
深度学习实战之布匹缺陷检测
前言
缺陷检测是工业上非常重要的一个应用,由于缺陷多种多样,传统的机器视觉算法很难做到对缺陷特征完整的建模和迁移,复用性不大,要求区分工况,这会浪费大量的人力成本。深度学习在特征提取和定位上取得了非常好的效果,越来越多的学者和工程人员开始将深度学习算法引入到缺陷检测领域中。
导师一直鼓励小编做一些小项目,将学习与动手相结合。于是最近小编找来了某个大数据竞赛中的一道缺陷检测题目,在开源目标检测框架的基础上实现了一个用于布匹瑕疵检测的模型。现将过程稍作总结,供各位同学参考。
问题简介
01
实际背景
布匹的疵点检测是纺织工业中的一个十分重要的环节。当前,在纺织工业的布匹缺陷检测领域,人工检测仍然是主要的质量检测方式。而近年来由于人力成本的提升,以及人工检测存在的检测速度慢、漏检率高、一致性差、人员流动率高等问题,越来越多的工厂开始利用机器来代替人工进行质检,以提高生产效率,节省人力成本。
题目内容
开发出高效准确的深度学习算法,检验布匹表面是否存在缺陷,如果存在缺陷,请标注出缺陷的类型和位置。
数据分析
• 题目数据集提供了9576张图片用于训练,其中有瑕疵图片5913张,无瑕疵图片3663张。
• 瑕疵共分为15个类别。分别为:沾污、错花、水卬、花毛、缝头、缝头印、虫粘、破洞、褶子、织疵、漏印、蜡斑、色差、网折、其它
• 尺寸:4096 * 1696

算法分享
02
1.框架选择
比较流行的算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN等),它们是two-stage的,需要先算法产生目标候选框,也就是目标位置,然后再对候选框做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个卷积神经网络CNN直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。考虑本次任务时间限制和小编电脑性能,本次小编采用了单阶段YOLOV5的方案。
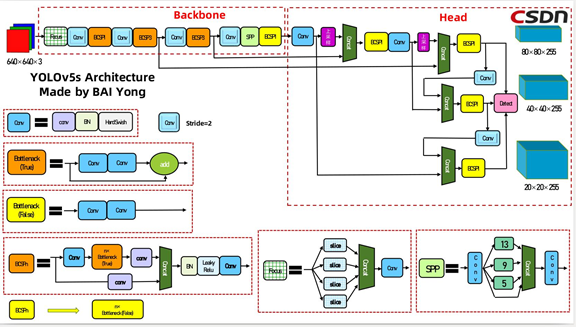
YOLO直接在输出层回归bounding box的位置和bounding box所属类别,从而实现one-stage。通过这种方式,Yolo可实现45帧每秒的运算速度,完全能满足实时性要求(达到24帧每秒,人眼就认为是连续的)。
整个系统如下图所示
2.环境配置(参考自 YOLOv5 requirements)
Cythonnumpy==1.17opencv-pythontorch>=1.4matplotlibpillowtensorboardPyYAML>=5.3torchvisionscipytqdmgit+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI
3.数据预处理
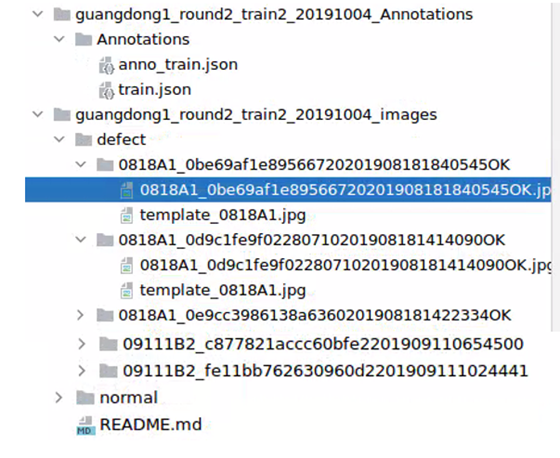
· 数据集文件结构
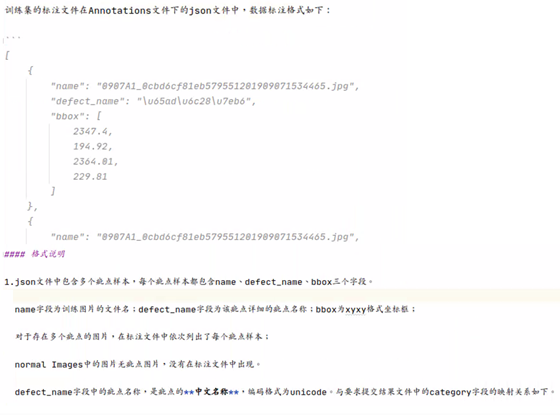
· 标注格式说明

· YOLO要求训练数据文件结构:
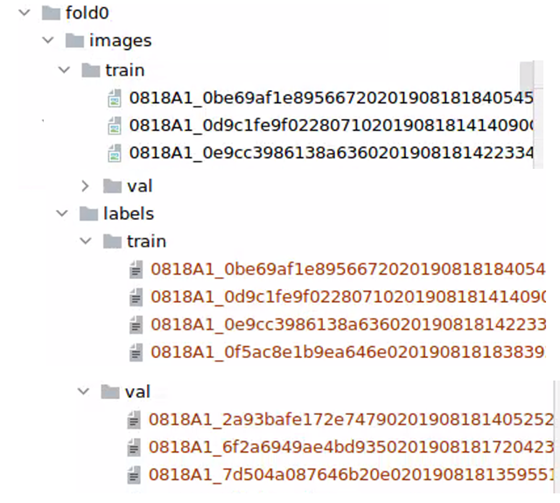

· 比赛数据格式 -> YOLO数据格式:
(针对本问题原创代码)
for fold in [0]:val_index = index[len(index) * fold // 5:len(index) * (fold + 1) // 5]print(len(val_index))for num, name in enumerate(name_list):print(c_list[num], x_center_list[num], y_center_list[num], w_list[num], h_list[num])row = [c_list[num], x_center_list[num], y_center_list[num], w_list[num], h_list[num]]if name in val_index:path2save = 'val/'else:path2save = 'train/'if not os.path.exists('convertor/fold{}/labels/'.format(fold) + path2save):os.makedirs('convertor/fold{}/labels/'.format(fold) + path2save)with open('convertor/fold{}/labels/'.format(fold) + path2save + name.split('.')[0] + ".txt", 'a+') as f:for data in row:f.write('{} '.format(data))f.write('\n')if not os.path.exists('convertor/fold{}/images/{}'.format(fold, path2save)):os.makedirs('convertor/fold{}/images/{}'.format(fold, path2save))sh.copy(os.path.join(image_path, name.split('.')[0], name),'convertor/fold{}/images/{}/{}'.format(fold, path2save, name))
4.超参数设置(针对本问题原创代码)
# Hyperparametershyp = {'lr0': 0.01,'momentum': 0.937, # SGD momentum'weight_decay': 5e-4,'giou': 0.05,'cls': 0.58,'cls_pw': 1.0,'obj': 1.0,'obj_pw': 1.0,'iou_t': 0.20,'anchor_t': 4.0,'fl_gamma': 0.0,'hsv_h': 0.014,'hsv_s': 0.68,'hsv_v': 0.36,'degrees': 0.0,'translate': 0.0,'scale': 0.5,'shear': 0.0}
5.模型核心代码(针对本问题原创代码)
