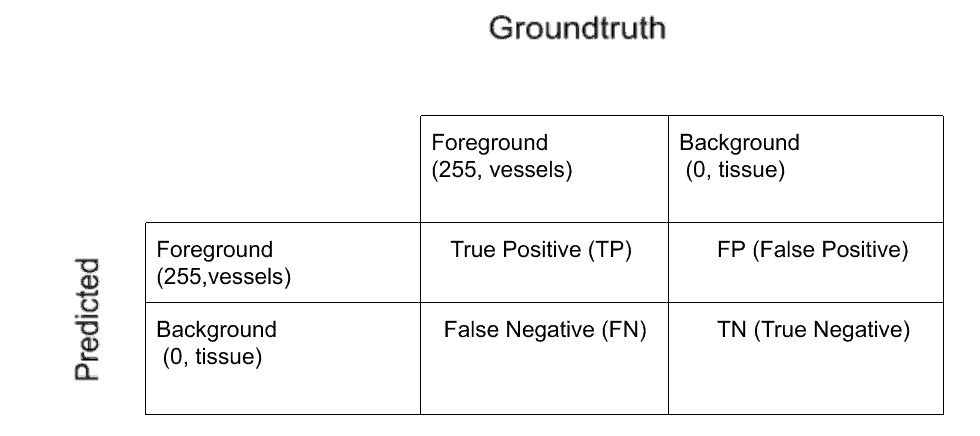
左侧的黑色椭圆形结构是血管,其余的是组织。因此,此数据集中的两个类是:
• 前景(船只)—标记为255
• 背景(组织)—标记为0
右下方的最后一个图像是真实图像。通过绘制轮廓并填充轮廓以手动方式对其进行追踪,通过病理学家获得真实情况。我们可以使用专家提供的类似示例来训练深度学习网络,并进行大规模验证。我们还可以通过将这些示例提供给其他平台并让他们以更大的比例手动跟踪一组不同的图像以进行验证和培训来扩充数据。
grayscale = scipy.misc.imread('grayscale.png')grayscale = 255 - grayscalegroundtruth = scipy.misc.imread('groundtruth.png')plt.subplot(1, 3, 1)plt.imshow(255 - grayscale, cmap='gray')plt.title('grayscale')plt.axis('off')plt.subplot(1, 3, 2)plt.imshow(grayscale, cmap='gray')plt.title('inverted grayscale')plt.axis('off')plt.subplot(1, 3, 3)plt.imshow(groundtruth, cmap='gray')plt.title('groundtruth binary')plt.axis('off')

前处理
在分割数据之前,我们应该检查一下数据集,以确定是否存在由于成像系统而造成了伪影。在此示例中,我们仅讨论一个图像。通过查看图像,我们可以看到没有任何明显的伪影会干扰分割。但是,小伙伴们可以使用中值滤镜消除离群值噪声并平滑图像。中值过滤器用中值(在给定大小的内核内)替换离群值。
内核大小3的中值过滤器
median_filtered = scipy.ndimage.median_filter(grayscale, size=3)plt.imshow(median_filtered, cmap='gray')plt.axis('off')plt.title("median filtered image")
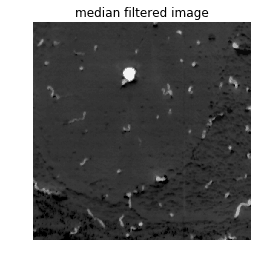
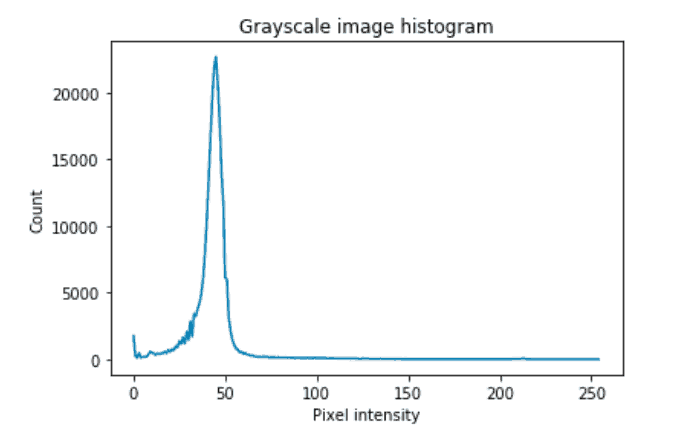
要确定哪种阈值技术最适合分割,我们可以先通过阈值确定是否存在将这两个类别分开的独特像素强度。在这种情况下,可以使用通过目视检查获得的强度对图像进行二值化处理。我们使用的图像许多像素的强度小于50,这些像素与反转灰度图像中的背景类别相对应。
尽管类别的分布不是双峰的,但仍然在前景和背景之间有所区别,在该区域中,较低强度的像素达到峰值,然后到达谷底。可以通过各种阈值技术获得该精确值。分割部分将详细研究一种这样的方法。
可视化像素强度的直方图
counts, vals = np.histogram(grayscale, bins=range(2 ** 8))plt.plot(range(0, (2 ** 8) - 1), counts)plt.title("Grayscale image histogram")plt.xlabel("Pixel intensity")plt.ylabel("Count")

分割
去除噪声后,我们可以用skimage滤波器模块对所有阈值的结果进行比较,来确定所需要使用的像素。有时,在图像中,其像素强度的直方图不是双峰的。因此,可能会有另一种阈值方法可以比基于阈值形状在内核形状中进行阈值化的自适应阈值方法更好。Skimage中的函数可以方便看到不同阈值的处理结果。
尝试所有阈值
result = skimage.filters.thresholding.try_all_threshold(median_filtered)
最简单的阈值处理方法是为图像使用手动设置的阈值。但是在图像上使用自动阈值方法可以比人眼更好地计算其数值,并且可以轻松复制。对于本例中的图像,似乎Otsu,Yen和Triangle方法的效果很好。
在本文中,我们将使用Otsu阈值技术将图像分割成二进制图像。Otsu通过计算一个最大化类别间方差(前景与背景之间的方差)并最小化类别内方差(前景内部的方差或背景内部的方差)的值来计算阈值。如果存在双峰直方图(具有两个不同的峰)或阈值可以更好地分隔类别,则效果很好。
Otsu阈值化和可视化
threshold = skimage.filters.threshold_otsu(median_filtered)print("Threshold value is {}".format(threshold))predicted = np.uint8(median_filtered > threshold) * 255plt.imshow(predicted, cmap='gray')plt.axis('off')plt.title("otsu predicted binary image")

