
差分卷积在计算机视觉中的应用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

编者荐语
文章主要介绍由Oulu大学主导的几个差分卷积(Difference Convolution)工作及其在图像、视频领域中的应用。
作者丨Fisher 鱼子 @知乎
链接丨https://zhuanlan.zhihu.com/p/392986663
1.鼻祖LBP的简单回顾
在传统的手工特征中,比较经典的有Oulu提出的 LBP(Local Binary Patterns),即局部二值模式 [1],至今引用已有16000+。最初的LBP是定义在3×3邻域内的,以邻域中心像素为阈值,将相邻的8个像素的灰度值与其进行差分比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该邻域中心像素点的LBP值,并用这个值来反映该区域的纹理信息。

用公式表示为:
LBP算子运算速度快,同时聚合了邻域内的差分信息,对光照变化较为鲁棒;同时也能较好地描述细粒度的纹理信息,故在早期纹理识别,人脸识别等都被广泛应用。下图为人脸图像在做LBP变换后的LBP码图像,可以看出脸部局部纹理特征较好地被表征:

2.中心差分卷积CDC在人脸活体检测中的应用 [2,3]
CDC代码链接: github.com/ZitongYu/CDC
Vanilla卷积通常直接聚合局部intensity-level的信息,故 1)容易受到外界光照等因素的影响;2)比较难表征细粒度的特征。在人脸活体检测任务中,前者容易导致模型的泛化能力较弱,如在未知的光照环境下测试性能较低;后者会导致难以学到防伪本质的细节信息,如spoof的材质。考虑到空间差分特征具有较强光照不变性,同时也包含更细粒度的spoof线索(如栅格效应,屏幕反射等),借鉴传统LBP的差分思想,我们提出了中心差分卷积(Central difference convolution, CDC)。

假定邻域  为3x3区域,公式表达如下: 为了更好同时利用 intensity-level 和 gradient-level 的信息,我们通过超参 及共享卷积可学习的权重,统一了VanillaConv和CDC,而无需额外的可学习参数(和可忽略的计算量)。故更generalized的CDC公式为:
为3x3区域,公式表达如下: 为了更好同时利用 intensity-level 和 gradient-level 的信息,我们通过超参 及共享卷积可学习的权重,统一了VanillaConv和CDC,而无需额外的可学习参数(和可忽略的计算量)。故更generalized的CDC公式为:
θ控制着差分卷积及Vanilla卷积的贡献,值越大意味着gradient clue占比越重;当θ=0时,就成了Vanilla卷积。文章 [3]中也具体对比了CDC与前人工作Local Binary Convolution [4], Gabor Convolution [5] 和 Self-Attention layer [6],有兴趣的请查阅原文。
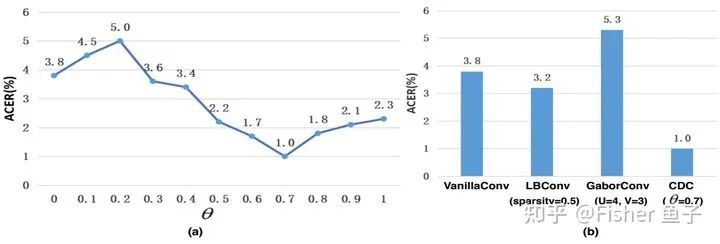
上图可见,当 时,使用CDC效果总比单独Vanilla卷积要好(也就是 )。我们也观察到,当 时,该协议下活体检测性能处于最优,并优于LBConv [4]和GaborConv [5]。
3.交叉中心差分卷积C-CDC在人脸活体检测中的应用 [7]
C-CDC代码链接:
github.com/ZitongYu/CDC
考虑到CDC需要对所有邻域特征都进行差分操作,存在着较大的冗余,同时各方向的梯度聚合使得网络优化较为困难,我们提出了交差中心差分卷积(Cross-CDC),将CDC解耦成水平垂直和对角线两个对称交叉的子算子:
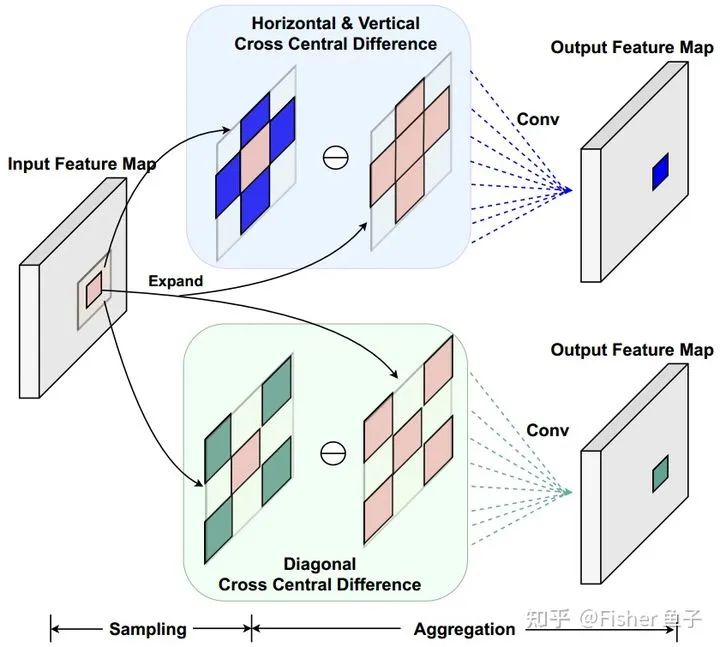
具体实现只需将感受野从原本的3x3邻域 改成对应水平垂直或者对角方向的子邻域  即可。使用C-CDC(HV)或者C-CDC(DG)后,如下表所示,网络的参数量和FLOPs都大幅度减少,并取得与原本CDC媲美的性能。
即可。使用C-CDC(HV)或者C-CDC(DG)后,如下表所示,网络的参数量和FLOPs都大幅度减少,并取得与原本CDC媲美的性能。