import argparsefrom models.experimental import *class Detect(nn.Module):def __init__(self, nc=80, anchors=()):super(Detect, self).__init__()self.stride = Noneself.nc = ncself.no = nc + 5self.nl = len(anchors)self.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nla = torch.tensor(anchors).float().view(self.nl, -1, 2)self.register_buffer('anchors', a)self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2))self.export = Falsedef forward(self, x):z = []self.training |= self.exportfor i in range(self.nl):bs, _, ny, nx = x[i].shapex[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training:if self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i] = self._make_grid(nx, ny).to(x[i].device)y = x[i].sigmoid()y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i]y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)@staticmethoddef _make_grid(nx=20, ny=20):yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()class Model(nn.Module):def __init__(self, model_cfg='yolov5s.yaml', ch=3, nc=None):super(Model, self).__init__()if type(model_cfg) is dict:self.md = model_cfgelse:import yamlwith open(model_cfg) as f:self.md = yaml.load(f, Loader=yaml.FullLoader)# Define modelif nc and nc != self.md['nc']:print('Overriding %s nc=%g with nc=%g' % (model_cfg, self.md['nc'], nc))self.md['nc'] = ncself.model, self.save = parse_model(self.md, ch=[ch])# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, Detect):s = 128 # 2x min stridem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))])m.anchors /= m.stride.view(-1, 1, 1)check_anchor_order(m)self.stride = m.strideself._initialize_biases()# Init weights, biasestorch_utils.initialize_weights(self)self._initialize_biases()torch_utils.model_info(self)print('')def forward(self, x, augment=False, profile=False):if augment:img_size = x.shape[-2:] # height, widths = [0.83, 0.67] # scales #1.2 0.83y = []for i, xi in enumerate((x,torch_utils.scale_img(x.flip(3), s[0]), # flip-lr and scaletorch_utils.scale_img(x, s[1]), # scale)):# cv2.imwrite('img%g.jpg' % i, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1])y.append(self.forward_once(xi)[0])y[1][..., :4] /= s[0]y[1][..., 0] = img_size[1] - y[1][..., 0]y[2][..., :4] /= s[1]return torch.cat(y, 1), Noneelse:return self.forward_once(x, profile)def forward_once(self, x, profile=False):y, dt = [], []for m in self.model:if m.f != -1:x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f]if profile:try:import thopo = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPSexcept:o = 0t = torch_utils.time_synchronized()for _ in range(10):_ = m(x)dt.append((torch_utils.time_synchronized() - t) * 100)print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))x = m(x)y.append(x if m.i in self.save else None)if profile:print('%.1fms total' % sum(dt))return xdef _initialize_biases(self, cf=None):m = self.model[-1] # Detect() modulefor f, s in zip(m.f, m.stride):mi = self.model[f % m.i]b = mi.bias.view(m.na, -1)b[:, 4] += math.log(8 / (640 / s) ** 2)b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum())mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)def _print_biases(self):m = self.model[-1] # Detect() modulefor f in sorted([x % m.i for x in m.f]):b = self.model[f].bias.detach().view(m.na, -1).Tprint(('%g