如果上述简单技术不能用于图像的二进制分割,则可以使用UNet,带有FCN的ResNet或其他各种受监督的深度学习技术来分割图像。要去除由于前景噪声分段而产生的小物体,也可以考虑尝试skimage.morphology.remove_objects()。
验证方式
一般情况下,我们都需要由具有图像类型专长的人员手动生成基本事实,来验证准确性和其他指标,并查看图像的分割程度。
confusion矩阵
我们sklearn.metrics.confusion_matrix()用来获取该矩阵元素,如下所示。假设输入是带有二进制元素的元素列表,则Scikit-learn混淆矩阵函数将返回混淆矩阵的4个元素。对于一切都是一个二进制值(0)或其他(1)的极端情况,sklearn仅返回一个元素。我们包装了sklearn混淆矩阵函数,并编写了我们自己的这些边缘情况,如下所示:
get_confusion_matrix_elements()
def get_confusion_matrix_elements(groundtruth_list, predicted_list):"""returns confusion matrix elements i.e TN, FP, FN, TP as floatsSee example code for helper function definitions"""_assert_valid_lists(groundtruth_list, predicted_list)if _all_class_1_predicted_as_class_1(groundtruth_list, predicted_list) is True:tn, fp, fn, tp = 0, 0, 0, np.float64(len(groundtruth_list))elif _all_class_0_predicted_as_class_0(groundtruth_list, predicted_list) is True:tn, fp, fn, tp = np.float64(len(groundtruth_list)), 0, 0, 0else:tn, fp, fn, tp = sklearn.metrics.confusion_matrix(groundtruth_list, predicted_list).ravel()tn, fp, fn, tp = np.float64(tn), np.float64(fp), np.float64(fn), np.float64(tp)return tn, fp, fn, tp
准确性
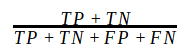
get_accuracy()
def get_accuracy(groundtruth_list, predicted_list):fp, fn, tp = get_confusion_matrix_elements(groundtruth_list, predicted_list)total = tp + fp + fn + tnaccuracy = (tp + tn) / totalreturn accuracy
它在0到1之间变化,0是最差的,1是最好的。如果算法将所有东西都检测为整个背景或前景,那么仍然会有很高的准确性。因此,我们需要一个考虑班级人数不平衡的指标。特别是由于当前图像比背景0具有更多的前景像素(类1)。
F1分数从0到1不等,计算公式为:
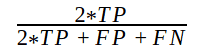
0是最差的预测,而1是最好的预测。现在,考虑边缘情况,处理F1分数计算。
get_f1_score()
def get_f1_score(groundtruth_list, predicted_list):"""Return f1 score covering edge cases"""tn, fp, fn, tp = get_confusion_matrix_elements(groundtruth_list, predicted_list)if _all_class_0_predicted_as_class_0(groundtruth_list, predicted_list) is True:f1_score = 1elif _all_class_1_predicted_as_class_1(groundtruth_list, predicted_list) is True:f1_score = 1else:f1_score = (2 * tp) / ((2 * tp) + fp + fn)return f1_score
高于0.8的F1分数被认为是良好的F1分数,表明预测表现良好。
客户中心
