
UNet 和 UNet++:医学影像经典分割网络对比
作者:Sergey Kolchenko
编译:ronghuaiyang
转自:AI公园
在不同的任务上对比了UNet和UNet++以及使用不同的预训练编码器的效果。

介绍
语义分割是计算机视觉的一个问题,我们的任务是使用图像作为输入,为图像中的每个像素分配一个类。在语义分割的情况下,我们不关心是否有同一个类的多个实例(对象),我们只是用它们的类别来标记它们。有多种关于不同计算机视觉问题的介绍课程,但用一张图片可以总结不同的计算机视觉问题:
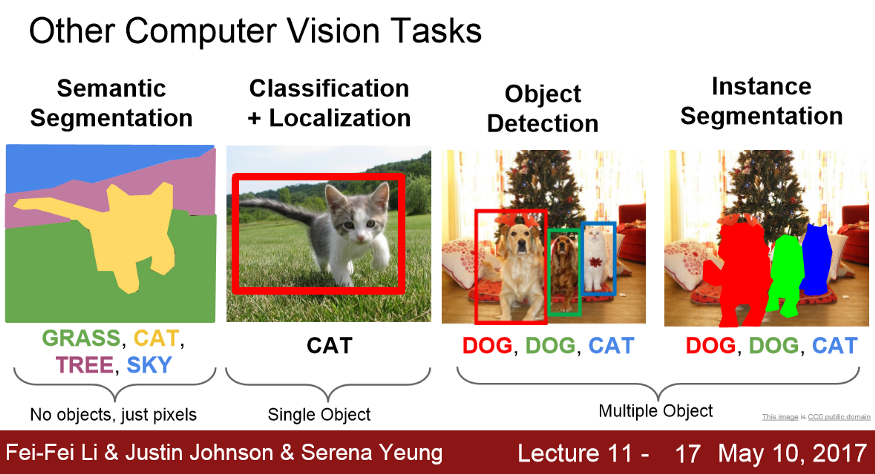
语义分割在生物医学图像分析中有着广泛的应用:x射线、MRI扫描、数字病理、显微镜、内窥镜等。https://grand-challenge.org/challenges上有许多不同的有趣和重要的问题有待探索。
从技术角度来看,如果我们考虑语义分割问题,对于N×M×3(假设我们有一个RGB图像)的图像,我们希望生成对应的映射N×M×k(其中k是类的数量)。有很多架构可以解决这个问题,但在这里我想谈谈两个特定的架构,Unet和Unet++。
有许多关于Unet的评论,它如何永远地改变了这个领域。它是一个统一的非常清晰的架构,由一个编码器和一个解码器组成,前者生成图像的表示,后者使用该表示来构建分割。每个空间分辨率的两个映射连接在一起(灰色箭头),因此可以将图像的两种不同表示组合在一起。并且它成功了!
