
Transformer有可能替代CNN吗?未来有哪些研究方向?听听大家都怎么说

来源:迈微AI研习社
Transformer 有可能替代 CNN 吗?现在下结论还为时过早。
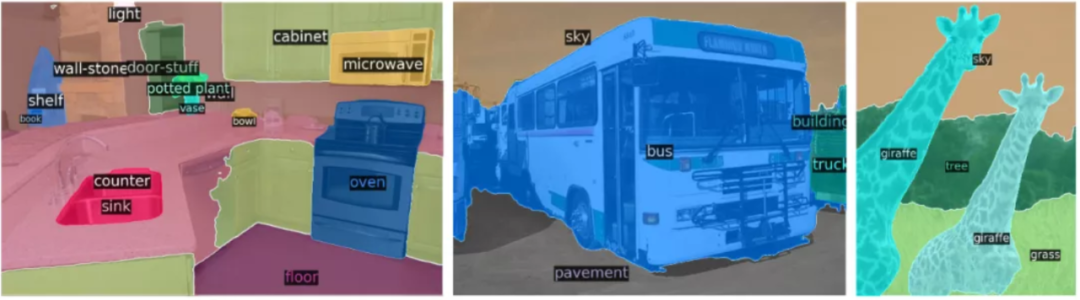

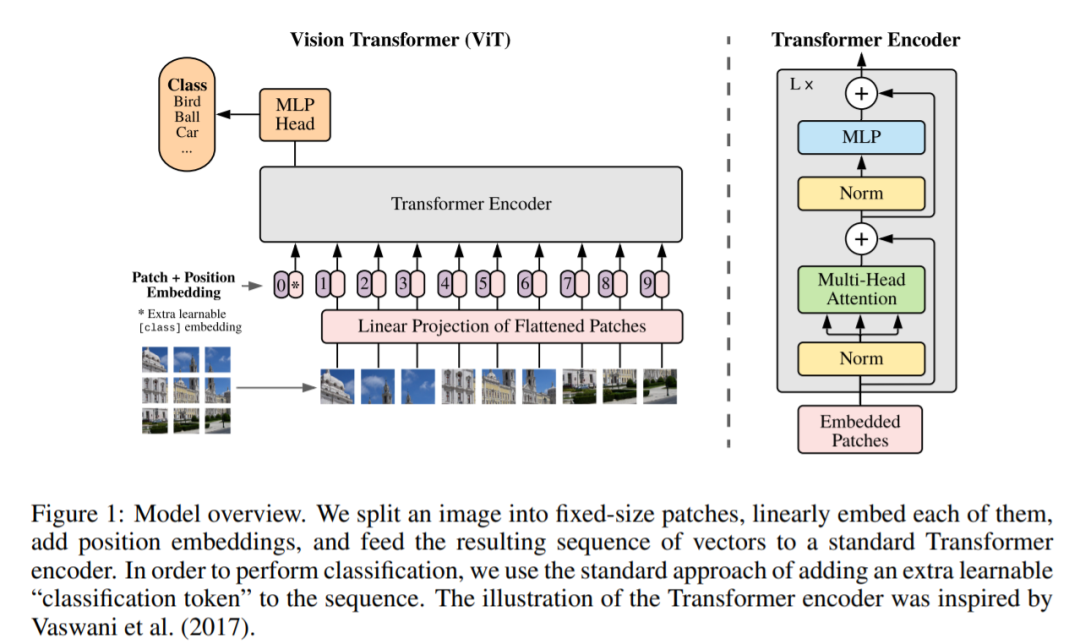
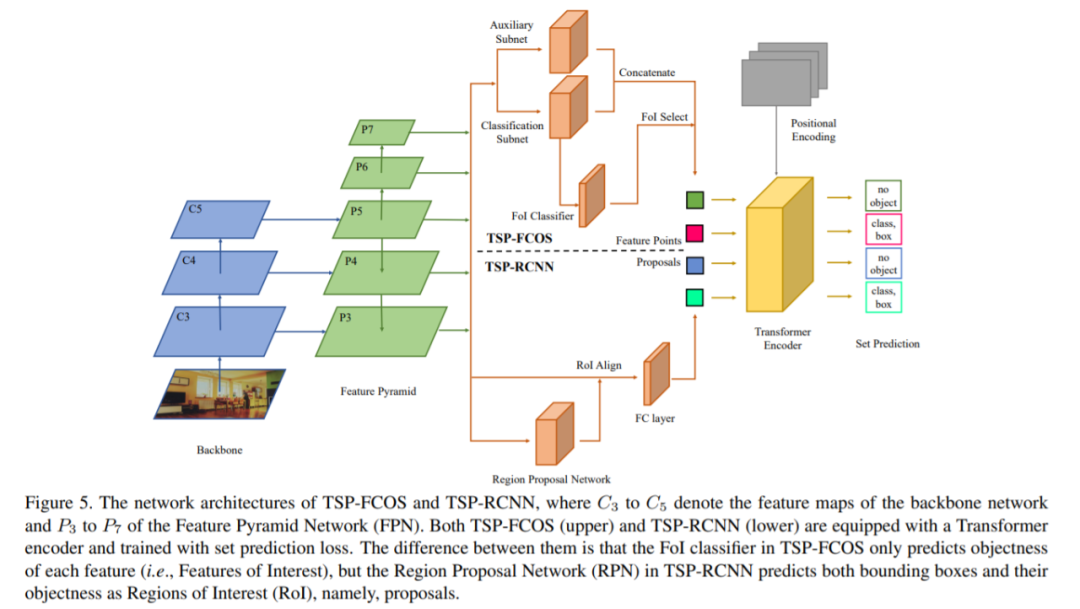
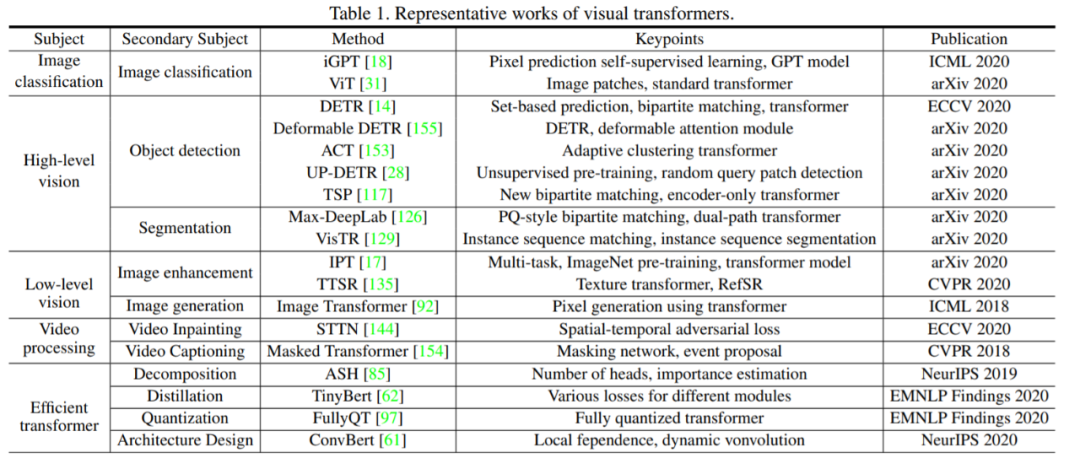
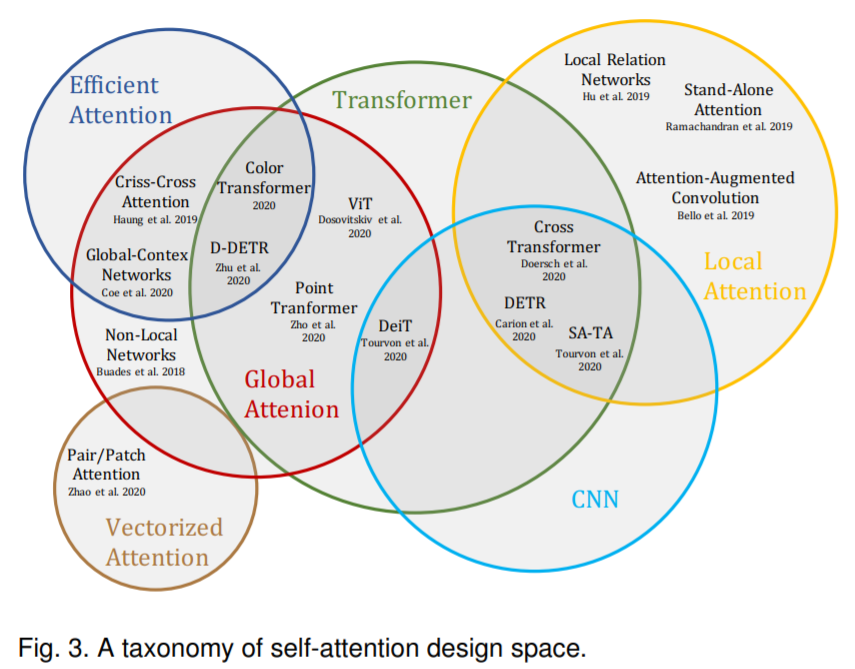
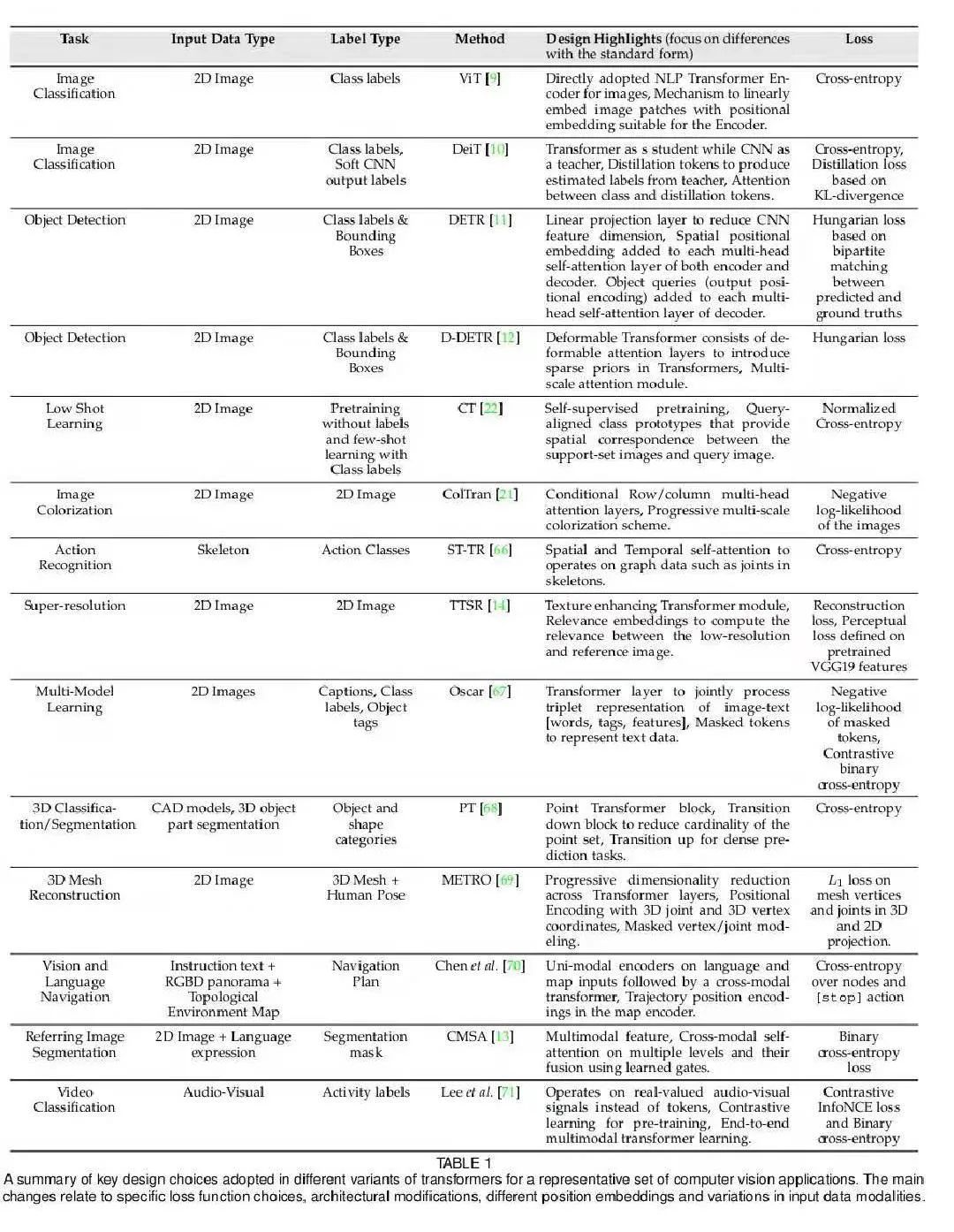