MCC代表马修斯相关系数,其计算公式为:
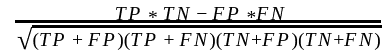
它位于-1和+1之间。-1是实际情况与预测之间绝对相反的相关性,0是随机结果,其中某些预测匹配,而+1是实际情况与预测之间绝对匹配,保持正相关。因此,我们需要更好的验证指标,例如MCC。
在MCC计算中,分子仅由四个内部单元(元素的叉积)组成,而分母由混淆矩阵的四个外部单元(点的积)组成。在分母为0的情况下,MCC将能够注意到我们的分类器方向错误,并且会通过将其设置为未定义的值(即numpy.nan)进行警告。但是,为了获得有效值,并能够在必要时对不同图像平均MCC,我们将MCC设置为-1(该范围内最差的值)。其他边缘情况包括将MCC和F1分数设置为1的所有正确检测为前景和背景的元素。否则,将MCC设置为-1且F1分数为0。
想要了解有关MCC和边缘案例,以及MCC为什么比准确性或F1分数更好,可以阅读下面这篇文章:
https://lettier.github.io/posts/2016-08-05-matthews-correlation-coefficient.html
https://en.wikipedia.org/wiki/Matthews_correlation_coefficient#Advantages_of_MCC_over_accuracy_and_F1_score
get_mcc()
def get_mcc(groundtruth_list, predicted_list):"""Return mcc covering edge cases"""tn, fp, fn, tp = get_confusion_matrix_elements(groundtruth_list, predicted_list)if _all_class_0_predicted_as_class_0(groundtruth_list, predicted_list) is True:mcc = 1elif _all_class_1_predicted_as_class_1(groundtruth_list, predicted_list) is True:mcc = 1elif _all_class_1_predicted_as_class_0(groundtruth_list, predicted_list) is True:mcc = -1elif _all_class_0_predicted_as_class_1(groundtruth_list, predicted_list) is True :mcc = -1elif _mcc_denominator_zero(tn, fp, fn, tp) is True:mcc = -1# Finally calculate MCCelse:mcc = ((tp * tn) - (fp * fn)) / (np.sqrt((tp + fp) * (tp + fn) * (tn + fp) * (tn + fn)))return mcc
最后,我们可以按结果并排比较验证指标。
> validation_metrics = get_validation_metrics(groundtruth, predicted){'mcc': 0.8533910225863214, 'f1_score': 0.8493358633776091, 'tp': 5595.0, 'fn': 1863.0, 'fp': 122.0, 'accuracy': 0.9924278259277344, 'tn': 254564.0}
精度接近1,因为示例图像中有很多背景像素可被正确检测为背景(即,真实的底片自然更高)。这说明了为什么精度不是二进制分类的好方法。
F1分数是0.84。因此,在这种情况下,我们可能不需要用于二进制分割的更复杂的阈值算法。如果堆栈中的所有图像都具有相似的直方图分布和噪声,则可以使用Otsu并获得相当不错的预测结果。
所述MCC 0.85高时,也表示地面实况和预测图像具有高的相关性,从在上一节的预测图像图片清楚地看到。
现在,让我们可视化并查看混淆矩阵元素TP,FP,FN,TN在图像周围的分布位置。它向我们显示了在不存在阈值(FP)的情况下阈值正在拾取前景(容器),在未检测到真实血管的位置(FN),反之亦然。
验证可视化
为了可视化混淆矩阵元素,我们精确地找出混淆矩阵元素在图像中的位置。例如,我们发现TP阵列(即正确检测为前景的像素)是通过找到真实情况和预测阵列的逻辑“与”。同样,我们使用逻辑布尔运算通常称为FP,FN,TN数组。
get_confusion_matrix_intersection_mats()
