
数据可视化|用堆叠条形图进行对比分析

作者:林骥
来源:林骥
01
你好,我是林骥。
堆叠条形图,用于展示不同类别之间占比数据,常常能起到很好的对比效果。
比如说,对某产品的不同功能进行用户调查,让 100 个用户分别按 1 ~ 5 分进行评分,经过统计,得到每个功能对应评分的人数占比如下:
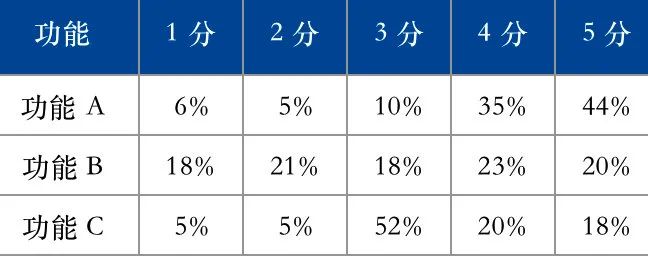
对这组数据进行对比分析,我们可以把它做成一张堆叠条形图,效果如下:
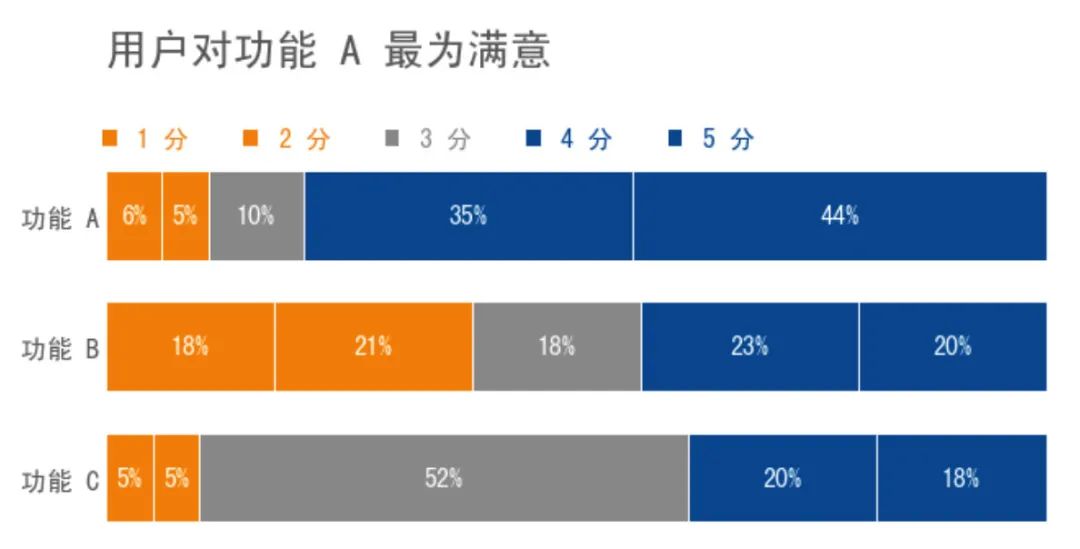
细心的读者可能会发现,这张图中有一些刻意的设计,例如 1 分和 2 分的条形颜色一样,4 分和 5 分 的条形颜色也一样,因为这里想要让「好评」与「差评」之间的对比更加强烈,让观众一眼就能看出,用户对功能 A 的满意度最高,对功能 B 很不满意。
与普通的条形图相比,这张图还有其他一些细节的改进,在此不再一一赘述,建议读者自己去领会。
数据可视化所做的工作,就是把数据背后的「故事」放进图表中展现出来,起到高效传递信息的作用。
一个成功的数据可视化作品,不在于有多复杂的图形,也不在于有多华丽的外表,而在于其背后生动的故事。
02
下面是具体的实现方法。
首先,导入所需的库,并设置中文字体和定义颜色等。
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from datetime import timedelta
# 正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 自动适应布局
mpl.rcParams.update({'figure.autolayout': True})
# 正常显示负号
mpl.rcParams['axes.unicode_minus'] = False
# 定义颜色,主色:蓝色,辅助色:灰色,互补色:橙色
c = {'蓝色':'#00589F', '深蓝色':'#003867', '浅蓝色':'#5D9BCF',
'灰色':'#999999', '深灰色':'#666666', '浅灰色':'#CCCCCC',
'橙色':'#F68F00', '深橙色':'#A05D00', '浅橙色':'#FBC171'}
其次,从 Excel 文件中读取随机模拟的数据,并定义画图用的数据。
# 数据源路径
filepath='./data/用户评分占比2.xlsx'
# 读取 Excel文件
df = pd.read_excel(filepath, index_col='功能')
# 定义画图用的数据
category_names = df.columns
labels = df.index
data = df.values
data_cum = data.cumsum(axis=1)
接下来,开始用「面向对象」的方法进行画图。
# 使用「面向对象」的方法画图,定义图片的大小
fig, ax=plt.subplots(figsize=(9, 5))
# 设置标题
ax.set_title('\n用户对功能 A 最为满意\n\n', fontsize=26, loc='left', color=c['深灰色'])
# 倒转 Y 轴,让第一个功能排在最上面
ax.invert_yaxis()
# 隐藏 X 轴
ax.xaxis.set_visible(False)
# 设置 X 轴的范围
ax.set_xlim(0, np.sum(data, axis=1).max())
# 定义颜色
category_colors = [c['橙色'], c['橙色'], c['灰色'], c['蓝色'], c['蓝色']]
# 画堆叠水平条形图
for i, (colname, color) in enumerate(zip(category_names, category_colors)):
widths = data[:, i]
starts = data_cum[:, i] - widths
ax.barh(labels, widths, left=starts, height=0.68, label=colname, color=color, edgecolor='w')
xcenters = starts + widths / 2
# 设置数据标签及其文字颜色
text_color = 'w'
for y, (x, d) in enumerate(zip(xcenters, widths)):
ax.text(x, y, '{:.0%}'.format(d), ha='center', va='center', color=text_color, fontsize=16)
# 显示图例
l = ax.legend(ncol=len(category_names), bbox_to_anchor=(-0.03, 0.95),loc='lower left',
fontsize=16, frameon=False, handlelength=0.6)
#设置图例中文本的颜色
for i, text in zip(np.arange(len(l.get_texts())), l.get_texts()):
if i < 2:
text.set_color(c['橙色'])
elif i < 3:
text.set_color(c['灰色'])
else:
text.set_color(c['蓝色'])
# 隐藏边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
# 隐藏 Y 轴的刻度线
ax.tick_params(axis='y', which='major', length=0)
# 设置坐标标签字体大小和颜色
ax.tick_params(labelsize=16, colors=c['深灰色'])
plt.show()
你可以前往 https://github.com/linjiwx/mp 下载画图用的数据和完整代码。
03
常见的数据可视化元素包括:坐标位置、长度或高度、角度、面积、颜色变化等,不同元素表达数据的精确度也是不一样的。
比如说,人们对坐标位置的变化比较敏感,但是很难从颜色变化中分辨出数据差异的大小。

精心制作一个合适的图表,至少有以下 3 个好处:
(1)传递有效信息,提高沟通的精准度。
(2)获得专业信任,提高数据的可信度。
(3)塑造职业形象,提升职场的竞争力。
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
● 华农兄弟、徐大Sao&李子柒?谁才是B站美食区的最强王者?
● 你相信逛B站也能学编程吗