
一种深度学习方法---迁移学习了解下
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
作者:王抒伟
来源:机器学习算法工程师
接下来我会介绍关于迁移学习的以下内容。
它是什么?
它是如何工作的?
为什么使用它?
什么时候使用?
转移学习的方法:
训练模型;
使用预先训练的模型;
和特征提取
总结:
进一步阅读
1. 什么是迁移学习?
迁移学习:遇到一个新问题,不是从头训练一个网络模型,而是在现有的预训练模型上,再次训练或者直接使用。
因为他可以用较少的数据来训练深度神经网络,如果你数据不足,可以考虑下迁移学习。现在大多数问题通常没有数百万个标记数据点是无法训练出一个商用模型的。

如果你训练了一个简单的分类器来预测图像是否包含背包,则可以利用模型在训练中获得的“知识”(其实就是网络权重)来识别其他物体,例如太阳镜。
通过转移学习,我们基本上尝试利用在一项任务中学到的知识来提高另一项任务的泛化性。可以将网络从“任务A”中学到的权重迁移到新的“任务B”。
这就是迁移学习。

由于一个模型的商用需要大量的计算能力,因此迁移学习主要用于计算机视觉CV和自然语言处理任务NLP(如情感分析)中。
迁移学习不算是一种机器学习技术,但可以看作是该领域的“设计方法论”,例如主动学习。我给他起了一个名字,寄生学习。哈哈哈
2. 迁移学习如何工作的?
例如,在计算机视觉中,神经网络通常是这样的:较早的层检测到的是边缘,中间层检测到的是形状,越靠后的网络层检测的是特定于任务的特征(例如人脸中的眼睛)。
在迁移学习中,很少取最后的层,一般是取前面的和中间的层,对于最后的特征层我们自己重新训练。
例如有一个模型,可以识别图像上的背包,该背包将用于识别太阳镜。在较早的层中,该模型已学会识别物体,因此,我们将仅对后一层进行重新训练,从而学习如何把“太阳镜与其他物体区分开”。像个小孩儿一样哈哈哈。
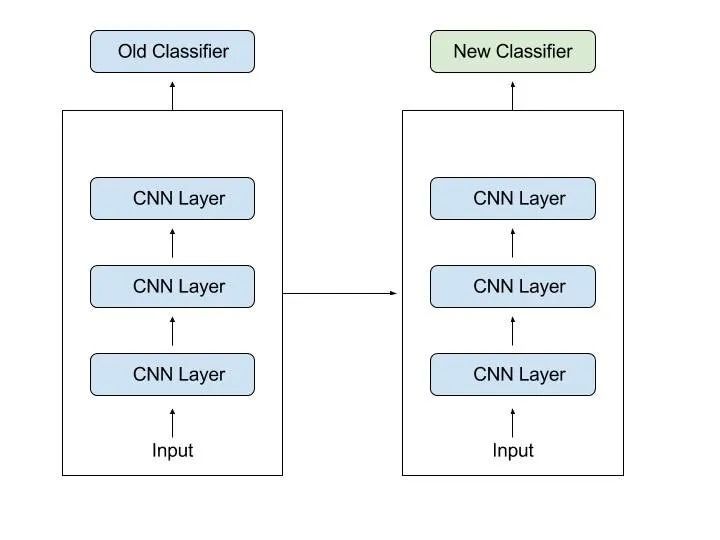
在迁移学习中,就是试着把模型训练的先前任务中的学习能力,尽可的迁移到手头的新任务。
相当于把别人的脑子给自己灌进去哈哈哈。
根据问题和数据,此知识可以采用各种形式。例如,可能是模型的构成方式,这样可以更轻松地识别新的对象,相当于获取最新的能力。
3. 为啥要用这个方法?
迁移学习有很多好处,但是主要优点是节省训练时间,神经网络的性能更好(在大多数情况下)以及不需要大量数据。
通常,从头开始训练神经网络需要大量数据,但同样的数据你可能拿不到啊,现在就是转移学习大显神威的时候了。
通过迁移学习,可以使用相对较少的训练数据来构建可靠的机器学习模型,因为该模型已经过预训练。
这在自然语言处理中特别有价值,因为创建大型的标记数据集通常需要专业知识。此外,减少了训练时间,因为有时可能需要几天甚至几周的时间来从头开始训练复杂任务的深度神经网络。
根据DeepMind首席执行官Demis Hassabis的说法,迁移学习也是最有前途的技术之一,有朝一日可能会导致人工智能(AGI):

