
医学图像分割:UNet++
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
使用一系列的网格状的密集跳跃路径来提升分割的准确性。
在这篇文章中,我们将探索UNet++: A Nested U-Net Architecture for Medical Image Segmentation这篇文章,作者是亚利桑那州立大学的Zhou等人。本文是U-Net的延续,我们将把UNet++与Ronneberger等人的U-Net原始文章进行比较。
UNet++的目标是通过在编码器和解码器之间加入Dense block和卷积层来提高分割精度。
分割的准确性对于医学图像至关重要,因为边缘分割错误会导致不可靠的结果,从而被拒绝用于临床中。
为医学成像设计的算法必须在数据样本较少的情况下实现高性能和准确性。获取这些样本图像来训练模型可能是一个消耗资源的过程,因为需要由专业人员审查的高质量、未压缩和精确注释的图像。
UNet++里有什么新东西?
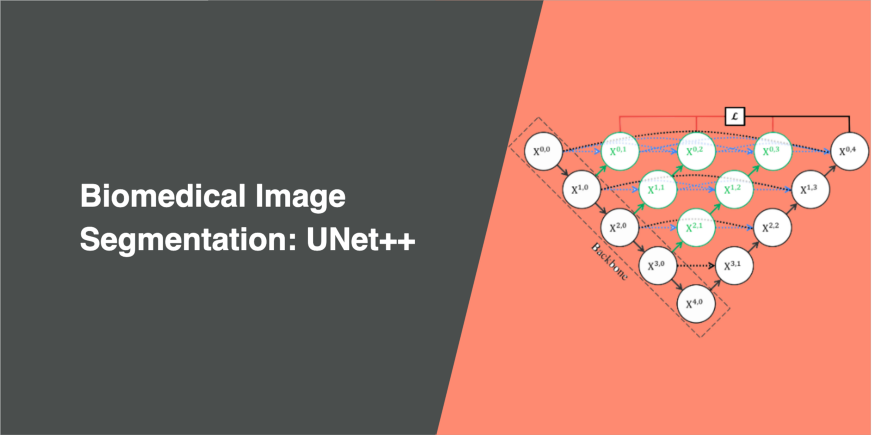
下面是UNet++和U-Net架构的示意图。
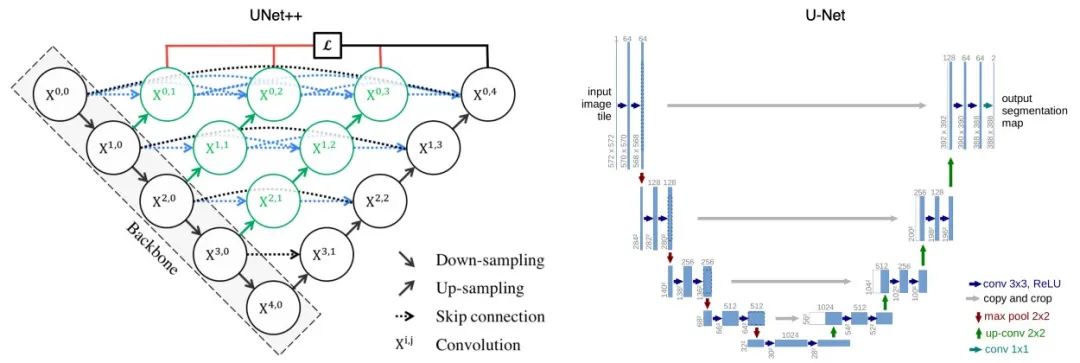
UNet++ 在原始的U-Net上加了3个东西:
重新设计的跳跃路径(显示为绿色) 密集跳跃连接(显示为蓝色) 深度监督(显示为红色)
重新设计的跳跃路径
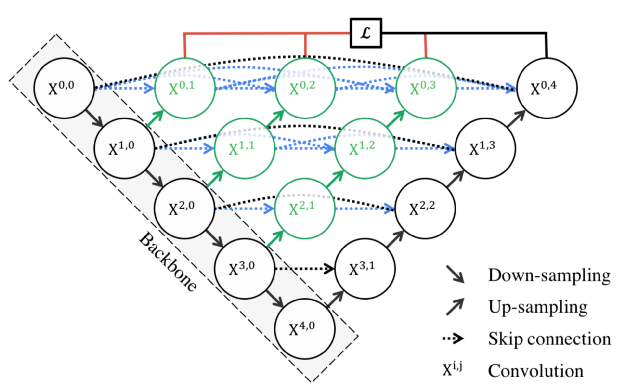
在UNet++中,增加了重新设计的跳跃路径(绿色显示),以弥补编码器和解码器子路径之间的语义差别。
这些卷积层的目的是减少编码器和解码器子网络的特征映射之间的语义差距。因此,对于优化器来说,这可能是一个更直接的优化问题。
U-Net采用跳跃连接,直接连接编码器和解码器之间的特征映射,导致把语义上不相似的特征映射相融合。
然而,在UNet++中,相同dense block的前一个卷积层的输出与较低层dense block对应的上采样输出进行融合。这使得已编码特征的语义级别更接近于等待在解码器中的特征映射的语义级别,因此,当接收到语义上相似的特征映射时,优化更容易。
