
用Transformer完全替代CNN?

极市导读
本文不同于以往工作的地方在于,尽可能地将NLP领域的transformer不作修改地搬到了CV领域,并在大规模数据集上展现出了超过目前的一些SOTA的结果。>>加入极市CV技术交流群,走在计算机视觉的最前沿
这里将介绍一篇我认为是比较新颖的一篇文章 ——《An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale》[1]。因为还是 ICLR 2021 under review,所以作者目前还是匿名的,但是看其实验用到的TPU,能够大概猜出应该是Google爸爸的文章(看着实验的配置,不得不感慨钞能力的力量)。
1. Story
近年来,Transformer已经成了NLP领域的标准配置,但是CV领域还是CNN(如ResNet, DenseNet等)占据了绝大多数的SOTA结果。
最近CV界也有很多文章将transformer迁移到CV领域,这些文章总的来说可以分为两个大类:
将self-attention机制与常见的CNN架构结合; 用self-attention机制完全替代CNN。
本文采用的也是第2种思路。虽然已经有很多工作用self-attention完全替代CNN,且在理论上效率比较高,但是它们用了特殊的attention机制,无法从硬件层面加速,所以目前CV领域的SOTA结果还是被CNN架构所占据。
文章不同于以往工作的地方,就是尽可能地将NLP领域的transformer不作修改地搬到CV领域来。但是NLP处理的语言数据是序列化的,而CV中处理的图像数据是三维的(长、宽和channels)。
所以我们需要一个方式将图像这种三维数据转化为序列化的数据。文章中,图像被切割成一个个patch,这些patch按照一定的顺序排列,就成了序列化的数据。(具体将在下面讲述)
在实验中,作者发现,在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。作者认为是大规模的训练可以鼓励transformer学到CNN结构所拥有的translation equivariance 和locality.
translation equivariance解释:
https://aboveintelligent.com/ml-cnn-translation-equivariance-and-invariance-da12e8ab7049
2. Model

Vision Transformer (ViT)结构示意图
模型的结构其实比较简单,可以分成以下几个部分来理解:
a. 将图像转化为序列化数据
作者采用了了一个比较简单的方式。如下图所示。首先将图像分割成一个个patch,然后将每个patch reshape成一个向量,得到所谓的flattened patch。
具体地,如果图片是 维的,用 大小的patch去分割图片可以得到 个patch,那么每个patch的shape就是 ,转化为向量后就是 维的向量,将 个patch reshape后的向量concat在一起就得到了一个 的二维矩阵,相当于NLP中输入transformer的词向量。

分割图像得到patch
从上面的过程可以看出,当patch的大小变化时(即 变化时),每个patch reshape后得到的 维向量的长度也会变化。为了避免模型结构受到patch size的影响,作者对上述过程得到的flattened patches向量做了Linear Projection(如下图所示),将不同长度的flattened patch向量转化为固定长度的向量(记做 维向量)。
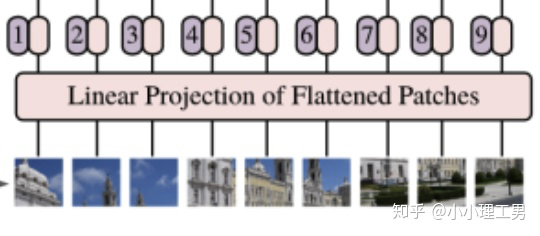
对flattened patches做linear projection
综上,原本 维的图片被转化为了 个 维的向量(或者一个 维的二维矩阵)。
b. Position embedding

