
预训练卷积超越预训练Transformer?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
来源|知乎 作者|DengBoCong
链接|https://zhuanlan.zhihu.com/p/380195756

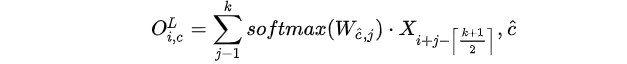
 ,也就是说每个
,也就是说每个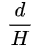 的输出通道共享参数,其中
的输出通道共享参数,其中 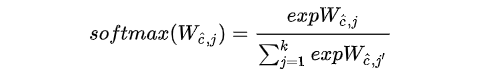
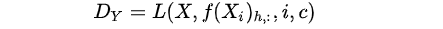
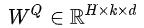 。通过这种方式,使得卷积核
。通过这种方式,使得卷积核 We implement a Seq2Seq (Sutskever et al., 2014) architecture similar to (Wu et al., 2019). The key difference when compared with Transformer architectures is that we replace the multi-headed selfattention with convolutional blocks. Instead of query-key-value transforms, we use gated linear unit projections following (Wu et al., 2019).
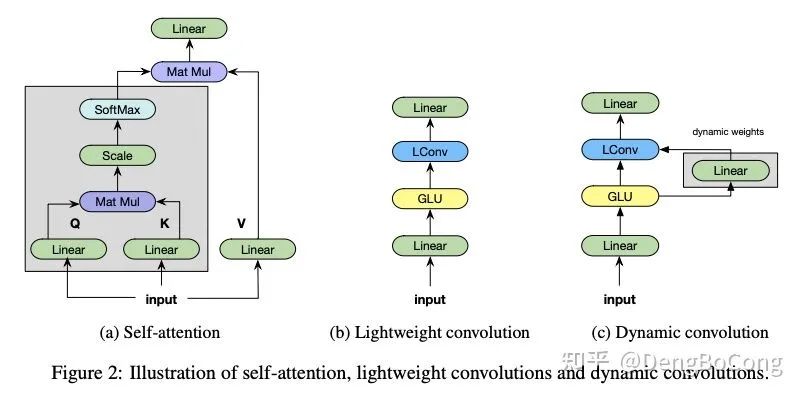
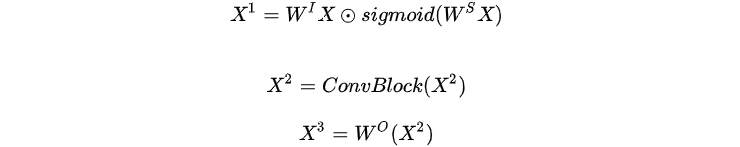
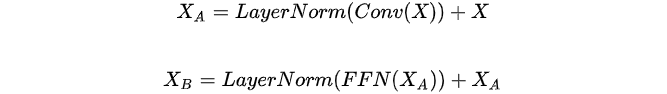

 在
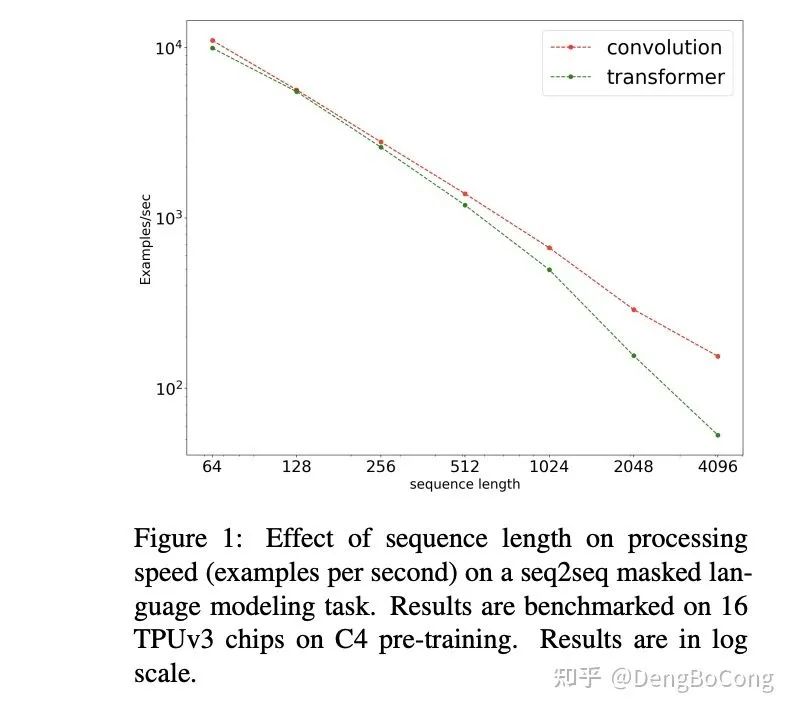
在 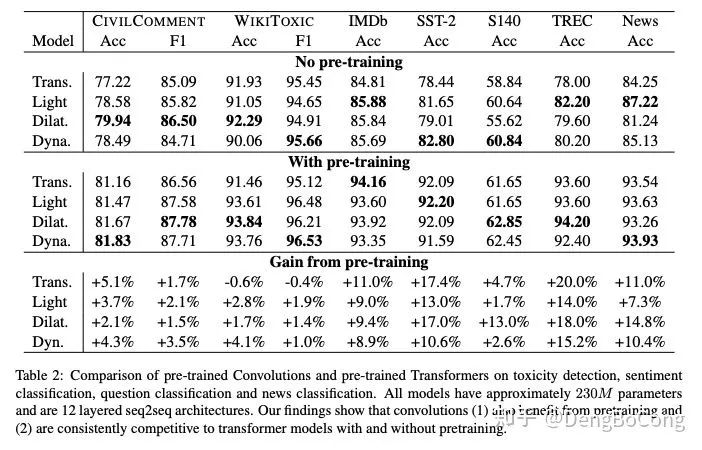
机器学习算法工程师
一个用心的公众号

评论