现有的 Visual Transformer 都还是将 NLP 中 Transformer 的结构套到视觉任务做了一些初步探索,未来针对 CV 的特性设计更适配视觉特性的 Transformer 将会带来更好的性能提升。
现有的 Visual Transformer 一般是一个模型做单个任务,近来有一些模型可以单模型做多任务,比如 IPT,未来是否可以有一个世界模型,处理所有任务?
现有的 Visual Transformer 参数量和计算量多大,比如 ViT 需要 18B FLOPs 在 ImageNet 达到 78% 左右 Top1,但是 CNN 模型如 GhostNet 只需 600M FLOPs 可以达到 79% 以上 Top1,所以高效 Transformer for CV 亟需开发以媲美 CNN。(引自 @kai.han)
增强推荐
(计算机视觉:实战才有效果)
我最近刚发布的一项GitHub开源《计算机视觉实战演练:算法与应用》动手学计算机视觉项目,repo中不仅有全书的电子文档,更为特别的是每章节都给出了算法简明讲解和对应代码实现。
考虑到读者各自运行环境的差异,在本书中给出的代码有两种运行方式,本地 set up 和在线colab Google notebook运行。
- 通过requirements.txt将所需版本软件安装,可在code/文件夹下运行各章节代码;
- 通过colab免费的在线gpu资源,也提供了对应章节的notebook运行代码,“傻瓜式”运行,查看代码执行过程和最终结果。

个人认为计算机视觉或者算法工程师,本质上还是一名软件工程师,所以工程实战性能力在实际项目中显得尤为重要。与此同时,对于刚入门或者初学者来讲,自己亲自动手实践,编写、调试代码,最终看到理想的结果显示出来,这是一种很好的激励和增强学习动力的方式,这也是我在编写这份资料时的初心。
与现有市场上同类书籍的差别,更在于,全书分为基础理论篇、项目实战篇、进阶篇撰写,各自章节既相互独立,又保持上下文衔接。
这样的做法,可以帮助读者更好的选取适合自己的学习方式。
- 对于初学者来说,可以按照本书的编写顺序逐章阅读并动手实践;
- 对于有一定基础的读者来讲,本书更好的食用方式是当作一本实践手册,根据自己所需相关内容,选择对应章节进行学习。
随着近年来算法届,更为突出的是计算机视觉领域在学界和工业界的热潮,不断涌现出一些性能更好的模型和算法。在本书中,作者也尽自己所能,对新出现的并且在工程上或学术界得到良好反馈的模型进行讲解,尽可能给出其模型的最简代码实现,例如:跨界模型transformer、差分自编码器vac、生成对抗模型、注意力机制等方法。


更多细节可参考GitHub全书,https://github.com/Charmve/computer-vision-in-action

