
深度学习中的噪声数据
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:蒋路
来源:https://www.zhihu.com/people/roadjiang/posts
孔子云:“性能不够,数据来凑”。可是如果数据中有噪声标签(Noisy Labels)怎么办?本文借鉴Google AI的最新工作[1]来回答这个问题。
以下我们尽量避免使用专业术语,希望对非专业的读者也会有所帮助。
深度神经网络的成功依赖于高质量标记的训练数据。训练数据中存在标记错误(标记噪声,即Noisy Labels)会大大降低[2]模型在干净测试数据上的准确性[3]。不幸的是,大型数据集几乎总是包含带有不正确或不准确的标签。这导致了一个悖论:一方面,大型数据集对于深度网络的训练是非常必要的,而另一方面,深度网络往往会记住训练标签噪声,从而在实践中导致较差的模型性能。
学界已经意识到这个问题的重要性,一直在试图理解理解标签噪声,和发明新的鲁棒学习方法来克服它们。在这个过程中,受控实验[4]扮演着至关重要的角色。好比研发一种新的药物,我们需要受控实验来对影响实验结果的无关因素加以控制。在本问题里,最重要的是研究不同的噪声水平(即数据集中带有错误标签的样本的百分比)对模型性能的影响。但是,当前的受控实验仅局限在人工合成噪声,而不是真实的噪声。与实际经验相比,人工合成噪音会导致研究结果大相径庭。来看一个例子:“神经网络是否对于人工噪音数据敏感?”,前人给出了截然相反的答案:
”Deep neural networks easily fit random labels” (Zhang et al. 2017)
VS[1]
“Deep learning is robust to massive label noise” (Rolnick et al. 2017)
更重要的是,我们发现:在人工噪声上表现良好的方法,在现实世界的噪声数据集上效果可能并不理想。
在ICML 2020上发布的“Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels”中,我们做出了三点贡献。首先,我们建立了第一个受控的噪声数据集,一个来自真实世界的标签噪声(即Web标签噪声)[2]。其次,我们提出了一种简单而有效的方法来克服真实和人工行合成的噪声标签。最后,我们进行了迄今为止最大的实验,比较了人工和真实噪声在各种训练环境下的区别。
人工合成标签噪声与真实标签噪声的区别:
人工噪声与真实标签噪声的分布之间存在许多差异,以图像举例:
首先,带有真实标签噪声的图像在视觉或语义上与干净的正样本更加一致。
其次,人工标签噪声处于类级别(即同一类中的所有样本均同样嘈杂),而现实世界中的标签噪声处于实例级(与相关类无关,某些图片会比其他图片更有可能被错误标注)。例如,“本田思域”和“本田雅阁”的侧面图片会比正面拍摄的图片更容易混淆。
第三,带有真实标签噪声的图像来自开放的词汇,这些词汇可能不会与特定数据集的类词汇重叠。例如,“ ladybug”的噪声图像包括诸如“ fly”之类的图片,然而”fly"很可能是一个background class,也就是并不是我们训练集合定义的class的一部分。
基于以上原因,一个受控标签噪声的数据集将有助于更好地定量研究人工合成和实际标签噪声之间的差异。
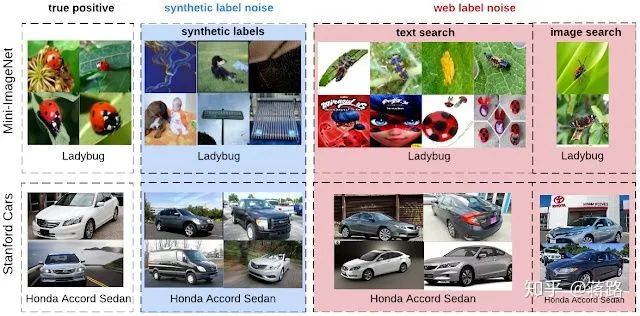
人工合成标签噪音和Web标签噪音的比较。从左到右的列是Mini-ImageNet或Stanford Cars数据集中的真实睁眼本,带有人工合噪声的图像,以及带有错误Web标签的图像(在本文中收集)。
为了区分,我们用红色噪声来指代Web标签噪声,而用蓝色噪声来指代人工合成标签噪声 (见黑客帝国中的红色和蓝色药丸)
Web上受控标签噪声

“如果选择蓝色药丸– 故事就此结束,你在自己床上醒来,继续相信你愿意相信的一切。如果你吃下红色药丸– 你将留在奇境,我会让你看看兔子洞究竟有多深。” (黑客帝国 1999)
我们提出的Web噪声数据集合建立在两个公共数据集上:Mini-ImageNet(用于粗粒度图像分类)和Stanford Cars(用于细粒度图像分类)。遵循人工合成数据集的构建方法,我们逐渐将这些数据集中的干净图像替换为从网络上收集的标签错误的图像。
为此,我们使用类名(例如“ ladybug”)作为关键字从网络上收集图像,这是一种自动方法来收集Web上带有噪声标签的图像,完全无需人工注释。然后,我们使用Google Cloud Labeling Service的标注人员检查每个检索到的图像,这些标注人员将识别给定的Web标签是否正确。我们使用带有错误标签的Web图像来替换原始Mini-ImageNet和Stanford Cars数据集中的一定比例的干净训练图像。我们创建了10个不同的数据集,它们的标签噪声逐渐升高(从0%的完全干净数据,到80%的带有错误标签的数据)。数据集已在我们的“ 受控噪声网络标签”网站上开源。