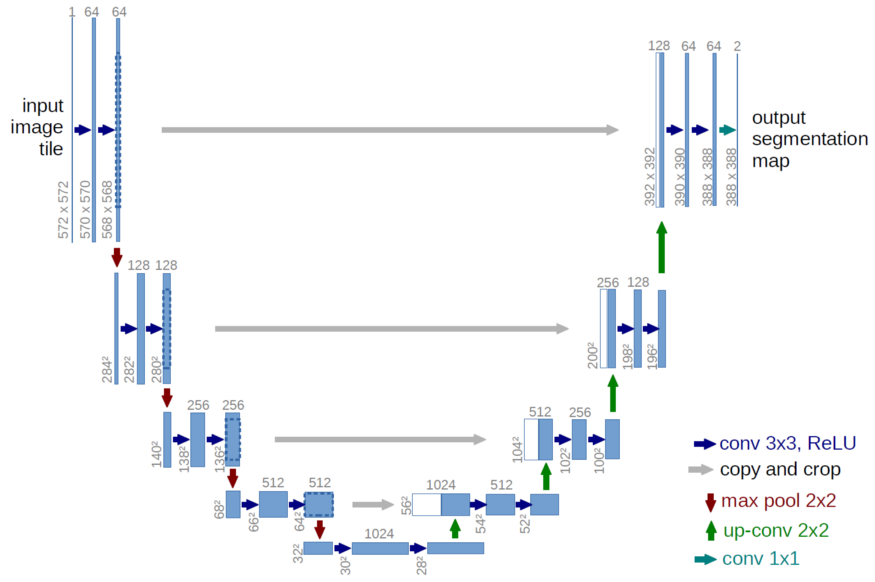
接下来是使用一个训练好的编码器。考虑图像分类的问题,我们试图建立一个图像的特征表示,这样不同的类在该特征空间可以被分开。我们可以(几乎)使用任何CNN,并将其作为一个编码器,从编码器中获取特征,并将其提供给我们的解码器。据我所知,Iglovikov & Shvets 使用了VGG11和resnet34分别为Unet解码器以生成更好的特征和提高其性能。
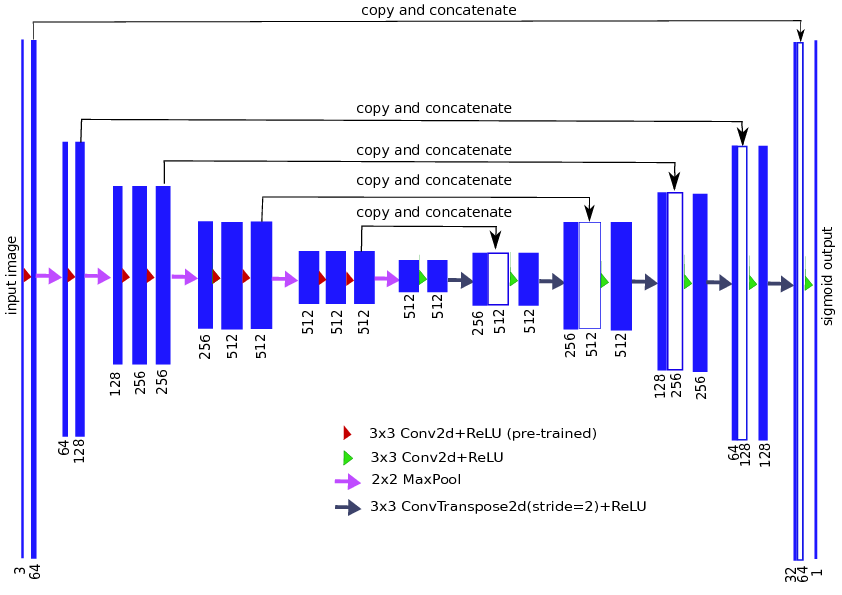
Unet++是最近对Unet体系结构的改进,它有多个跳跃连接。
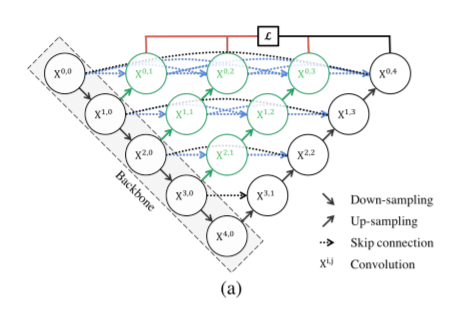
根据论文, Unet++的表现似乎优于原来的Unet。就像在Unet中一样,这里可以使用多个编码器(骨干)来为输入图像生成强特征。
我应该使用哪个编码器?
