
【深度学习】实战:使用Mask-RCNN的停车位检测
如何使用Mask-RCNN检测停车位可用性?

空/占用停车位

Mask-RCNN对象检测和分割

YOLO模型检测停车场上的车辆

Mask-RCNN模型预测

并非所有停车位都已标注
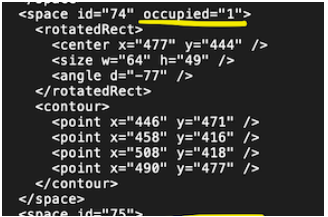
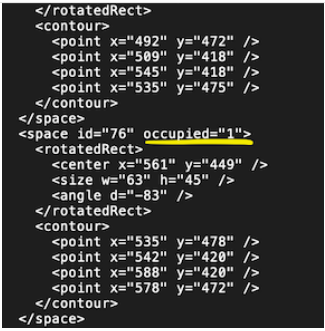
注释文件中缺少信息
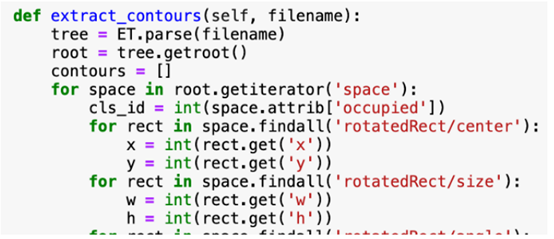

函数解析xml文件,提取停车位的轮廓
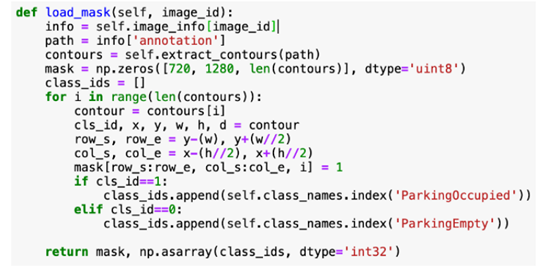
函数在边界框之外创建掩码,并创建两个要检测的类

创建停车场类

停车配置类
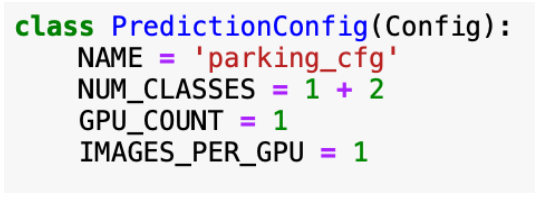
预测配置类
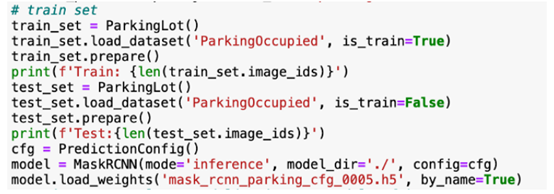

函数绘制检测对象的边界框


Mask-RCNN检测可用停车位



往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论