
医学图像领域,是时候用视觉Transformer替代CNN了吗?
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:集智书童

1简介
在自动医学图像诊断的领域中卷积神经网络(CNN)方法已经统治了将近十年之久。最近,vision transformers(ViTs)作为CNN的一个有竞争力的替代方法出现了,它具有差不多的性能,同时还具有一些有趣的特性,同时也已经被证明对医学成像任务有益。
在这项工作中,作者探讨了是时候用基于transformer的模型了?还是应该继续使用CNN,还是可以简单地切换到transformer?
如果是,那么切换到vit进行医学影像诊断有哪些优点和缺点?作者在3种主流医学图像数据集上进行了一系列实验来考虑这些问题。
研究结果表明,虽然CNN在从头开始训练时表现更好,但在ImageNet上预训练时,使用默认超参数的vision transformer与CNN相当,而在使用自监督预训练时vision transformer则优于CNN。
2介绍
对于vision transformer来说,注意力机制提供了几个关键的优势:
它捕获了long-range relationships; 它具有通过动态进行自适应建模的能力; 它提供了一种内置的显著性,可以洞察模型关注于的是什么。
然而,有证据表明,vision transformer需要非常大的数据集才能超过CNN,ViT的性能只有在谷歌私有图像数据集JFT-300M进行预训练才能够得到体现。这个问题在医学成像领域尤其严重,因为该领域的数据集更小,往往伴有不太可靠的标签。
与ViT一样,当数据匮乏时,CNN的性能会更差。标准的解决方案是使用迁移学习:通常,模型在ImageNet等较大的数据集上进行预训练,然后使用较小的专门数据集对特定任务进行微调。
在医学领域,在ImageNet进行预训练的模型在最终表现和减少的训练时间方面都优于从零开始训练的模型。
自监督是一种处理未标记数据的学习方法,近年来受到了广泛关注。已有研究表明,在进行微调之前,在目标域进行自监督预训练可以提高CNN的性能。同时从ImageNet初始化有助于自监督CNN收敛更快,通常也具有更好的预测性能。
这些处理医学图像领域数据匮乏的技术已被证明对CNN有效,但目前尚不清楚vision transformer是否同样受益。一些研究表明,使用ImageNet进行医学图像分析的预训练CNN并不依赖于特征重用,而是由于更好的初始化和权重缩放。那么vision transformer是否能从这些技术中获益?如果可以,就没有什么能阻止vit成为医学图像的主导架构。
在这项工作中,作者探索了vit是否可以替代CNNs,同时考虑到易用性、数据集限制以及计算限制,作者着眼于“即插即用”解决方案。为此,作者在3个主流的公开数据集上进行了实验。通过这些实验发现:
在数据有限时,CNNs与ViTs在ImageNet上预训练的性能差不多; 迁移学习有利于ViTs; 当使用自监督预训练之后再用有监督的微调时,ViTs比CNNs表现更好。
这些发现表明,医学图像分析可以从CNN无缝过渡到ViTs,同时获得更好的可解释性。
3本文方法
作者研究的主题是,ViTs是否可以直接替代CNNs用于医疗诊断任务。为此,作者进行了一系列实验,在类似条件下比较ViTs和CNNs,保持超参数调优到最小。为了确保比较的公平性和可解释性,作者选择ResNet50作为CNN模型,使用 token作为ViT的DEIT-S。之所以选择这些模型,是因为它们在参数数量、内存需求和计算方面具有可比性。
如上所述,当数据不够丰富时,CNNs依赖于初始化策略来提高性能,医学图像就是如此。标准的方法是使用迁移学习(用ImageNet上预训练的权值初始化模型),并在目标域上进行微调。
因此,作者考虑3种初始化策略:
随机初始化权值 使用ImageNet预训练权值进行迁移学习 初始化后对目标数据集进行自监督预训练学习
数据增强策略:
normalization; color jitter: brightness contrast saturation hue horizontal flip vertical flip random resized crops
数据集:
APTOS 2019
在这个数据集中,任务是将糖尿病视网膜病变图像分类为疾病严重程度的5类。APTOS 2019包含3662张高分辨率视网膜图像。
ISIC 2019
这里的任务是将25333张皮肤镜图像在9种不同的皮肤病变诊断类别中进行分类。
CBIS-DDSM
该数据集包含10239张乳房x线照片,任务是检测乳房x线照片中肿块的存在。
数据集被分为train/test/valid(80/10/10),除了APTOS,由于其规模小,APTOS被分为70/15/15。所有监督训练都使用ADAM优化器,基本学习率为,warm-up周期为1000次迭代。当验证指标达到饱和时,学习率会下降10倍,直到达到最终值。重复每个实验5次,并选择每次运行中验证分数最高的checkpoint。
4实验
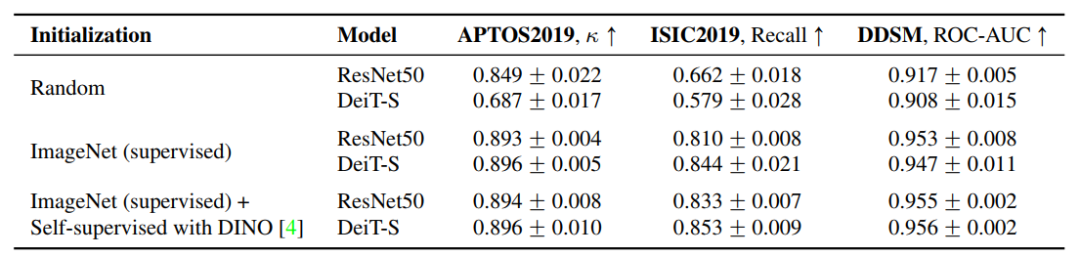
4.1 随机初始化Transformer模型是否有效?