在下图(b)消融实验中可见,相比CDC (ACER=1%),C-CDC(HV) 和 C-CDC(DG)也能取得相当的性能。有趣的是,如果对于VanillaConv进行HV或者DG方向的分解,性能就会下降得比较严重,intensity-level信息对于充足感受野范围需求较大。

4.像素差分卷积PDC在边缘检测中的应用 [8]
PDC代码链接:
GitHub - zhuoinoulu/pidinet: Code for ICCV 2021 paper "Pixel Difference Networks for Efficient Edge Detection"
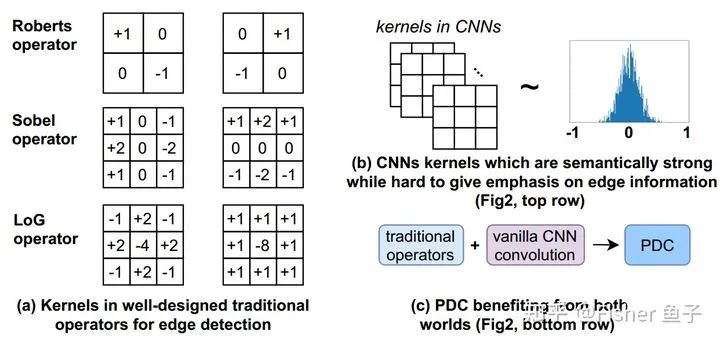
在边缘检测中,如下图(a)所示,经典的传统操作子(如Roberts, Sobel和LoG)都采用差分信息来表征边缘上下文的突变及细节特征。但是这些基于手工传统算子的模型往往局限于它的浅层表征能力。另外一方面, CNN通过卷积的深层堆叠,能够有效地捕捉图像的语义特征。在此过程中,卷积核扮演了捕捉局部图像模式的作用。而如下图(b)所示,VanillaCNN在对卷积核的初始化过程中并没有显式的梯度编码限制,使其在训练过程中很难聚焦对图像梯度信息的提取,从而影响了边缘预测的精度。
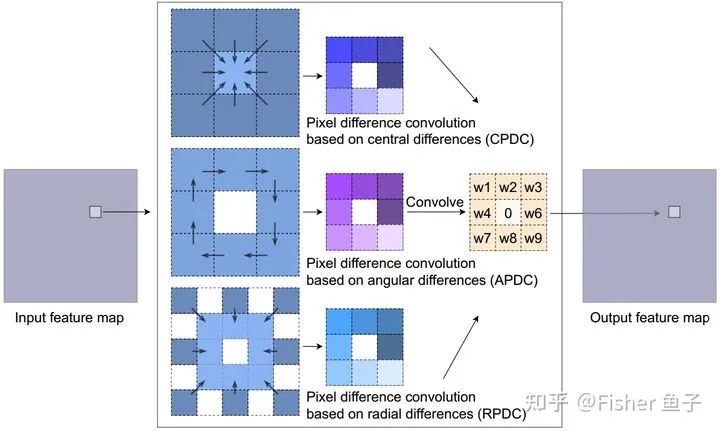
为了高效地引入差分操作到CNN中,借鉴于Extended LBP (ELBP) [9],我们提出了像素差分卷积(Pixel difference convolution, PDC)。根据候选像素对的采样策略,PDC具体分为下图所示三种子形式,其中CPDC类似CDC对邻域特征进行中心差分;而APDC对邻域进行顺时针方向的两两差分;最后RPDC对更大感受野5x5邻域的外环与内环进行差分。
