
如何减少噪声标签的影响?谷歌提出一种鲁棒深度学习方法MentorMix

新智元报道
新智元报道
来源:Google
编辑:雅新
【新智元导读】近日,为了更好地了解噪声标签对机器学习模型训练的影响,谷歌研究人员提出了一种简单的鲁棒学习方法MentorMix,相较于之前的方法准确性提升约3%。
在深度神经网络中,能够使用高质量标签训练数据对于学习效果至关重要,因为训练数据中存在错误标签(噪声标签)会大大降低干净测试数据上模型的准确性。
矛盾在于:一方面,若想训练更好的深度网络,大数据或海量数据是必要的。而另一方面,深度网络往往会记住噪声标签的训练数据,从而导致模型在实践中性能较差。
谷歌研究人员在ICML 2020上发表的论文为更好地了解噪声标签对机器学习模型训练的影响做出了三点探索性贡献:
1 建立了第一个受控的数据集,并确定了网络噪声标签的基准
2 提出了一种简单而高效的方法来克服合成标签和现实中的噪声标签
3 比较了各种设置下减少噪声标签的学习方法
 论文链接:https://arxiv.org/pdf/1911.09781.pdf
论文链接:https://arxiv.org/pdf/1911.09781.pdf
合成噪声标签与实际网络噪声标签的图像分布存在许多差异。
首先,带有网络标签噪声的图像在视觉或语义上倾向于与真实的正像更加一致。
其次,合成标签噪声是属于类级别(同一类中的所有示例均是噪声标签),而现实世界中的标签噪声是属于实例级(与相关类无关,某些图像比其他图像更有可能被误贴标签)。比如,当从侧面拍摄图像时,与从正面拍摄车辆时相比,本田思域和本田雅阁的图像更容易混淆。
第三,带有真实标签噪声的图像来自开放类词汇,这些词汇可能不会与特定数据集的类词汇重叠。
例如,「ladybug」的网络噪声图像就会包括诸如能够飞行一类的昆虫,以及其他未包含在所使用数据集列表中的错误。
受控噪声标签的基准将有助于更好地了解合成和实际网络噪声标签之间的差异。
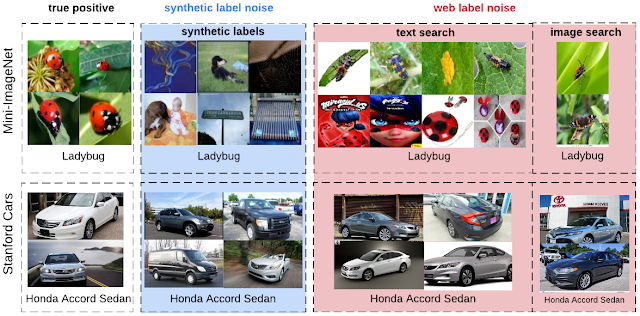 合成标签与实际网络标签噪声的比较
合成标签与实际网络标签噪声的比较
研究人员的目标是,在给定一个未知噪声比例的数据集,训练一个鲁棒的模型,该模型可以很好地推广到干净的测试数据上。
他们介绍了一种简单有效的方法来处理合成噪声标签和实际噪声标签,这一方法便是MentorMix,该方法是在「受控噪声标签网络数据集」上开发的。
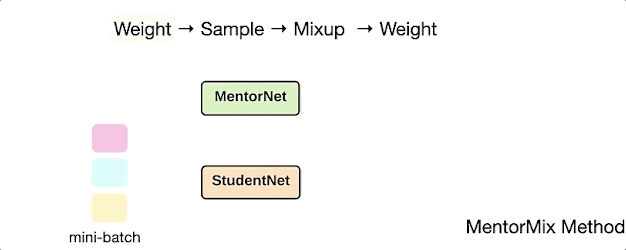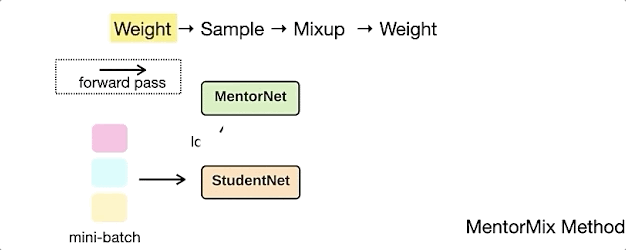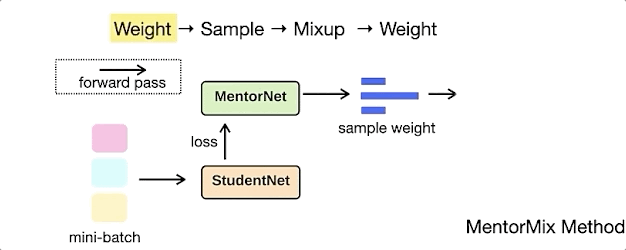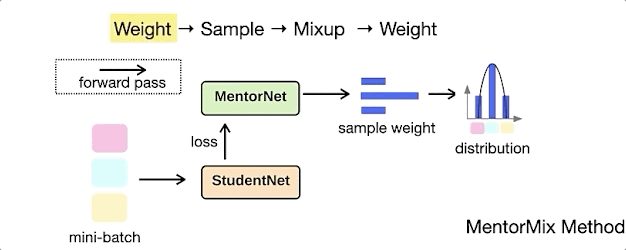
MentorMix是一种基于MentorNet和Mixup两种现有技术的迭代方法,事实证明,它对嘈杂的训练标签更具灵活性。
下面的动画演示了MentorMix中的四个关键步骤:weight、sample、mixup和weight 。
其中StudentNet是要在噪声标签数据上进行训练的模型,同时研究人员采用了非常简单的MentorNet以计算每个示例的weight。
https://github.com/google-research/google-research/tree/master/mentormix
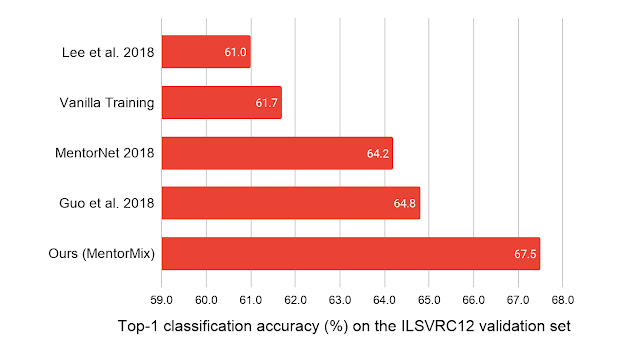
研究人员评估了MentorMix的五个数据集,包括具有合成标签噪声的CIFAR 10/100和WebVision 1.0。WebVision 1.0是一个包含有实际噪音标签的220万图像的大型数据集。
MentorMix持续在CIFAR 10/100数据集上产生改进的结果,并在WebVision数据集上获得最佳的发布结果,就ImageNet ILSVRC12验证集的top-1分类准确性而言,将以前的最佳方法提高了约3%。
最后,研究人员提出了三个有关网络标签噪声的新发现:
1 深度神经网络可以更好地概括网络标签噪声
2 接受网络标签噪声训练后,深度神经网络可能不会先学习模式
第一作者蒋路现任谷歌高级科学家
这篇发表在ICML 2020上的论文的第一作者蒋路(Lu Jiang)目前是Google Research的资深研究科学家。
蒋路(Lu Jiang)获得了卡内基梅隆大学获得了博士学位。他的研究领域是机器学习,计算机视觉和多媒体的跨学科领域,特别是强大的深度学习,视频理解和视觉+语言。

http://www.lujiang.info/
参考链接:
https://ai.googleblog.com/

