
计算机视觉中的自注意力
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文通过三篇不同的论文,尝试阐明视觉自我注意力的最新发展,并强调其可能带来的好处。
自从引入网络以来,深度学习中的注意力机制在机器翻译和 社区中广受欢迎。然而,在计算机视觉中,卷积神经网络 (CNN) 仍然是常态,自注意力才刚刚开始慢慢渗透到研究的主体中,要么补充现有的架构,要么完全取代它们。
在这篇文章中,我将尝试阐明视觉自注意力的最新发展,并强调其可能带来的好处。对于这项任务,我将展示三篇不同的论文,在我看来,它们很好地说明了计算机视觉中自我注意的最新技术。
我将介绍的第一篇论文是Guan等人来自医学影像分析社区,这让我有宾至如归的感觉。与自然图像(照片)不同,医学图像的外观通常非常相似。它们是使用来自标准化位置的类似采集参数获得的。对于放射科医生来说,阅读图像的经验主要来自于知道确切的位置以找到某种病理。因此,即使在其他研究领域之前,注意力在医学图像分析中也发挥了重要作用也就不足为奇了。
有问题的论文试图提高胸部射线图像自动胸部疾病分类的性能。以前,已经提出了仅通过查看全局图像来检测和分类胸部 X 射线病理的网络。因此,多标签分类是通过使用二进制交叉熵作为损失函数或其他一些标记机制(例如,使用作为解码器来捕获标签之间的相互依赖关系的编码器-解码器框架来执行的。
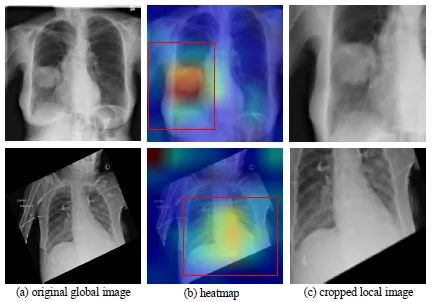
使用整个射线图像进行分类的问题在于,在医学图像中,病变区域与整个图像相比可能非常小,甚至可能位于边界某处,这会给分类器和分类器带来大量噪声。降低检测精度。此外,胸部射线图像经常出现错位(例如图1,第二行中的示例)。这种错位会导致图像周围的边界不规则,也可能对分类产生负面影响。
在论文中,作者使用递归硬注意力(即硬自注意力)通过裁剪出图像的判别部分并将全局图像和裁剪部分一起分类来提高检测精度(见图1)左侧的整个图像和右侧的裁剪部分)。
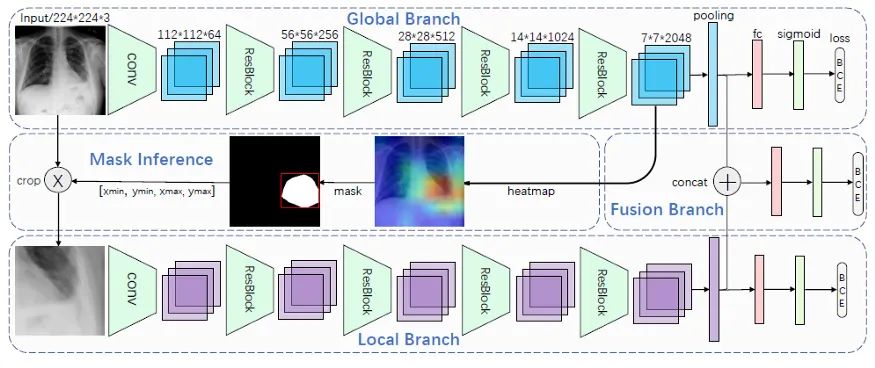
该网络由三个分支组成:
全局分支处理整个图像并确定裁剪ROI;
局部分支展示注意力机制并处理裁剪后的图像;
分支连接全局和局部分支的池化输出,并使用密集层执行最终分类。
所有分支都是分类网络,在最后执行多类分类(如图2所示)以预测病理的存在。除了分类之外,全局分支还用于生成确定裁剪区域的热图。热图是通过计算某个高级层沿通道的最大值来生成的。然后生成与热图大小相同的掩码。如果某个位置的每通道最大化热图的值大于某个阈值,则在该位置为掩码分配1。否则,掩码的值为0。之后裁剪区域被确定,以便所有掩码值为1的点都在裁剪范围内。然后图像的裁剪部分通过本地分支运行。此外,两个分支的输出在融合分支中融合以执行额外的分类。
网络训练分三步:
ImageNet 预训练的全局分支的微调;
掩码推理以获得裁剪图像并执行局部分支的微调。因此,全局分支中的权重是固定的;
连接全局和局部分支输出并微调融合分支,同时冻结其他分支的权重。
融合分支用于产生模型的最终分类结果,正如预期的那样,它比其他两个分支表现得更好。