MentorMix:一种简单的鲁棒学习方法
给定一个含有未知噪声的数据集,我们的目标是训练一个鲁棒的模型,该模型可以很好地推广到干净的测试数据上。我们介绍了一种简单有效的方法来处理噪声标签,称为MentorMix,该方法是在本文提出的数据集上开发得到的。
MentorMix是一种基于MentorNet和Mixup两种现有技术的迭代方法,包括四个步骤:加权,抽样,混合和再加权。第一步,通过MentorNet网络在mini-batch中为每个样本计算权重,并将权重normalize为分布。在此处的示例中,MentorNet使用StudentNet训练loss来确定分布中的权重。
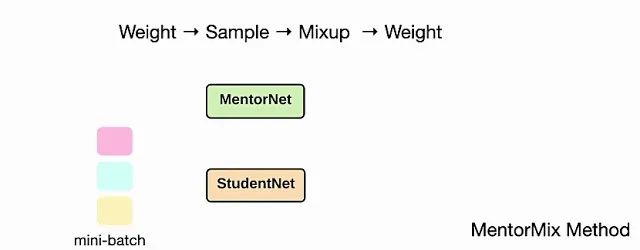
MentorMix方法的四个步骤的图示:加权,采样,混合和再加权。
接下来,对于每个样本,我们使用重要性采样根据分布在同一个mini-batch中选择另一个样本。由于权重较高的样本往往带有正确的标签,因此在采样过程中会受到青睐。然后,我们使用Mixup混合原始样本和采样得到的样本,以便模型在两者之间进行插值,并避免过度拟合噪声。最后,我们可以为混合的样本计算一个新的权重,来计算最终的example loss。对于高噪声水平,上述二次加权的影响变得更加明显。
上面的动画演示了MentorMix中的四个关键步骤,其中StudentNet是要在噪声标签数据上进行训练的模型。正如Jiang等人所述,我们采用了非常简单的MentorNet版本,以计算每个样本的权重。
模型性能
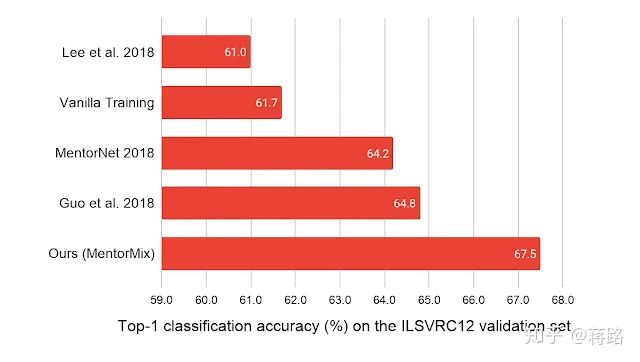
我们在五个数据集上验证了MentorMix的有效性。其中WebVision 1.0是一个包含有现实噪声标签的220万张图像的大型数据集。MentorMix在WebVision数据集上获得最佳的结果,就ImageNet ILSVRC12验证集的top-1分类准确性而言,将以前的最佳方法提高了约3%。
Web噪声标签的新发现
这项工作代表了迄今为止最大的研究,目的是了解在噪声标签上训练的深度神经网络。我们提出了三个有关Web标签噪声的新发现:
深度神经网络可以更好地泛化在Web标签噪声
在神经网络标签噪声上,深度神经网络可能不会率先学习模式 (Learning the early patterns first)
当神经网络在噪声数据上微调时,更先进的ImageNet架构会在带有噪声的训练数据集上表现的更好。
基于我们的发现,我们有以下针对在噪声数据上训练深度神经网络的实用建议:
处理噪声标签的一种简单方法是fine-tune在干净的数据集(如ImageNet)上预训练的模型。预训练的模型越好,则可以更好地推广到下游含有噪声的训练任务上。
提前停止 (Early Stopping)可能对网络上的实际的标签噪音无效。
在人工噪声上表现良好的方法,在现实世界的噪声数据集上效果可能并不理想
Web标签噪声似乎危害较小,但是对于我们当前的robust Learning的学习方法而言,解决起来却更加困难。这个发现鼓励更多的未来研究。
建议的MentorMix可以更好地克服人工合成和现实噪音标签。
MentorMix的代码可在GitHub上获得,数据集在我们的数据集网站上。
GitHub:https://github.com/google-research/google-research/tree/master/mentormix数据集:https://google.github.io/controlled-noisy-web-labels/index.html
更多资源:
http://www.lujiang.info/cnlw.html
参考
^这两种观点或许都是对的。不同的结论来自于不同的人工噪声设置。
^以下我们以来自网络的噪声标签来举例说明真实标签噪声。虽然真实噪声不仅包含网络标签,然而网络标签是最常见的一种真实噪声。
https://ai.googleblog.com/2020/08/understanding-deep-learning-on.html
https://openreview.net/forum?id=Sy8gdB9xx¬eId=Sy8gdB9xx
https://openreview.net/forum?id=Sy8gdB9xx¬eId=Sy8gdB9xx
https://link.zhihu.com/?target=https%3A//en.wikipedia.org/wiki/Scientific_control
下载1:动手学深度学习
在「AI算法与图像处理」公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