4. 何时使用转移学习?
与机器学习一样,很难形成通用的规则,但是以下是什么时候可以使用转移学习的一些准则:
没有足够的标签训练数据来从头开始训练您的网络。
已经存在一个预先训练过类似任务的网络,通常会对大量数据进行训练。
当任务1和任务2具有相同的输入时。
如果原始模型是使用TensorFlow训练的,则只需还原它并为任务重新训练一些网络层即可。
但是请记住,只有在从第一个任务中学到的功能是通用的情况下,迁移学习才会有用,也就是迁移到类似的任务才行。
同样,模型的输入必须与最初训练时使用的大小相同。如果没有,添加一个预处理步骤就行了,把输入的大小调整为所需的大小。
5. 转移学习的方法
1.训练模型以重用它
假设您要解决任务A,但没有足够的数据来训练深度神经网络。解决此问题的一种方法是找到具有大量数据的相关任务B。在任务B上训练深度神经网络,并将模型用作解决任务A的起点。
那是否需要使用整个模型还是仅需使用几层模型,在很大程度上取决于你要解决的问题。
如果两个任务的输入都相同,则可以重新使用模型并为新输入进行预测。或者,更改和重新训练不同的特定于任务的层和输出层也可以。
2.使用预先训练的模型
第二种方法是使用已经预先训练的模型。这些模型很多,最好先做些工作。重复用多少层以及重新训练多少层取决于你要解决的问题。
例如,Keras提供了九种预训练模型,可用于迁移学习,预测,特征提取和微调。
你可以在此处找到这些模型,以及一些有关如何使用它们的简短教程 ,也有许多研究机构开源了训练好的模型。
这种类型的迁移学习是整个深度学习中最常用的方法。
3.特征提取
另一种方法是使用深度学习来发现问题的最优特征,这意味着找到最重要的特征。这种方法也称为表示学习,与手工设计的表示相比,通常可以产生更好的结果。
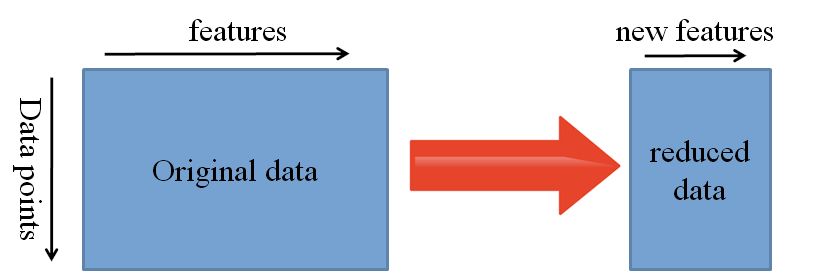
在机器学习中,一些函数通常是由研究人员和领域专家手动设计的。但是深度学习可以自动提取特征。
当然,这并不意味着特征工程和相关领域知识不再重要, 仍然必须决定将哪些函数放入网络。
也就是说,神经网络能够了解哪些特征真正重要,哪些特征不重要。表示学习算法可以在非常短的时间内发现功能的良好组合,即使是复杂的任务,否则这些工作都要耗费大量的人工。
然后,学习到的表示也可以用于其他问题。将数据镶入网络并使用中间层之一作为输出层。然后可以将此层解释为原始数据的表示。
这种方法主要用于计算机视觉,因为它可以减小数据集的大小,从而减少计算时间,并且也更适合于传统算法。
6. 热门的预训练模型
有一些非常流行的经过预训练的机器学习模型。其中之一是Inception-v3模型,该模型已针对ImageNet “大型视觉识别挑战赛” 进行了训练 。在这一挑战中,参与者必须将图像分为 1,000类, 例如“斑马”,“斑点狗”和“洗碗机”。
这是 TensorFlow上非常好的教程,介绍了如何重新训练图像分类器。
其他颇受欢迎的模型是ResNet和AlexNet。你可以访问这个,这是一个经过分类且可搜索的经过预编译的深度学习模型的汇总,有演示和代码。
译
本文仅做学术分享,如有侵权,请联系删文。