
信息流场景中的计算机视觉技术应用
点击左上方蓝字关注我们

作者 | 李习华
链接 | https://zhuanlan.zhihu.com/p/54148166
从今日头条开始,各家公司把战火从传统的搜索领域烧到了信息流领域。今年,百度在基于手百的信息流上超过头条;腾讯的QQ浏览器、QQ看点、新闻、快报、微信看一看组合在一起的信息流也有足够大的体量;同时,各手机厂商,也借助端设备及设备原生浏览器app开始大举进入信息流领域。
无论从用户时长,还是商业变现模式上来讲,信息流都有很大的优势;另外,信息流作为第三代的用户获取信息的渠道(第一代:门户,第二代:搜索,第三代:信息流推荐),也有现实的用户需求。因此成为各个信息流app竞争的战场,并且在可预见的将来,这个领域的竞争会更加激烈,远没有到寡头形成的情况。当然,未来用户获取信息的渠道、内容都会具有多样性,各app也都会有各自的生存空间,诸侯割据。
言归正传,我们来讨论信息流领域的计算机视觉技术。信息流属于内容领域,因此在内容领域的各个环节都涉及到计算机视觉技术,包括:内容生成、内容审核、内容理解、内容分发4个主要的环节。整体流程如下图:

本质上,内容审核和内容分发甚至是内容生成都涉及到或者说都是基于对于图像和视频不同粒度、不同层次的理解。这里把每个部分分开更多的是方便后续对信息流中图像、视频内容整体的流向进行说明。涉及计算机视觉技术的对象一定包含图像或者视频,我们来看几个典型的信息流的截图:
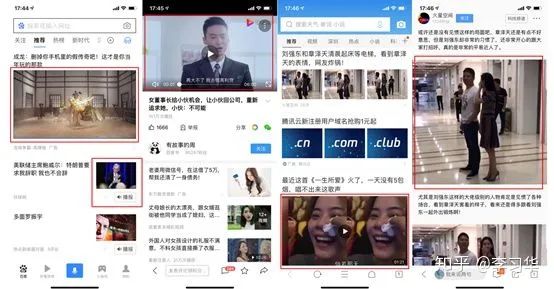
从图中可以看到,涉及计算机视觉技术的主体包含:
图文广告中的图片、动态jf图
Feeds展示页中的图片
Feeds详情页中的图片
Feeds展示页中的视频首图
Feeds内容页中的视频
事实上,feeds中涉及到的一切和图片和视频相关的内容都是本文中涉及的对象。甚至包括广告中涉及到的图片、jf图、视频等。我们通过下面的图片来了解一下用户通过APP浏览到的feeds都经过了什么样的大致流程。

下面对每一块对计算机视觉技术的需求做一些梳理。
内容生成
在上图中提到了图文、视频内容的生成源头,实际上不同的源头对计算机视觉技术的需求专业度、层次也不一样。有些技术由APP方提供,有些技术有第三方的工具提供。UGC、PGC、OGC对应不同的内容生产渠道,我们简单的介绍一下。
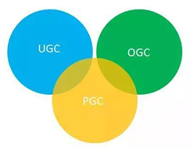
UGC:用户自己生产内容自己消费。
PGC:专业生产内容。比如我们在短视频中经常看到的电视剧的经典片段,多数是PGC生产的。
OGC:品牌生产内容,是指有一定知识和专业背景的行业人士生产内容,并且这些人士会采取相应的报酬。如平台媒体的记者、编辑,既有新闻的专业背景,也有以写稿为职业领取报酬。
针对UGC,用户自己产生的内容,我们说对应的计算机视觉的需求非常多。比如我们平时使用的美图、裁剪、磨皮、各种滤镜;用户UGC的短视频中的各种特效背后都是计算机视觉算法;还有一些场景,比如大疆无人机的video生成技术,实际上是对一段长度在5-10分钟的航拍视频进行video summary,当然这其中也有挑选好的场景、挑选好的画质等等技术。
针对PGC和OGC,有很多共性的需求。非常多的用于图像、视频处理的编辑的专业软件背后都是强大的计算机视觉技术,甚至包括动画、特效等等背后的技术。有一些技术需求,很隐性,举个例子:现在有一段西游记的视频,希望能够快速剪辑孙悟空的视频片段,这其中这涉及到通过图片、音频对孙悟空的识别技术来提升剪辑效率。
针对OGC,最近发现抖音上有一些视频技术是对视频片段中的目标(logo、食品等)进行识别,然后替换成具有商业价值的广告的技术。这背后都是计算机视觉技术在做支撑。
在内容生成领域,我们将应用到的计算机视觉技术概括如下:

内容审核
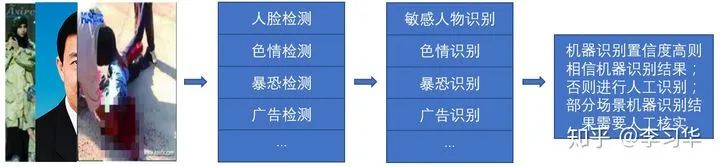
内容审核对各个公司都非常重要,从互联网诞生的那一天起,就存在内容审核。早期基本上都是人工,目前大致是人工+机器共同来完成整体的审核任务。早期的内容审核主要是鉴黄,现在内容审核扩展到了对图片和视频的鉴黄、暴恐识别、敏感人物识别、反感内容识别、广告识别、广告文本识别、违法宣传、二维码等非常多的维度。
本质上,内容审核是对图片、视频内容的理解,并根据法规、以及让互联网更健康为基本原则对不符合要求的图片、视频内容进过滤和分级。关于内容审核,总结起来,包含下图中的技术和业务。
内容理解
内容理解实际上是在对图文feeds,短视频进行结构化。目的是为了更好的做存储,筛选,过滤,召回,以及最后的内容分发。对人而言,内容理解实际上是一个非常高级的思维活动,比如一张图片,有些人关注构图,有些人关注清晰度,有些人关注图片里面的明星是谁,有些人则关注背景当中的车的品牌,毫不夸张,一千个读者有一千个哈姆雷特。
那对于机器而言,基于现有的计算机视觉技术,机器能做的其实比较有限,在这里,我们列举一下通过计算机视觉技术对图像、视频进行理解的大致技术。
1. 图片+视频的单标签、多标签、caption技术:这个也是目前工业界大家都在、都会、都力争做好的技术;
2. 图片+视频中的粗粒度、细粒度物体识别技术:目的是为了识别到图片+视频中更多的物体的细节;比如识别到图片中有汽车,更需要知道汽车的车型、颜色、品牌的信息;如果识别到人,更需要知道这个人的年龄段、穿什么样的衣服,如果可能,知道这个人是谁;
3. 图片+视频场景识别技术:很多时候,场景和标签可以合并;
4. 结合视频语音的内容理解技术,多模态识别技术;
5. 通过相似图片、视频检索获得对应图片、视频语义理解的图像搜索技术;
这个领域基本上涵盖了计算机视觉的方方面面,也是当前计算机视觉在力争解决的问题。总结起来,可以将对应的技术和需求概括如下:

内容分发
我们简单介绍一下类似头条、手百、抖音、QQ浏览器等产品进行内容分发的目的。本至少,会有多个目标,但不同阶段会有不同的侧重。某些情况,希望得到更多的用户时长;某些情况,希望能够获得更多的用户点击、关注、转发;有些情况,希望能够获得更多的商业回报。
分发技术是为了把用户可能兴趣的内容推荐给用户。所以涉及到方方面面,包括用户画像、用户的历史行为、用户当前处的环境,一个典型的feeds流推荐系统大致如下(示意图):
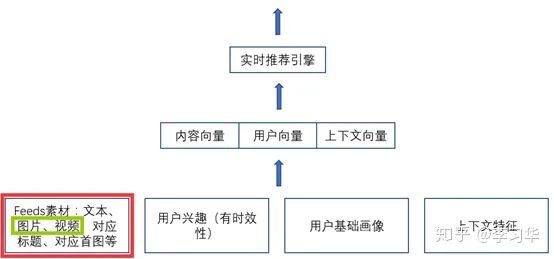
所以计算机视觉技术在分发中的应用主要是通过对图片、视频的理解,再结合文本内容,形成内容向量。早期,内容向量中视觉相关部分由图片、视频的标签组成;目前,内容向量中视觉相关部分通过深度网络学习到的特征向量的Embedding获得。
这里,我提到了内容向量中视觉相关部分。其他的内容向量由文本标题、描述、以及对应视频上的用户行为(点赞、转发、评论等)等形成。
最后,总结一下,我们从4个部分分别简述了feeds流中计算机视觉技术的应用场景,实际上我们发现,他涵盖了几乎计算机视觉领域的所以研究热点。也包含了计算机视觉领域从低、中、高多个层次对图片、视频内容的理解。但看似简单的技术背后,要满足实际的应用场景的要求,也有非常多的难点需要处理,将这些难点总结如下:
互联网足够丰富的素材内容将每一个问题都变成宽domain的问题。举个例子,OCR识别,规范化、常见字体的OCR识别目前已经做得足够好了,但是通过艺术字体和美术设计的OCR识别依旧很困难;甚至在广告审核中,作弊者会尝试非常多种的文字排版、设计方式,来欺骗AI系统,增加困难度;
少有的客观评价。图片、视频计算机视觉技术中,有部分不存在客观的评价。比如图片的美学评分,有人认为清晰的图片评分高,但有些艺术、摄影图片会故意制造模糊。比如video summary,本身也没有客观的标注,或者说有客观标准的summary就不是艺术,每一个做剪辑的工作者对同一段视频剪辑出来的精彩片段是不同的;
业务变化、需求变化:实际上这是所有学术成果转化到实际工业场景必须面临的问题。学术界一般都假设研究课题被well define,大家在同样的标准下来评比。但对于实际业务,需求、业务形态、技术的使用方式都变化很快,需要有良好的业务意识来调优;
如何证明业务价值:老大难的问题,因素很多...本质上,是分蛋糕的问题。
END
整理不易,点赞三连↓