文中另外一个贡献是提出了高效转换PDC为VanillaConv的实现及推导证明,即先计算卷积核weights间的difference,接着直接对输入的特征图进行卷积。该tweak不仅可以加速training阶段,而且还可降低在inference阶段的额外差分计算量。以CPDC为例,转换公式如下: 具体的三种PDC如何组合效果最好,可阅读文章消融实验及分析。最后下图可视化了PiDiNet-Tiny网络配套VanillaConv或者PDC后的特征图及边缘预测。明显的是,使用PDC后,gradient信息的增强有利于更精确的边缘检测。

5.时空差分卷积3D-CDC在视频手势/动作识别中的应用 [10]
3D-CDC代码链接:
github.com/ZitongYu/3DC
不同于静态spatial图像分析,帧间的motion信息在spatio-temporal视频分析中往往扮演着重要角色。很多经典motion算子,如光流optical flow和动态图dynamic image的计算都或多或少包含着帧内spatial、帧间temporal、帧间spatio-temporal的差异信息。当下主流的3DCNN一般都采用vanilla 2D、3D、伪3D的卷积操作,故较难感知细粒度的时空差异信息。与部分已有工作设计额外Modules(如OFF [11],MFNet [12])的思路不同,我们设计了时空差分卷积(3D-CDC)来高效提取时空差异特征,可取代Vanilla3DConv,直插直用于任何3DCNN,并无额外参数开销。
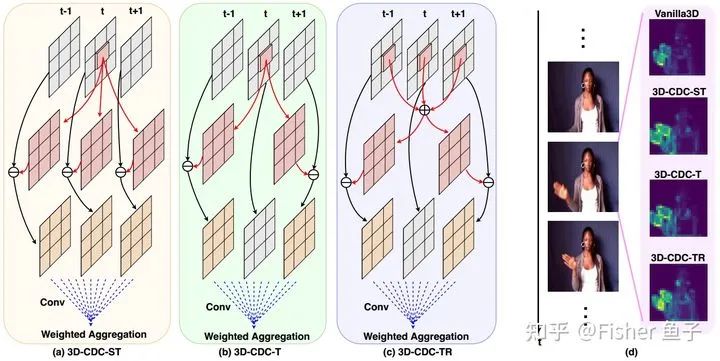
如上图所示,3D-CDC家族有包含三种子卷积,来增强时域特征的同时服务于不同场景。如3DCDC-ST擅长于动态纹理表征;3D-CDC-T则更多捕捉精细的时域上下文信息;而3DCDC-TR则更耐抗时域间噪声扰动 。它们的generalized版本公式如下:( 相邻帧)
下图给出了C3D模型基于3D-CDC家族的性能,可见针对不同模态(尤其是RGB和光流),在大部分 θ取值 下3D-CDC-T和3D-CDC-TR能带来额外的视频表征收益( θ=0仅为使用Vanilla3DConv)。