将DEIT-S与具有随机初始化权值(Kaiming初始化)的ResNet50进行比较。在这些实验中,通过网格搜索将基础学习率设置为0.0003。
表1的结果表明,在这种设置下,CNNs在各方面都大大优于ViTs。
这些结果与之前在自然图像领域的观察结果一致,在有限的数据上训练CNNs优于ViTs,这一趋势归因于ViT缺乏归纳偏差。由于大多数医学影像数据集大小适中,随机初始化的ViTs的用处似乎有限。
4.2 ImageNet上预训练ViTs是否适用于医学图像领域?
在医学图像数据集中,随机初始化在实际应用中很少使用。标准步骤是使用ImageNet预训练网络,然后对来自目标域的数据进行微调。
在这里,作者也研究了这种方法是否可以有效地应用于ViTs。为了测试这一点,作者用在ImageNet上预训练过权重初始化所有模型。然后进行微调。表1中的结果表明,CNNs和ViTs都从ImageNet初始化中得到了显著提升。事实上,ViTs受益更多,表现与CNN相当。
这表明,当使用ImageNet初始化时,可以用普通的ViTs替换CNNs,而不会影响使用中等规模训练数据的医学成像任务的性能。
4.3 ViT是否能从医疗图像领域的自监督中获益?
表1中结果显示,ViTs和CNNs在自监督的预训练中表现得更好。在这种情况下,ViTs的表现优于CNNs,尽管差距很小。对自然图像的研究表明ViTs和CNNs将随着更多的数据增长。
5讨论
作者比较了3种初始化策略下的医学图像任务cnn和vit的性能。实验结果证实了之前的发现,并提供了新的见解。
在医学图像中,正如之前在自然图像领域所说的那样,作者发现,在低数据模式下从零开始训练时,cnn优于vit。这一趋势在所有数据集上都是一致的,并且很好地符合“Transformer缺乏归纳偏差”的论点。
令人惊讶的是,当使用监督ImageNet预训练权重初始化时,CNN和ViT性能之间的差距在医疗任务中消失了。在cnn上进行ImageNet预训练的好处是众所周知的,但出乎意料的是,ViTs的受益也如此之大。这表明,可以通过与任务更密切相关的其他领域的迁移学习获得进一步的改进,cnn的情况就是如此。
作者研究了自监督预训练对医学图像域的影响。研究结果表明,vit和cnn有微小但一致的改善。而最佳的整体性能是使用自监督+ViTs获得的。
总结发现,对于医学图像领域:
如果从零开始训练,那么在低数据下,vit比cnn更糟糕; 迁移学习在cnn和vit之间架起了桥梁;性能是相似的; 最好的表现是通过自监督预训练+微调获得的,其中ViTs比CNNs有小的优势。
6可解释性
在医学图像任务中,vit似乎可以取代cnn,还有其他选择vit而不是cnn的原因吗?
我们应该考虑可视化transformer attention maps的额外好处。transformer的自注意机制内置了一个attention maps,它提供了模型如何做出决策的新方式。
cnn自然不适合把自己的突出形象表现出来。流行的CNN可解释性方法,如类激活映射(CAM)和grada-CAM,由于池化层的存在,提供了粗糙的可视化。与CNN有限的接受域相比,transformer token提供了更精细的注意力图像,而自注意映射明确地模拟了图像中每个区域之间的交互。虽然可解释性的质量差异还有待量化,但许多人已经注意到transformer的注意力在可解释性方面所带来的质量改进。

图1中展示了来自每个数据集的示例,以及ResNet-50的grade-cam可视化和 DEIT-S CLS token的前50%自注意。注意ViTs的自注意如何提供一个清晰的、局部的注意力图,例如ISIC的皮肤病变边界的注意力,APTOS的出血和渗出物的注意力,以及CBIS-DDSM的乳腺致密区域的注意力。这种关注粒度很难通过cnn实现。