Conv2d.bias:' + '%10.3g' * 6) % (f, *b[:5].mean(1).tolist(), b[5:].mean()))def fuse(self):print('Fusing layers... ', end='')for m in self.model.modules():if type(m) is Conv:m.conv = torch_utils.fuse_conv_and_bn(m.conv, m.bn) # update convm.bn = None # remove batchnormm.forward = m.fuseforward # update forwardtorch_utils.model_info(self)return selfdef parse_model(md, ch): # model_dict, input_channels(3)print('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))anchors, nc, gd, gw = md['anchors'], md['nc'], md['depth_multiple'], md['width_multiple']na = (len(anchors[0]) // 2) # number of anchorsno = na * (nc + 5)layers, save, c2 = [], [], ch[-1]for i, (f, n, m, args) in enumerate(md['backbone'] + md['head']):m = eval(m) if isinstance(m, str) else mfor j, a in enumerate(args):try:args[j] = eval(a) if isinstance(a, str) else aexcept:passn = max(round(n * gd), 1) if n > 1 else nif m in [nn.Conv2d, Conv, PW_Conv,Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, BottleneckMOB]:c1, c2 = ch[f], args[0]# Normal# c2 = int(ch[1] * ex ** e)c2 = make_divisible(c2 * gw, 8) if c2 != no else c2# Experimental# ch1 = 32# c2 = int(ch1 * ex ** e)# c2 = make_divisible(c2, 8) if c2 != no else c2args = [c1, c2, *args[1:]]if m in [BottleneckCSP, C3]:args.insert(2, n)n = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])elif m is Detect:f = f or list(reversed([(-1 if j == i else j - 1) for j, x in enumerate(ch) if x == no]))else:c2 = ch[f]m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args)t = str(m)[8:-2].replace('__main__.', '') # module typenp = sum([x.numel() for x in m_.parameters()]) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsprint('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args))save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1)layers.append(m_)ch.append(c2)return nn.Sequential(*layers), sorted(save)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')opt = parser.parse_args()opt.cfg = check_file(opt.cfg) # check filedevice = torch_utils.select_device(opt.device)# Create modelmodel = Model(opt.cfg).to(device)model.train()
训练截图
6.测试模型并生成结果(针对本问题原创代码)
for *xyxy, conf, cls in det:if save_txt: # Write to filexywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) /gn).view(-1).tolist() # normalized xywhwith open(txt_path + '.txt', 'a') as f:f.write(('%g ' * 5 + '\n') %(cls, *xywh)) # label format# write to jsonif save_json:name = os.path.split(txt_path)[-1]print(name)x1, y1, x2, y2 = float(xyxy[0]), float(xyxy[1]), float(xyxy[2]), float(xyxy[3])bbox = [x1, y1, x2, y2]img_name = nameconf = float(conf)#add solution remove otherresult.append({'name': img_name + '.jpg','category': int(cls + 1),'bbox': bbox,'score': conf})
7.结果展示
后记
03
针对布匹瑕疵检测问题,我们首先分析了题目要求,确定了我们的任务是检测到布匹中可能存在的瑕疵,对其进行分类并将其在图片中标注出来。接下来针对问题要求我们选择了合适的目标检测框架YOLOv5,并按照YOLOv5的格式要求对数据集和标注进行了转换。然后我们根据问题规模设置了合适的超参数,采用迁移学习的思想,基于官方的预训练模型进行训练以加快收敛速度。模型训练好以后,即可在验证集上验证我们模型的性能和准确性。
—版权声明—
来源:数据魔术师 作者:张宇
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!