这里我想重点介绍Unet和Unet++,并比较它们使用不同的预训练编码器的性能。为此,我选择使用胸部x光数据集来分割肺部。这是一个二值分割,所以我们应该给每个像素分配一个类为“1”的概率,然后我们可以二值化来制作一个掩码。首先,让我们看看数据。
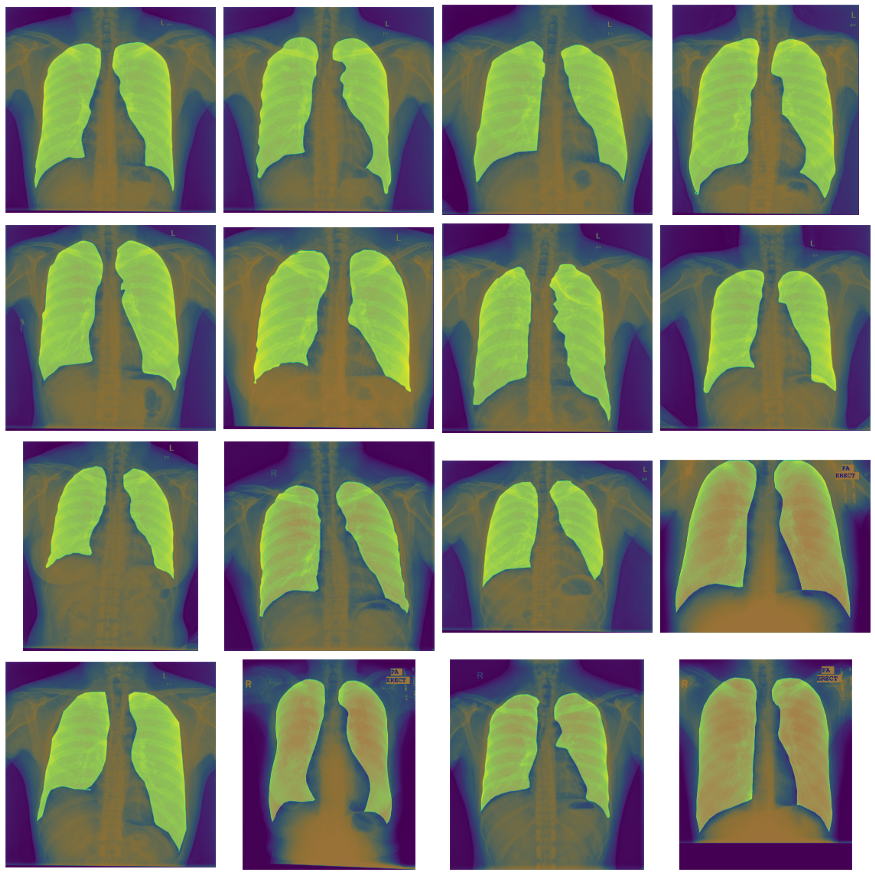
这些是非常大的图像,通常是2000×2000像素,有很大的mask,从视觉上看,找到肺不是问题。使用segmentation_models_pytorch库,我们为Unet和Unet++使用100+个不同的预训练编码器。我们做了一个快速的pipeline来训练模型,使用Catalyst (pytorch的另一个库,这可以帮助你训练模型,而不必编写很多无聊的代码)和Albumentations(帮助你应用不同的图像转换)。
定义数据集和增强。我们将调整图像大小为256×256,并对训练数据集应用一些大的增强。
import albumentations as A
from torch.utils.data import Dataset, DataLoader
from collections import OrderedDict
class ChestXRayDataset(Dataset):
def __init__(
self,
images,
masks,
transforms):
self.images = images
self.masks = masks
self.transforms = transforms
def __len__(self):
return(len(self.images))
def __getitem__(self, idx):
"""Will load the mask, get random coordinates around/with the mask,
load the image by coordinates
"""
sample_image = imread(self.images[idx])
if len(sample_image.shape) == 3:
sample_image = sample_image[..., 0]
sample_image = np.expand_dims(sample_image, 2) / 255
sample_mask = imread(self.masks[idx]) / 255
if len(sample_mask.shape) == 3:
sample_mask = sample_mask[..., 0]
augmented = self.transforms(image=sample_image, mask=sample_mask)
sample_image = augmented['image']
sample_mask = augmented['mask']
sample_image = sample_image.transpose(2, 0, 1) # channels first
sample_mask = np.expand_dims(sample_mask, 0)
data = {'features': torch.from_numpy(sample_image.copy()).float(),
'mask': torch.from_numpy(sample_mask.copy()).float()}
return(data)
def get_valid_transforms(crop_size=256):
return A.Compose(
[
A.Resize(crop_size, crop_size),
],
p=1.0)
def light_training_transforms(crop_size=256):
return A.Compose([
A.RandomResizedCrop(height=crop_size, width=crop_size),
A.OneOf(
[
A.Transpose(),
A.VerticalFlip(),
A.HorizontalFlip(),
A.RandomRotate90(),
A.NoOp()
], p=1.0),
])
def medium_training_transforms(crop_size=256):
return A.Compose([
A.RandomResizedCrop(height=crop_size, width=crop_size),