def get_confusion_matrix_intersection_mats(groundtruth, predicted):""" Returns dict of 4 boolean numpy arrays with True at TP, FP, FN, TN"""confusion_matrix_arrs = {}groundtruth_inverse = np.logical_not(groundtruth)predicted_inverse = np.logical_not(predicted)confusion_matrix_arrs['tp'] = np.logical_and(groundtruth, predicted)confusion_matrix_arrs['tn'] = np.logical_and(groundtruth_inverse, predicted_inverse)confusion_matrix_arrs['fp'] = np.logical_and(groundtruth_inverse, predicted)confusion_matrix_arrs['fn'] = np.logical_and(groundtruth, predicted_inverse)return confusion_matrix_arrs
然后,我们可以将每个数组中的像素映射为不同的颜色。对于下图,我们将TP,FP,FN,TN映射到CMYK(青色,品红色,黄色,黑色)空间。同样可以将它们映射到(绿色,红色,红色,绿色)颜色。然后,我们将获得一张图像,其中所有红色均表示错误的预测。CMYK空间使我们能够区分TP,TN。
get_confusion_matrix_overlaid_mask()
def get_confusion_matrix_overlaid_mask(image, groundtruth, predicted, alpha, colors):"""Returns overlay the 'image' with a color mask where TP, FP, FN, TN areeach a color given by the 'colors' dictionary"""image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)masks = get_confusion_matrix_intersection_mats(groundtruth, predicted)color_mask = np.zeros_like(image)for label, mask in masks.items():color = colors[label]mask_rgb = np.zeros_like(image)mask_rgb[mask != 0] = colorcolor_mask += mask_rgbreturn cv2.addWeighted(image, alpha, color_mask, 1 - alpha, 0)alpha = 0.5confusion_matrix_colors = {'tp': (0, 255, 255), #cyan'fp': (255, 0, 255), #magenta'fn': (255, 255, 0), #yellow'tn': (0, 0, 0) #black}validation_mask = get_confusion_matrix_overlaid_mask(255 - grayscale, groundtruth, predicted, alpha, confusion_matrix_colors)print('Cyan - TP')print('Magenta - FP')print('Yellow - FN')print('Black - TN')plt.imshow(validation_mask)plt.axis('off')plt.title('confusion matrix overlay mask')
我们在此处使用OpenCV将此颜色蒙版作为透明层覆盖到原始(非反转)灰度图像上。这称为Alpha合成:

总结
存储库中的最后两个示例通过调用测试函数来测试边缘情况和在小的数组(少于10个元素)上的随机预测场景。如果我们测试该算法的简单逻辑,则测试边缘情况和潜在问题很重要。
Travis CI对于测试我们的代码是否可以在需求中描述的模块版本上工作以及在新更改合并到主版本中时所有测试通过均非常有用。最佳做法是保持代码整洁,文档完善,并对所有语句进行单元测试和覆盖。这些习惯限制了在复杂的算法建立在可能已经进行了单元测试的简单功能块之上时,消除错误的需求。通常,文档和单元测试可帮助其他人随时了解功能意图。整理有助于提高代码的可读性,而flake8是实现此目的的良好Python包。
以下是本文的重要内容:
1. 适用于内存中不适合的数据的拼接和拼接方法
2. 尝试不同的阈值技术
3. 验证指标的精妙之处
4. 验证可视化
5. 最佳实践
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~