为了从注意力的角度理解模型在做什么,我们必须首先了解软注意力和硬注意力之间的区别。本质上,注意力根据一些外部或内部(自注意力)提供的权重重新权衡网络的某些特征。因此,软注意力允许这些权重是连续的,而硬注意力要求它们是二进制的,即0或1。这个模型是硬注意力的一个例子,因为它裁剪了图像的某个部分,因此本质上是对原始图像重新加权,以便裁剪部分的权重为1,其余为0。
硬注意力的主要缺点是它不可微,不能进行端到端的训练。相反,作者使用某个层的激活来确定并在复杂的多阶段过程中训练网络。为了训练注意力门,我们必须使用软注意力(例如使用或)。接下来我们将看看一些软注意力模型。
Squeeze-And-Excitation-Networks
Hu等人没有使用严格的注意力并在特征图的裁剪方面重新校准权重。通过使用软自注意力对卷积特征通道之间的相互依赖性进行建模,研究了在CNN的某个层中重新加权通道响应。为此,作者介绍了构建块(见图3)。
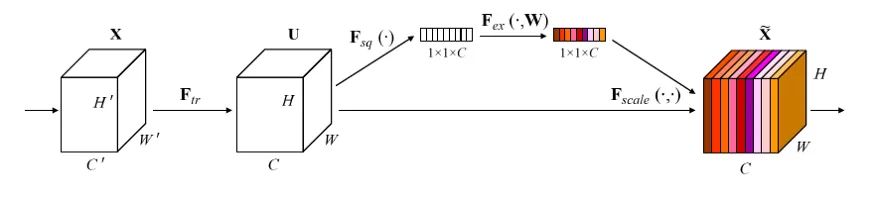
模块的工作原理如下:对于特征从X到U的任何变换(例如卷积),有一个变换聚合跨空间范围的全局特征响应。这就是挤压操作。挤压操作之后是激励操作,这是一个(自控门)操作,它构建了一个通道方式的权重响应。的输出随后与激励结果逐通道相乘(这在图3中被描绘为)。
挤压操作的数学描述是:
因此 是操作 的输出。挤压操作通过使用全局平均池化来创建全局嵌入。也可以使用全局最大池化,尽管作者指出平均池化会略微提高整体性能。
另一方面,激励块由下式描述:
因此,激励将挤压块的输出乘以学习的权重W1,将输出传递给ReLU函数 ,将输出乘以另一组权重W2,并在最后使用函数以确保产生的通道权重为正。因此,W1将维度减少了因子(可以视为超参数),而W2再次将其增加到原始通道数。最后,的通道特征响应乘以从激励块获得的权重。这可以被视为使用全局信息的通道上的自我注意功能。
模块背后的主要思想是在网络的决策过程中包含全局信息;卷积仅查看特定半径内的局部空间信息,而模块聚合来自整个感受野的信息。
作者的一个有趣观察是,在网络的早期阶段,不同类别的激励权重相对相似,并在后期变得更加具体。这与通常的假设相关,即较低层学习输入的更多一般特征,而较高层则越来越具有辨别力。此外,模块在网络的最后阶段没有多大意义,其中大多数激励变为 1。
这可以解释为,网络的最后阶段已经包含大部分全局信息和 操作没有带来新的信息内容。
方法的主要优势在于它非常灵活:作者提到了在广泛使用的架构中的集成,例如(见图 4)、 或。实际上,该块可以添加到网络的每个阶段,也可以仅添加到特定阶段。此外,它在可学习参数的数量方面只引入了轻微的开销。例如,与已包含2500万个参数的原始 ResNet 相比,使用模块的仅使用了约250万个额外参数。因此,这仅使复杂性增加了10%。
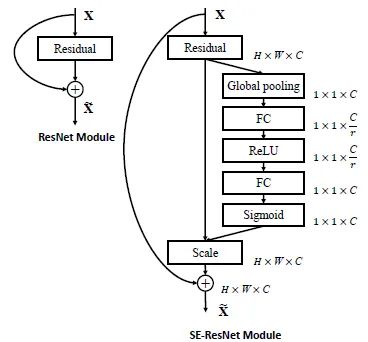
在论文中,作者展示了大量由模块增强的训练架构示例。特别是,他们能够在2017挑战中实现最先进的分类性能,前5名错误率仅为2.251%。
Stand-Alone Self-Attention
我将介绍的最后一篇文章 2019通过使用独立的自注意力块,而不是仅通过自注意力来增强卷积层,进一步阐述了中自注意力的想法。事实上,作者提出了一个自注意力层,可以用来代替卷积,同时减少参数的数量。
让我们回顾一下卷积操作来激发替换。卷积操作包括将特定大小(例如3x3)的权重矩阵与位置处的每个邻域相乘,并对结果进行空间求和。这实现了不同空间位置之间的权重共享。此外,权重的数量与输入大小无关。