跳跃路径上的所有卷积层使用大小为3×3的核。
密集跳跃连接
在UNet++中,密集跳跃连接(用蓝色显示)实现了编码器和解码器之间的跳跃路径。这些Dense blocks是受到DenseNet的启发,目的是提高分割精度和改善梯度流。
密集跳跃连接确保所有先验特征图都被累积,并通过每个跳跃路径上的dense卷积块而到达当前节点。这将在多个语义级别生成完整分辨率的特征映射。
深度监督
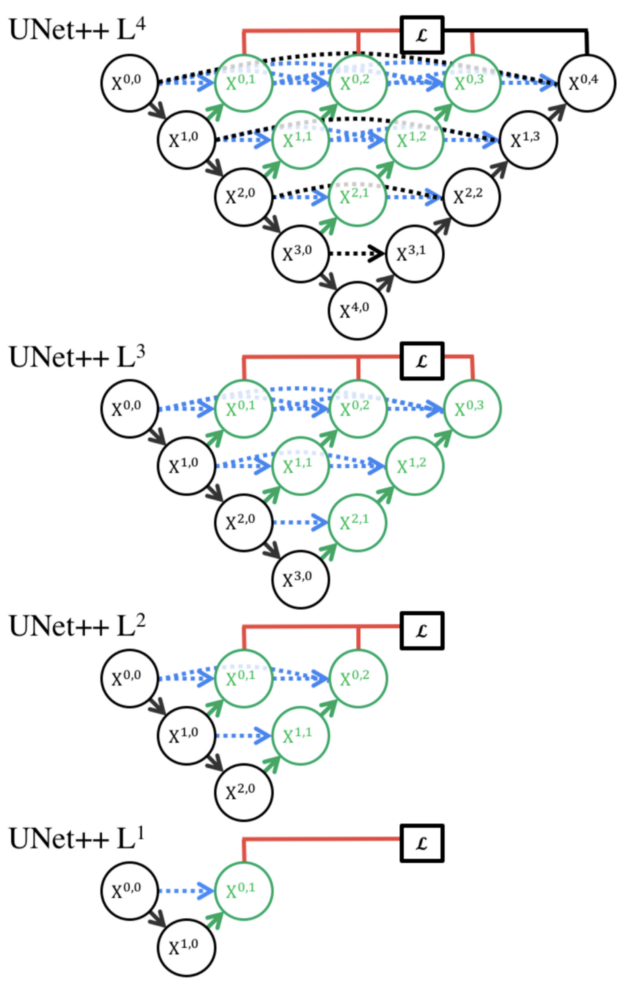
UNet++中增加了深度监督(红色显示),通过修剪模型来调整模型的复杂性,在速度(推理时间)和性能之间实现平衡。
对于accurate模式,所有分割分支的输出进行平均。
对于fast模式,最终的分割图从分割分支之一选择。
Zhou等人进行了实验,以确定在不同剪枝水平下的最佳分割性能。使用的度量是IoU和推理时间。
他们试验了四种分割任务:a)细胞核,b)结肠息肉,c)肝脏,d)肺结节。结果如下:

L3与L4相比,平均减少了32.2%的推理时间,同时IoU略微降低了。
更激进的修剪方法,如L1和L2,可以进一步减少推理时间,但以显著的分割性能为代价。
在使用UNet++时,我们可以调整用例的层数。
在UNet++上的实验
我使用Drishti-GS数据集,这与Ronneberger等人在他们的论文中使用的不同。该数据集包含101幅视网膜图像,以及用于检测青光眼的光学disc和光学cup的mask标注。青光眼是世界上致盲的主要原因之一。50张图片用于训练,51张用于验证。
度量
我们需要一组指标来比较不同的模型,这里我们有二元交叉熵,Dice 系数和IoU。
二元交叉熵
二分类的常用度量和损失函数,用于度量误分类的概率。
我们将使用PyTorch的binary_cross_entropy_with_logits函数,与Dice系数一起作为损失函数对模型进行训练。
Dice 系数
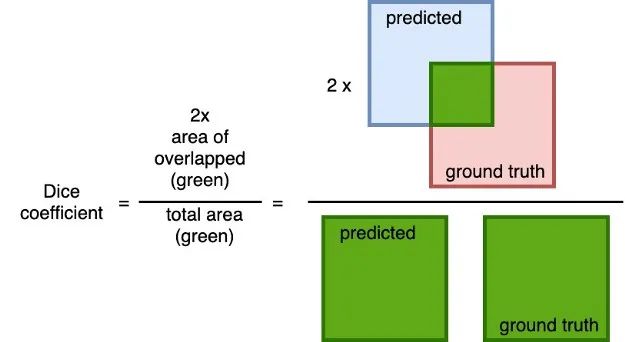