6.其他差分卷积及应用
文献 [13] 将 CDC 思想应用到图卷积中,形成差分图卷积(Central Difference Graph Convolution,CDGC)。
文献 [14] 将 CDC 应用到实时 Saliency detection 任务中。
文献 [15] 将 3D-CDC 应用到 人脸远程生理信号rPPG测量 中。
文献 [18] 将 CDC 应用到 人脸 DeepFake detection 中。
文献 [19] 将 PDC 拓展为random版本,应用到人脸识别,表情识别,种族识别中。
7.总结与展望
一方面,如何将可解释性强的经典传统算子(如LBP, HOG, SIFT等)融入到最新的DL框架(CNN,Vision Transformer,MLP-like等)中来增强性能(如准确率,迁移性,鲁棒性,高效性等),将是持续火热的topic;另外一方面就是探索和应用到更多vision tasks 来服务计算机视觉落地。
Reference:
[1] Timo Ojala, et al. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. TPAMI 2002.
[2] Zitong Yu, et al. Searching central difference convolutional networks for face anti-spoofing. CVPR 2020.
[3] Zitong Yu, et al. Nas-fas: Static-dynamic central difference network search for face anti-spoofing. TPAMI 2020.
[4] Juefei Xu, et al. Local binary convolutional neural networks. CVPR 2017.
[5] Shangzhen Luan, et al. Gabor convolutional networks. TIP 2018.
[6] Ramachandran Prajit, et al. Stand-alone self-attention in vision models. NeurIPS 2019.
[7] Zitong Yu, et al. Dual-Cross Central Difference Network for Face Anti-Spoofing. IJCAI 2021.
[8] Zhuo Su, et al. Pixel Difference Networks for Efficient Edge Detection. ICCV 2021 (Oral)
[9] Li Liu, et al. Extended local binary patterns for texture classification. Image and Vision Computing 2012.
[10] Zitong Yu, et al. Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition. TIP 2021.
[11] Shuyang Sun, et al. Optical flow guided feature: A fast and robust motion representation for video action recognition. CVPR 2018.
[12] Myunggi Lee, et al. Motion feature network: Fixed motion filter for action recognition. ECCV 2018.
[13] Klimack, Jason. A Study on Different Architectures on a 3D Garment Reconstruction Network. MS thesis. Universitat Politècnica de Catalunya, 2021.
[14] Zabihi Samad, et al. A Compact Deep Architecture for Real-time Saliency Prediction. arXiv 2020.
[15] Zhao Yu, et al. Video-Based Physiological Measurement Using 3D Central Difference Convolution Attention Network. IJCB 2021.
[16] Zitong Yu, et al. Multi-modal face anti-spoofing based on central difference networks. CVPRW 2020.
[17] Haoyu Chen, et al. 2nd place scheme on action recognition track of ECCV 2020 VIPriors challenges: An efficient optical flow stream guided framework. arXiv 2020.
[18] Yang et al. MTD-Net: Learning to Detect Deepfakes Images by Multi-Scale Texture Difference, TIFS 2021
[19] Liu et al. Beyond Vanilla Convolution: Random Pixel Difference Convolution on Face Perception. IEEE Access 2021
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~