A.OneOf(
[
A.Transpose(),
A.VerticalFlip(),
A.HorizontalFlip(),
A.RandomRotate90(),
A.NoOp()
], p=1.0),
A.OneOf(
[
A.CoarseDropout(max_holes=16, max_height=16, max_width=16),
A.NoOp()
], p=1.0),
])
def heavy_training_transforms(crop_size=256):
return A.Compose([
A.RandomResizedCrop(height=crop_size, width=crop_size),
A.OneOf(
[
A.Transpose(),
A.VerticalFlip(),
A.HorizontalFlip(),
A.RandomRotate90(),
A.NoOp()
], p=1.0),
A.ShiftScaleRotate(p=0.75),
A.OneOf(
[
A.CoarseDropout(max_holes=16, max_height=16, max_width=16),
A.NoOp()
], p=1.0),
])
def get_training_trasnforms(transforms_type):
if transforms_type == 'light':
return(light_training_transforms())
elif transforms_type == 'medium':
return(medium_training_transforms())
elif transforms_type == 'heavy':
return(heavy_training_transforms())
else:
raise NotImplementedError("Not implemented transformation configuration")
定义模型和损失函数。这里我们使用带有regnety_004编码器的Unet++,并使用RAdam + Lookahed优化器使用DICE + BCE损失之和进行训练。
import torch
import segmentation_models_pytorch as smp
import numpy as np
import matplotlib.pyplot as plt
from catalyst import dl, metrics, core, contrib, utils
import torch.nn as nn
from skimage.io import imread
import os
from sklearn.model_selection import train_test_split
from catalyst.dl import CriterionCallback, MetricAggregationCallback
encoder = 'timm-regnety_004'
model = smp.UnetPlusPlus(encoder, classes=1, in_channels=1)
#model.cuda()
learning_rate = 5e-3
encoder_learning_rate = 5e-3 / 10
layerwise_params = {"encoder*": dict(lr=encoder_learning_rate, weight_decay=0.00003)}
model_params = utils.process_model_params(model, layerwise_params=layerwise_params)
base_optimizer = contrib.nn.RAdam(model_params, lr=learning_rate, weight_decay=0.0003)
optimizer = contrib.nn.Lookahead(base_optimizer)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.25, patience=10)
criterion = {
"dice": DiceLoss(mode='binary'),
"bce": nn.BCEWithLogitsLoss()
}
定义回调函数并训练!