与卷积类似,论文提出的自注意力层也适用于周围的一个小邻域,称为记忆块。对于每个内存块,单头注意力计算如下:
因此,是查询, 是键,是根据位置 及其邻域处的特征计算为线性变换的值。矩阵是学习到的变换。
从公式中可以看出,转换后的中心像素用作查询,键和值在邻域内求和。 函数也应用于以获得权重,然后将其与值相乘。
作者在本文中使用了多头注意力,这只是意味着将像素特征深度拆分为个相同大小的组,使用不同的矩阵 分别对每个组计算注意力,并将结果连接起来。图6提供了视觉自注意块的图形描述。
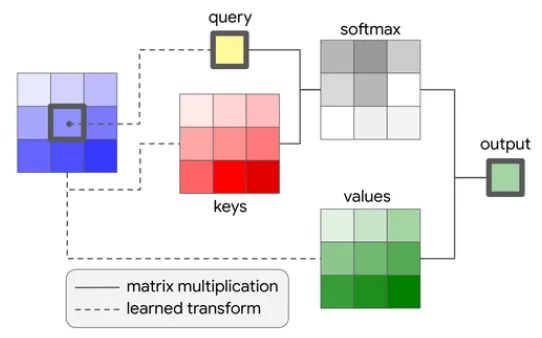
使用上述方法的一个问题是注意力块中没有编码位置信息,因此该公式对于单个像素的排列是不变的。位置信息对于视觉任务很重要:例如,如果您想检测人脸,您将需要知道在哪里寻找嘴巴、鼻子、耳朵等。
在原始论文中,作者使用位置的正弦嵌入作为附加输入。然而,在中,使用了相对位置嵌入,因为它们在计算机视觉任务中具有更好的准确性。这些相对嵌入是通过计算位置到每个邻域像素的相对距离来获得的。这些距离分为行距离和列距离和。这些嵌入被连接到一个矩阵形式并乘以查询 如下:
这确保了由函数计算的权重由键和查询的距离和内容调制。
从上面的描述我们可以看出,视觉自注意力是局部注意力的一种形式。注意层只关注内存块而不是整个特征图。这种方法的优点是参数的数量大大减少,不同空间位置之间的权重是共享的。作者提到他们的自注意力网络在训练和推理方面仍然比他们的对手慢,但是他们将这归因于高度优化的卷积核以及注意力层缺乏优化的硬件。
作者还展示了他们在上通过用自注意力块替换 中的 3x3 卷积获得的一些结果。请注意,它们保留了1x1卷积(基本上是按像素计算的全连接层)和卷积茎(网络中的前几个卷积层保持不变。有了这些变化,它们在以下方面的表现优于基线(标准)所有经过测试的架构()同时使用的减少了12%,参数减少了29%。
参考论文
[1] Guan, Qingji, et al. “Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification.” arXiv preprint arXiv:1801.09927 (2018).
[2] Yao, Li, et al. “Learning to diagnose from scratch by exploiting dependencies among labels.” arXiv preprint arXiv:1710.10501 (2017).
[3] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Ramachandran, Prajit, et al. “Stand-Alone Self-Attention in Vision Models.” arXiv preprint arXiv:1906.05909 (2019).
[5] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
原文链接:https://towardsdatascience.com/self-attention-in-computer-vision-2782727021f6

点个在看 paper不断!