地址:https://zhuanlan.zhihu.com/p/375188828深度强化学习(Deep RL)可以通过序列决策式的方式,在很多方面得到应用。这里我们主要介绍一篇CVPR'21使用RL做点云图像配准的文章:ReAgent: Point Cloud Registration using Imitation and Reinforcement Learninghttps://arxiv.org/abs/2103.15231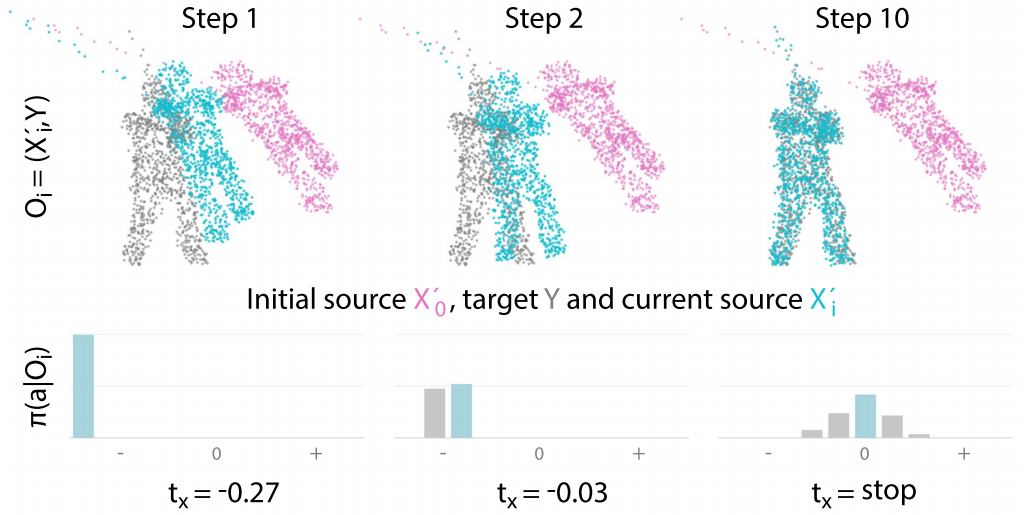
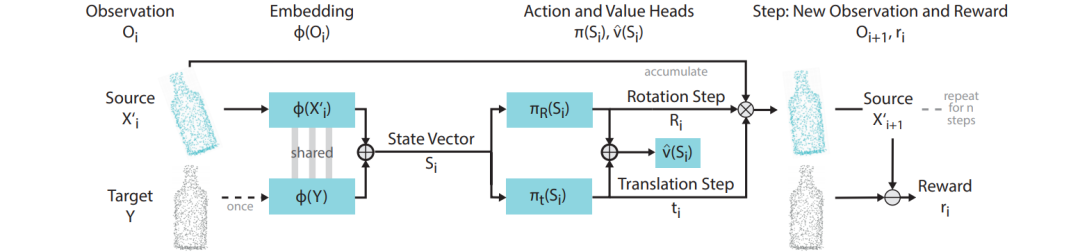
总体上而言,ReAgent是通过训练了一个Policy网络,状态是Source点云和Target点云,输出一系列动作(旋转、平移Source点云),使得Source点云最终和Target点云在相同的地方重合。
那么我们现在深入其中的细节,其实针对RL的应用文章,最需要关注的点是以下4个方面:一般来说RL的应用文章在算法上无非使用的是较为广泛使用的算法模型,如DQN、PPO、SAC等。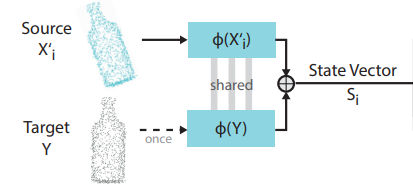
这里的State是将Source和Targe点云通过一个PointNet类似的结构,从高维点云信息Embedding到一个特征空间后,两者Concatenate得到State的表征信息。这里从上图中可以比较好的理解。
这里Action的选择就比较直观,我们需要通过一些操作来旋转、平移Source点云。那么Action就直接设置为旋转、平移相关的动作。这篇文章在实现上,使用离散的动作集,比如x方向的平移为[0.0033,0.01,0.03,0.09,0.27],当然是有正有负。
Reward的设计就更为直观,就是在执行动作后,看是否Source和Target之间更加接近了。这里使用的是Chamfer Distance(CD)来衡量,下面给出Reward的设计:
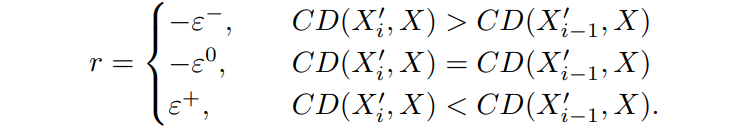
这里的Reward也很直观,就是加入执行动作之后,是否变得更好?如果变好了就给一个正的奖励,如果变差了就给一个负的奖励。
如果理解了这个问题中的State、Action的设计,还是相当直观的框架。同时笔者也跑通了ReAgent的代码,实际看下其效果如何,主要是观察其序列动作过程:
可以看到ReAgent的动作还是相当“丝滑“”且准确的。也希望更多的读者能够探索RL的各种应用,做到像人一样“丝滑”~—版权声明—
来源:知乎—东林钟声
地址:https://zhuanlan.zhihu.com/p/375188828
公众号:强化学习技术前沿
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
 下载APP
下载APP