callbacks = [
# Each criterion is calculated separately.
CriterionCallback(
input_key="mask",
prefix="loss_dice",
criterion_key="dice"
),
CriterionCallback(
input_key="mask",
prefix="loss_bce",
criterion_key="bce"
),
# And only then we aggregate everything into one loss.
MetricAggregationCallback(
prefix="loss",
mode="weighted_sum",
metrics={
"loss_dice": 1.0,
"loss_bce": 0.8
},
),
# metrics
IoUMetricsCallback(
mode='binary',
input_key='mask',
)
]
runner = dl.SupervisedRunner(input_key="features", input_target_key="mask")
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=loaders,
callbacks=callbacks,
logdir='../logs/xray_test_log',
num_epochs=100,
main_metric="loss",
minimize_metric=True,
verbose=True,
)
如果我们用不同的编码器对Unet和Unet++进行验证,我们可以看到每个训练模型的验证质量,并总结如下:
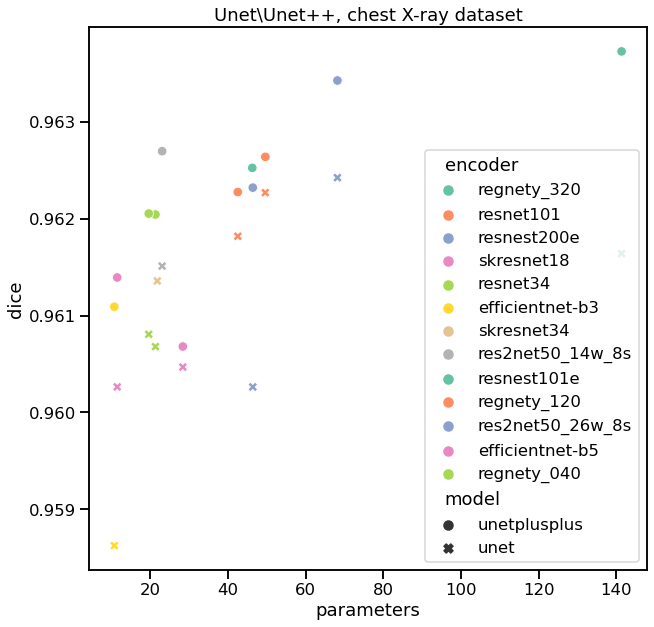
我们注意到的第一件事是,在所有编码器中,Unet++的性能似乎都比Unet好。当然,有时这种差异并不是很大,我们不能说它们在统计上是否完全不同 —— 我们需要在多个folds上训练,看看分数分布,单点不能证明任何事情。第二,resnest200e显示了最高的质量,同时仍然有合理的参数数量。有趣的是,如果我们看看https://paperswithcode.com/task/semantic-segmentation,我们会发现resnest200在一些基准测试中也是SOTA。