对预测值和实际值之间重叠的通用的度量。计算方法为 2 × 预测值与ground truth的重叠面积除以预测值与ground truth之和的总面积。
这个度量指标的范围在0到1之间,其中1表示完全重叠。
我使用这个度量和二元交叉熵作为训练模型的损失函数。
IoU
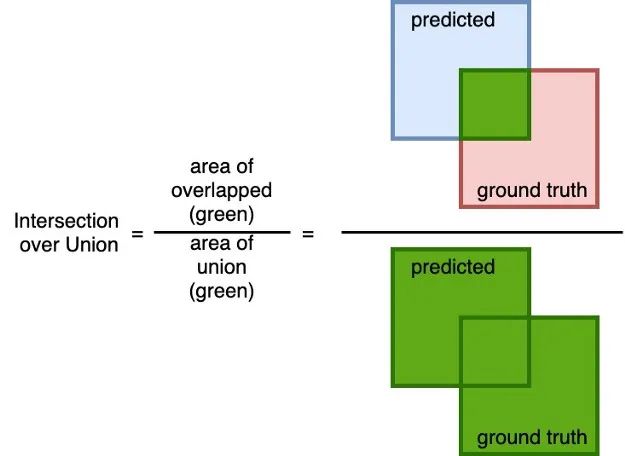
一个简单(但有效!)的度量来计算预测的mask与ground truth mask的准确性。计算预测值与ground truth的重叠面积,并除以预测值与ground truth的并集面积。
类似于Dice系数,这个度量指标的范围是从0到1,其中0表示没有重叠,而1表示预测与地面真实之间完全重叠。
训练和结果
优化这个模型,训练50多个epoch,使用Adam优化器,学习率1e-4,学习率衰减率为没10个epochs乘以0.1,
损失函数是二元交叉熵和Dice 系数的组合。
模型在27分钟内完成了36.6M可训练参数的训练,每个epoch大约需要32秒。

表现最好的epoch是第45个epoch(在50个epochs中)。
二元交叉熵:0.2650 Dice系数:0.8104 IoU:0.8580
几个U-Net模型之间的指标进行比较,如下所示。

测试首先通过模型处理一些没见过的样本,来预测光学disc(红色)和光学cup(黄色)。这里是UNet++和U-Net的测试结果对比。

从指标表来看,UNet++在IoU上超越U-Net,但在Dice系数上表现较差。从定性测试的结果来看,UNet++成功地对第一张图像进行了正确的分割,而U-Net做得并不好。也由于UNet++的复杂性,训练时间是U-Net的两倍。必须根据它们的数据集评估每种方法。
总结
UNet++的目标是提高分割精度,通过一系列嵌套的,密集的跳跃路径来实现。重新设计的跳跃路径使语义相似的特征映射更容易优化。密集的跳跃连接提高了分割精度,改善了梯度流。深度监督允许模型复杂性调优,以平衡速度和性能优化。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~