positiion embedding示意图
由于transformer模型本身是没有位置信息的,和NLP中一样,我们需要用position embedding将位置信息加到模型中去。
如上图所示1,编号有0-9的紫色框表示各个位置的position embedding,而紫色框旁边的粉色框则是经过linear projection之后的flattened patch向量。文中采用将position embedding(即图中紫色框)和patch embedding(即图中粉色框)相加的方式结合position信息。
c. Learnable embedding
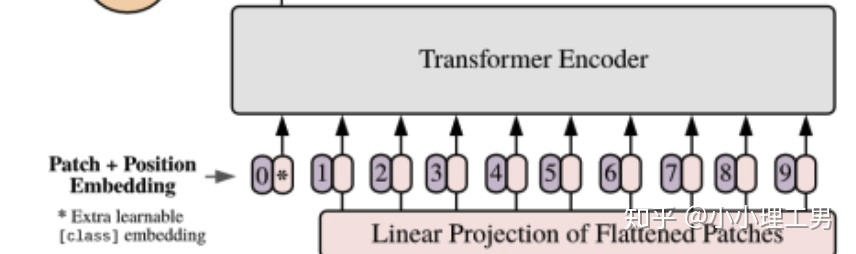
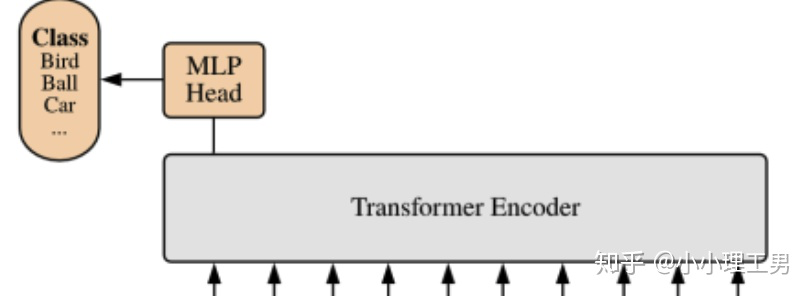
如果大家仔细看上图,就会发现带星号的粉色框(即0号紫色框右边的那个)不是通过某个patch产生的。这个是一个learnable embedding(记作 ),其作用类似于BERT中的[class] token。在BERT中,[class] token经过encoder后对应的结果作为整个句子的表示;类似地,这里 经过encoder后对应的结果也作为整个图的表示。
至于为什么BERT或者这篇文章的ViT要多加一个token呢?因为如果人为地指定一个embedding(例如本文中某个patch经过Linear Projection得到的embedding)经过encoder得到的结果作为整体的表示,则不可避免地会使得整体表示偏向于这个指定embedding的信息(例如图像的表示偏重于反映某个patch的信息)。而这个新增的token没有语义信息(即在句子中与任何的词无关,在图像中与任何的patch无关),所以不会造成上述问题,能够比较公允地反映全图的信息。
d. Transformer encoder
Transformer Encoder结构和NLP中transformer结构基本上相同,所以这里只给出其结构图,和公式化的计算过程,也是顺便用公式表达了之前所说的几个部分内容。
Transformer Encoder的结构如下图所示:
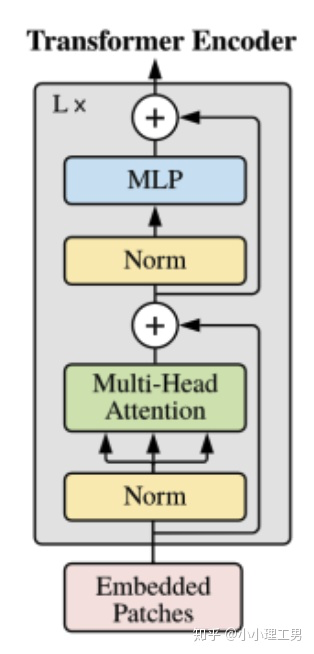
Transformer Encoder结构图
对于Encoder的第 层,记其输入为 ,输出为 ,则计算过程为:
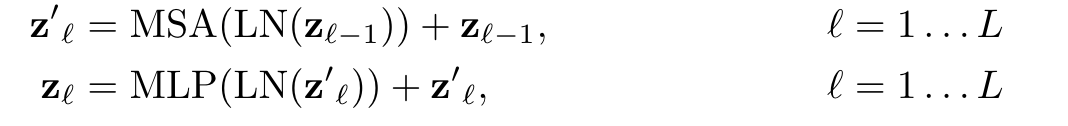
其中MSA为Multi-Head Self-Attention(即Transformer Encoder结构图中的绿色框),MLP为Multi-Layer Perceptron(即Transformer Encoder结构图中的蓝色框),LN为Layer Norm(即Transformer Encoder结构图中的黄色框)。
Encoder第一层的输入 是通过下面的公式得到的:
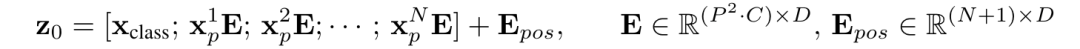
其中 即未Linear Projection后的patch embedding(都是 维),右乘 维的矩阵 表示Linear Projection,得到的 都是 维向量;这 个 维向量和同样是 维向量的 concat就得到了 维矩阵。加上 个 维position embedding拼成的 维矩阵 ,即得到了encoder的原始输入 。
3. 混合结构
文中还提出了一个比较有趣的解决方案,将transformer和CNN结合,即将ResNet的中间层的feature map作为transformer的输入。
和之前所说的将图片分成patch然后reshape成sequence不同的是,在这种方案中,作者直接将ResNet某一层的feature map reshape成sequence,再通过Linear Projection变为Transformer输入的维度,然后直接输入进Transformer中。
4. Fine-tuning过程中高分辨率图像的处理
在Fine-tuning到下游任务时,当图像的分辨率增大时(即图像的长和宽增大时),如果保持patch大小不变,得到的patch个数将增加(记分辨率增大后新的patch个数为 )。但是由于在pretrain时,position embedding的个数和pretrain时分割得到的patch个数(即上文中的 )相同。则多出来的 个positioin embedding在pretrain中是未定义或者无意义的。
为了解决这个问题,文章中提出用2D插值的方法,基于原图中的位置信息,将pretrain中的 个position embedding插值成 个。这样在得到 个position embedding的同时也保证了position embedding的语义信息。
5. 实验
实验部分由于涉及到的细节较多就不具体介绍了,大家如果感兴趣可以参看原文。(不得不说Google的实验能力和钞能力不是一般人能比的...)
主要的实验结论在story中就已经介绍过了,这里复制粘贴一下:在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。
比较有趣的是,作者还做了很多其他的分析来解释transfomer的合理性。大家如果感兴趣也可以参看原文,这里放几张文章中的图。


参考
1.https://openreview.net/forum?id=YicbFdNTTy
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