好的,但是让我们用Unet++和Unet使用resnest200e编码器来比较不同的预测。
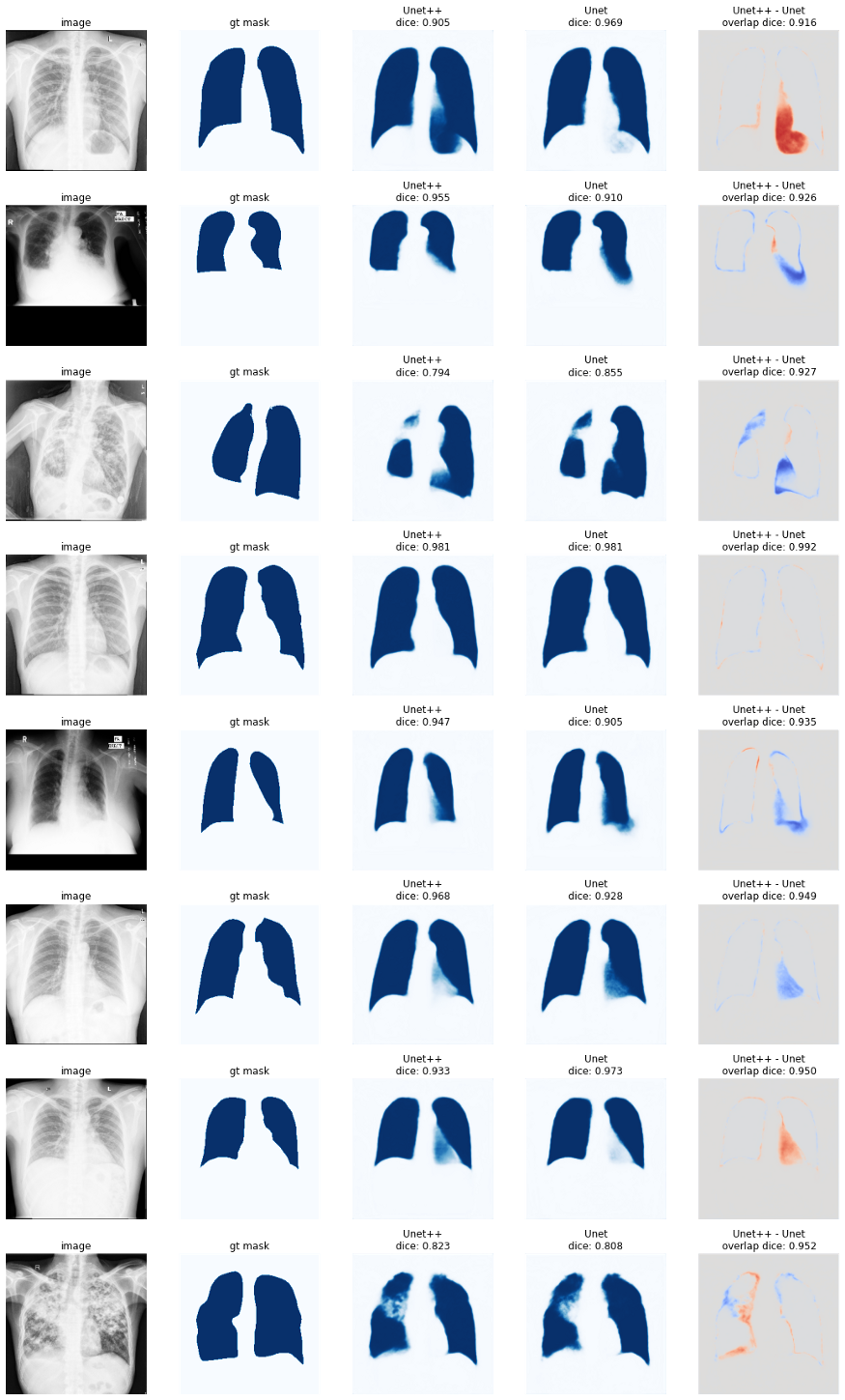
在某些个别情况下,Unet++实际上比Unet更糟糕。但总的来说似乎更好一些。
一般来说,对于分割网络来说,这个数据集看起来是一个容易的任务。让我们在一个更难的任务上测试Unet++。为此,我使用PanNuke数据集,这是一个带标注的组织学数据集(205,343个标记核,19种不同的组织类型,5个核类)。数据已经被分割成3个folds。
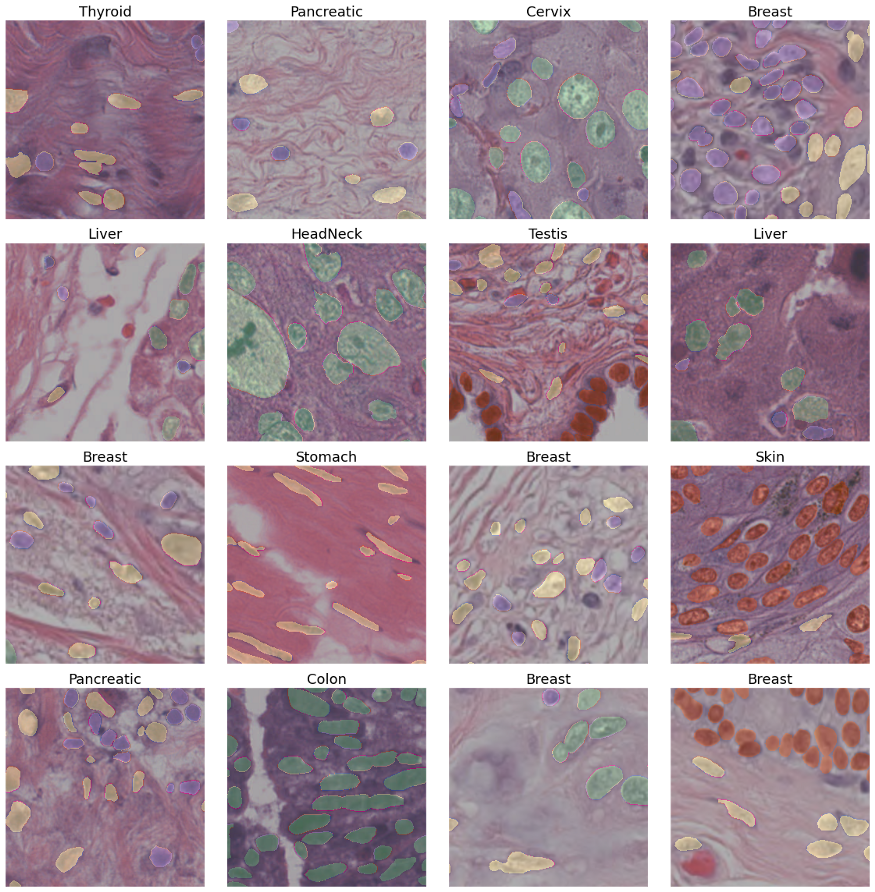
我们可以使用类似的代码在这个数据集上训练Unet++模型,如下所示:
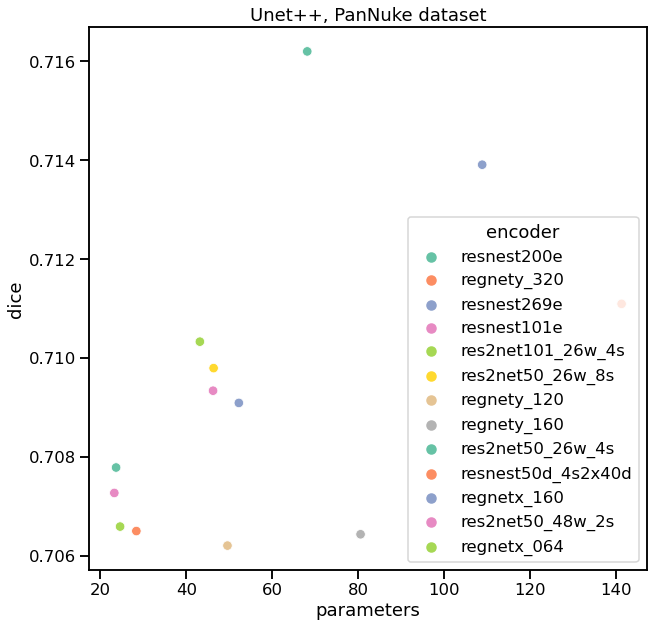
我们在这里看到了相同的模式 - resnest200e编码器似乎比其他的性能更好。我们可以用两个不同的模型(最好的是resnest200e编码器,最差的是regnety_002)来可视化一些例子。
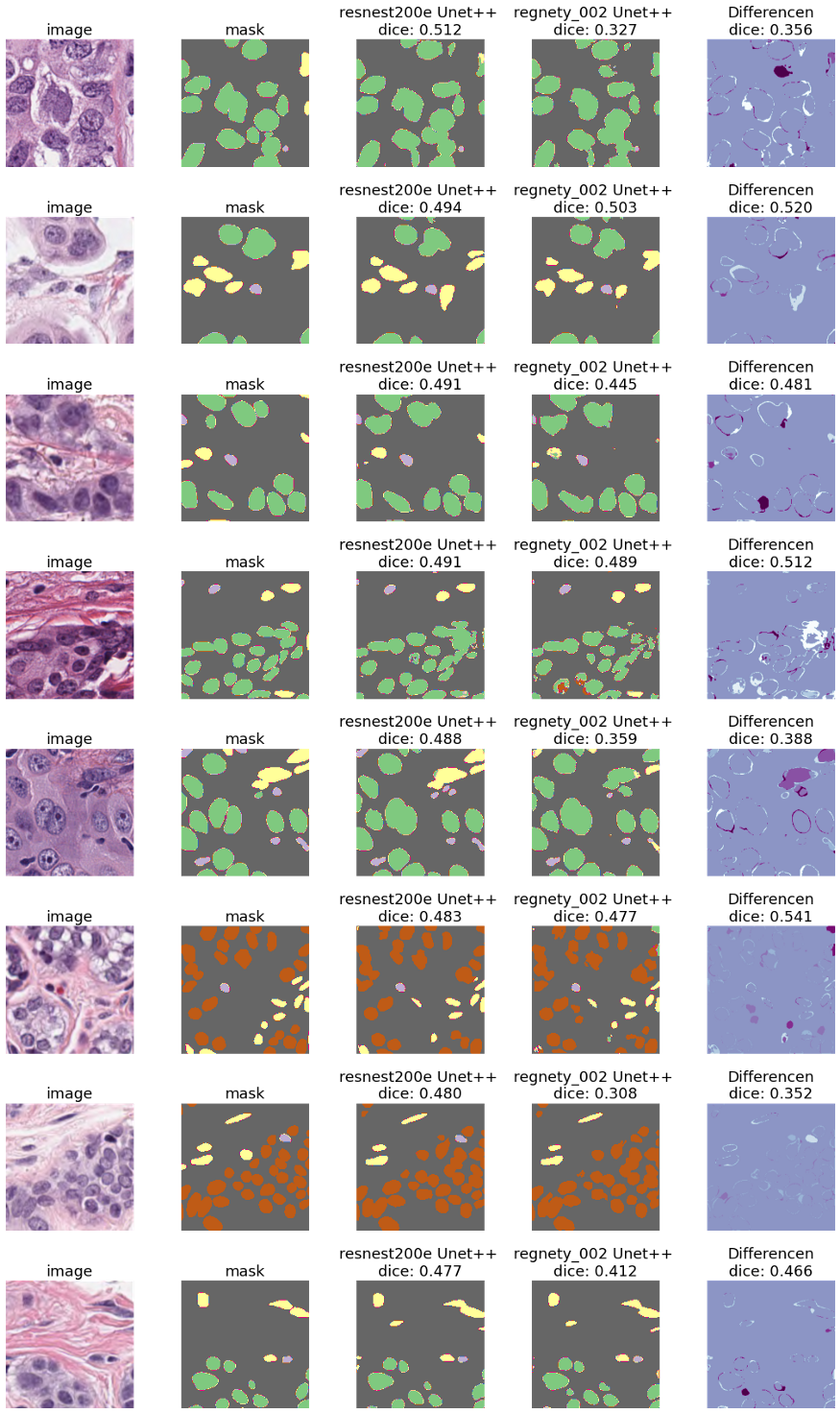
我们可以肯定地说,这个数据集是一项更难的任务 —— 不仅mask不够精确,而且个别的核被分配到错误的类别。然而,使用resnest200e编码器的Unet++仍然表现很好。
总结
这不是一个全面语义分割的指导,这更多的是一个想法,使用什么来获得一个坚实的基线。有很多模型、FPN,DeepLabV3, Linknet与Unet有很大的不同,有许多Unet-like架构,例如,使用双编码器的Unet,MAnet,PraNet,U²-net — 有很多的型号供你选择,其中一些可能在你的任务上表现的比较好,但是,一个坚实的基线可以帮助你从正确的方向上开始。
英文原文:
https://towardsdatascience.com/the-best-approach-to-semantic-segmentation-of-biomedical-images-bbe4fd78733f
往期精彩: